

A couple of years ago cloud bursting was all the rage. Promising the ability to expand the capacity of your on-premise data center with the elasticity of the cloud. The idea was that you would still keep your on-prem data centers and leverage the cloud to provide additional, elastic capacity when the limits of the on-prem environment were exceeded, and then scale back down when the cloud resources weren't needed.
»Cloud Bursting
The main reason to use cloud bursting was to save money, by not having to add additional hardware in the data centers. The capacity in the data center would only need to be able to handle the average load. And cloud would give them the extra needed capacity for scaling up and down to handle any unforeseen spikes in load that might occur. Another use case for cloud bursting could include accommodating bursty workloads such as batch jobs, such as data analytics or machine learning.
Cloud bursting never delivered on its promise because of the inherent complexity that it comes with. Many of the complexities have to do with networking. This is commonly solved with either VPNs or Direct Connects, which are difficult to scale and secure.
When using VPN to connect environments, the servers act like a chokepoint, limiting bandwidth between the private datacenter and public cloud. Scaling this up adds additional complexity and problems, because you now need to handle additional routing necessary for services to reach each other between the environments. This becomes even harder when subnets overlap.
If you manage to connect all of the environments together successfully, you still need to consider the security implications. How do you control authorization and authentication? You are essentially opening up both networks to each other.
»Is Cloud Bursting Still Relevant?
But in this day and age is cloud bursting still relevant? With everything going on in the world right now, there's been a real need for internet-facing companies to suddenly scale up capacity.
You might have seen some headlines such as those about Zoom, Google Meet and Microsoft Teams having to scale up to accommodate large numbers of daily meeting participants. And with everybody stuck at home, live streaming platforms such as Twitch have seen a huge increase in concurrent viewers. Overall internet usage is up 70%, and of that usage, streaming is up more than 12%.
Being able to handle these sudden and huge increases in load is an amazing feat of engineering. The thing is though that the mentioned companies are already geared to use the best of the cloud.
But what about all the other companies that are not? These companies still have had to scale. For many organizations "use cloud" is not just a flip of a switch, but an 18 month long project that often turns into an even longer journey. How do these companies handle scaling, if they are still on-prem, or they have just started the process of migrating to cloud.
»Exploring a Common Scenario
That is the scenario that we will be exploring. We are taking a common scenario where an e-commerce website needs to scale way above its regular load. A good example of this would be Black Friday, which happens every year and each time it creates an unpredictable load for e-commerce organizations.
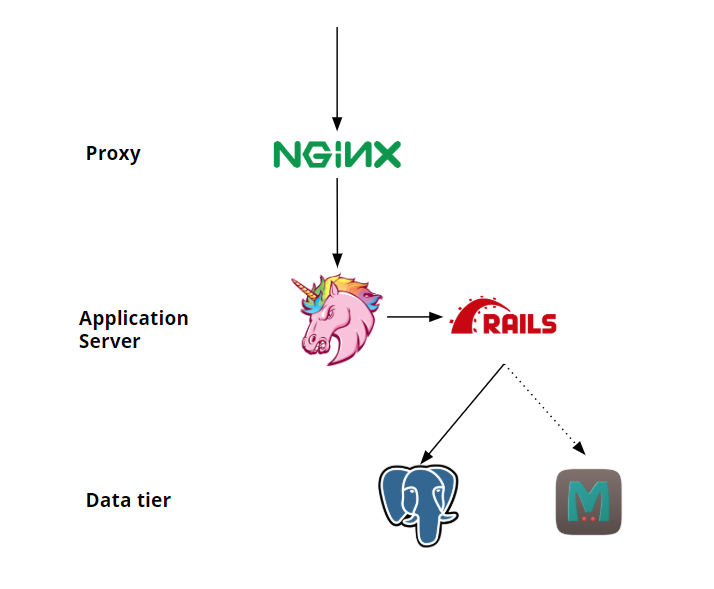
The stack will consist of a monolithic ruby application, that reads data from an SQL database, and then uses a cache to speed things up. Because the application is single-threaded, we need to use a web server that will allow the application to handle multiple concurrent requests. For this, we will be using Unicorn, but because of that, we need to add a Nginx in front of the webserver to prevent the slow-client problems that are common with unicorn.
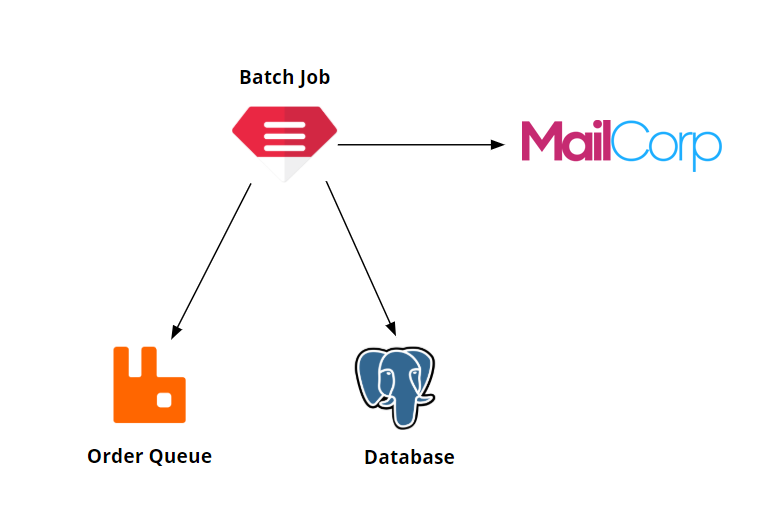
Besides serving the webshop pages so potential customers can browse our goods, we would really like them to place orders. When they do, we need to process these orders using a batch job. This will grab the orders from the order queue, process them, then call some MailCorp APIs, and finally store the results in a database.
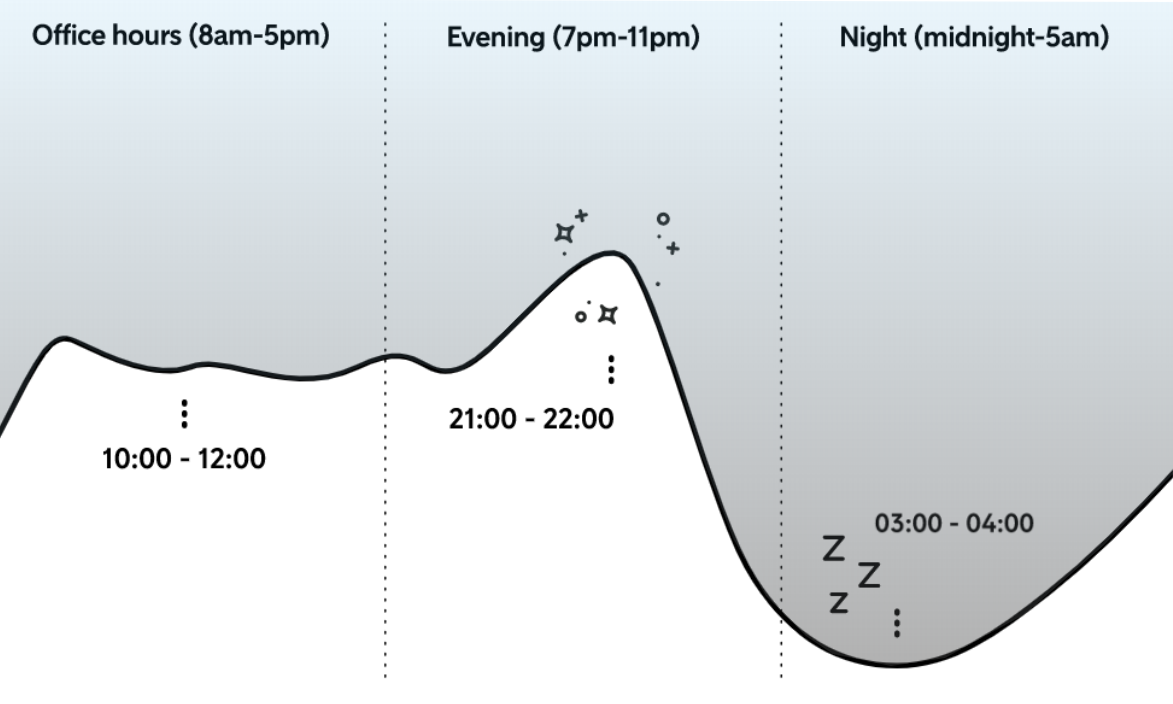
Looking at the average daily traffic, we can see a clear trend in sales, where most purchases happen during the day. Especially in the morning and in the evenings, with the nights being fairly quiet. This will be a great time to process the batch jobs.
During normal working days, the application instances can handle around 20 requests per second. We can run 10 of these instances per server, which is mostly due to memory consumption.
The problem is that we are expecting to get over 20,000 requests per second during peak times, and we only have 50 available machines in our data center. This means we have to double our machine count in order to handle this peak traffic.
We need to find a solution, because if we have an outage it will have a huge impact. Over the entire period of Black Friday the amount of sales we would miss could be huge, and make up around 10% of our annual income.
»Options
There are several options that can be used to solve this.
You could take the zero-effort approach, cross your fingers, and do nothing, but when traffic does overwhelm the application this will take down our entire datacenter. That means that there will be no sales and you'll lose out on millions in revenue.
A straightforward solution would be to build out the hardware in the data center. But this is a huge CapEx for something that will be idle 99% of the year. Buying additional hardware and paying for the extra running costs might not be the most efficient use of money.
The most obvious answer would be to just migrate to cloud. And of course that is the goal eventually, but we don't have 18 months to do this. We only have 6, so we need a solution quicker than this.
For now cloud bursting is our best bet, and then we'd eventually aim for the long-term goal of moving toward cloud. But if cloud bursting could not deliver on its promise back then, why would it be any different now?
The available infrastructure tools and services have changed significantly over the years. There are now service mesh products like HashiCorp Consul, which has features such as mesh gateways. Clouds have also improved a lot and now offer many hosted services. All these things now make it possible to securely connect on-premise and cloud environments at scale, without the complexity.
»Solution
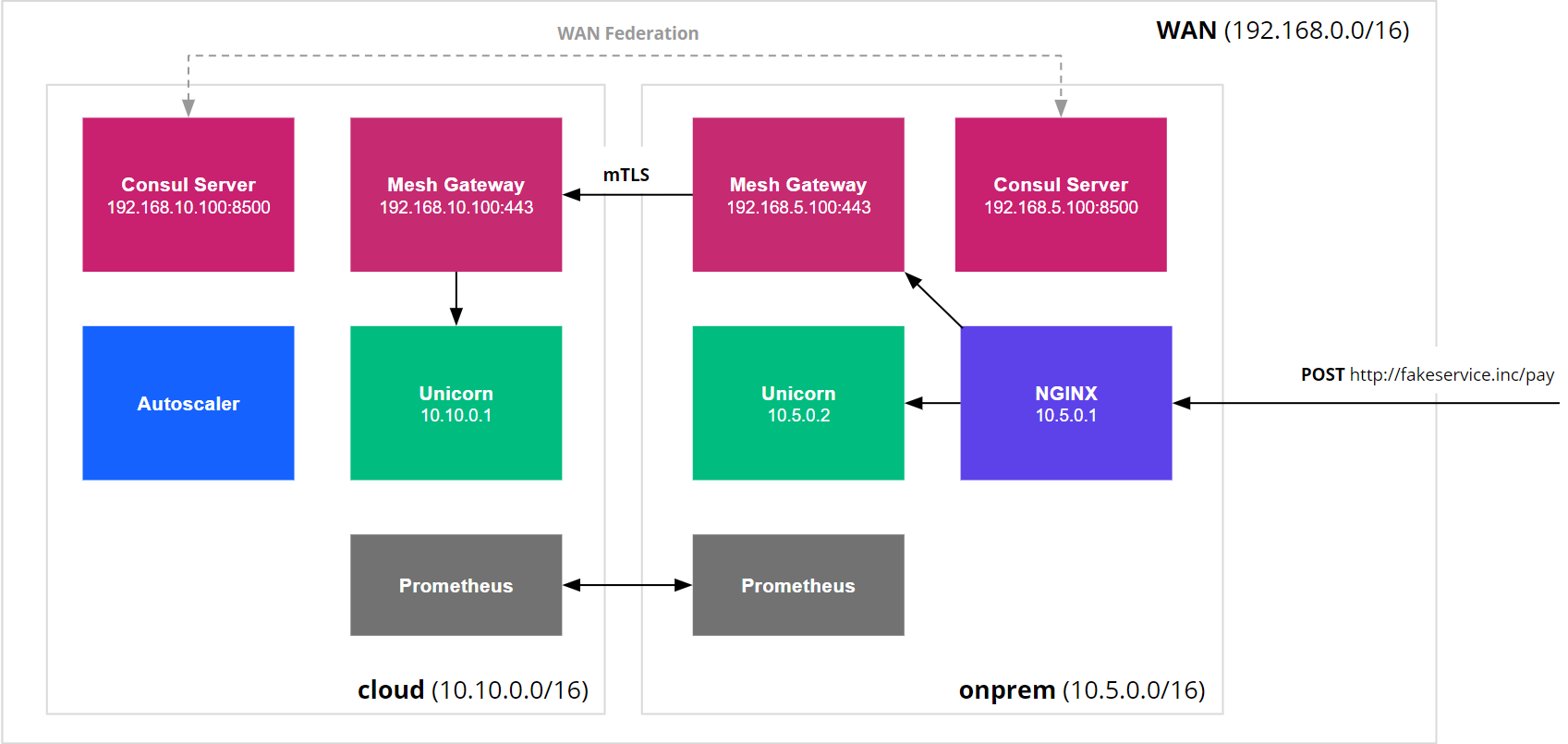
To make this work, we will federate the two data centers together using Consul and the mesh gateways, to allow for service discovery and routing traffic between them. The applications will be running on top of Nomad, both on-premise and in the cloud. This scenario would work exactly the same if we were running our applications on virtual machines. Nomad allows us to more easily scale up and down depending on the incoming traffic.
By configuring the layer 7 features of our service mesh, we can dynamically route traffic between the applications in our on-premise data center and the cloud. The Nomad autoscaler can scale our various workloads in the cloud up and down based on their respective scaling needs. The unicorn instances will be scaled up based on the average number requests sent to all unicorn instances, and the batch jobs will be scaled up to consume the headroom we have in resources that the unicorn services are not using.
»Demo
»Next steps
There are several directions we could take this setup in. We could keep operating in this way, making cloud bursting a permanent fixture of the setup. Continue to use the on-premise datacenter and use the cloud for its elasticity, fulfilling cloud bursting's initial promise.
We could make this setup even more dynamic by using the cluster scaler plugin for the Nomad autoscaler. This will make it possible to scale the Nomad client instances up and down, to dynamically create more capacity for allocations when needed. This would give even more flexibility and at the same time keep costs low.
But by creating this cloud bursting setup, we have also laid out a clear path to migrate our applications further to the cloud, by moving them over one at a time, without having to make an all or nothing switch. We can start off by moving the Nginx servers to the cloud environment and changing the service mesh configuration to reflect these changes. Then we create a cloud instance of the SQL database, replicate the data, and flip the switch, eventually being able to turn off the on-premise datacenter entirely.
If you'd like to take a look at the code used in the demo video above, visit the GitHub repository where the setup is stored.






