

The Nomad Autoscaler enables automated application and cluster scaling of your Nomad workloads and infrastructure. Adapting quickly to changes is crucial for serving users and meeting business goals and requirements. Cluster scaling can also help reduce infrastructure costs and remove the manual work that slows down your team.
In its latest release as part of the Nomad 1.1 beta, the Nomad Autoscaler brings new plugins and capabilities that aim to expand when and where autoscaling can be used, making it easier to apply it in different scenarios and use cases.
»New Plugins
The Nomad Autoscaler relies on plugins to do its work. Some plugins are pre-packaged within the Autoscaler, while others are contributed by the community and can be installed externally.
There are three types of plugins:
APM plugins query and retrieve metrics from application performance monitoring systems.
Strategy plugins calculate what changes the Autoscaler must do to meet the policy defined by operators.
Target plugins apply the changes specified by the Autoscaler into infrastructure components.
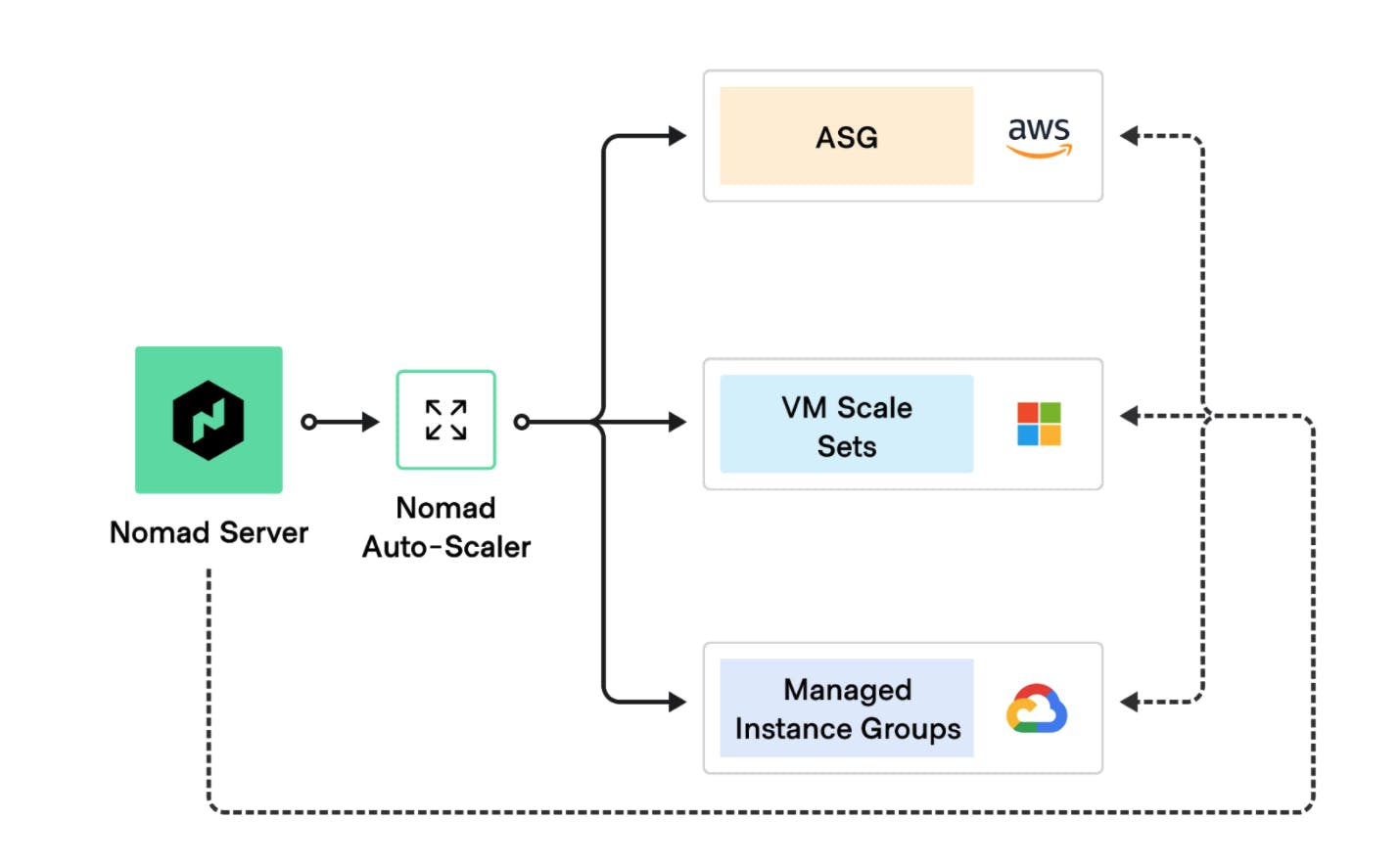
Nomad cluster autoscaling on three major clouds
Since the beginning of the year, we and our community have added several new plugins to the Nomad Autoscaler. Most notably were the community contributions for Google Cloud managed instance groups and Microsoft Azure virtual machine scale sets targets, which are built-in plugins released in v0.3.0 and v0.2.0 respectively, and external target plugins for DigitalOcean droplets and OpenStack Senlin.
The latest releases also include new strategy plugins that are better suited for situations where the existing target-value strategy is not a good fit. This makes it easier to construct and reason about scaling policies. In the next sections we will describe how these new plugins work, and when and how to use them.
»Fixed Value Strategy
This is a very simple strategy: it always returns the same predefined value set in the policy. By itself, it doesn't seem very useful, but when used with other checks within the same scaling policy it provides a simple mechanism to define a baseline for your infrastructure.
Since the value returned is always the same, it's not necessary to define the metric source and query.
job "app" {
# ...
group "webapp" {
# ...
scaling {
min = 1
max = 10
policy {
check "fixed" {
strategy "fixed-value" {
value = 4
}
}
check "dynamic" {
source = "prometheus"
query = "..."
strategy "target-value" {
target = 10
}
}
}
# ...
}
}
}
In the example above, the fixed check effectively defines that at least four allocations will be running at a given time. The dynamic check is allowed to generate other values, but if the result is below four, the fixed check will take precedence.
While this is a contrived example, future releases of the Nomad Autoscaler will include new functionalities to take full advantage of this strategy.
»Pass-Through Strategy
The pass-through strategy is also very simple in principle, but very powerful in practice. It doesn't add any extra logic on top of the metric query result, which allows for the resulting scaling action to be calculated externally. Since the change factor is already known, there is nothing more for the Autoscaler to do other than apply the desired value.
As an example, imagine a batch job that requires special hardware to run, such as a large amount of memory or expensive GPU units. In a cloud environment, where these resources can be provisioned on-demand and paid for by the hour, it is costly to keep them running when there are no jobs to process. It is also counterproductive to manually provision them when needed.
Using the new pass-through strategy it is possible to define a horizontal cluster scaling policy that creates only as many instances as there are batch jobs in-progress.
scaling "batch_processing_cluster" {
min = 0
max = 20
policy {
check "batch_jobs_in_progress" {
source = "prometheus"
# Sum the number of batch jobs that are running or pending.
query = "sum(nomad_nomad_job_summary_queued{exported_job=~\"batch/.*\"} + nomad_nomad_job_summary_running{exported_job=~\"batch/.*\"})"
strategy "pass-through" {}
}
target "aws-asg" {
aws_asg_name = "batch_clients"
node_class = "high_memory"
}
}
}
»Threshold Strategy
Using the existing target-value strategy, your infrastructure will closely match the dynamics of your metric. This can be undesirable for volatile time series, such as CPU usage, and hard to rationalize how the Nomad Autoscaler will react.
The threshold strategy allows policies to define tiers with upper and lower bound values, and what action to take when the metric crosses into one of these tiers. The type of action can be a percentage change, a value delta, or a new absolute value.
Here is a cluster scaling policy that defines what action to take based on overall cluster CPU usage.
scaling "cluster_scaling" {
min = 1
max = 10
policy {
check "high_cpu_usage" {
source = "prometheus"
query = "avg(nomad_client_host_cpu_total)"
strategy "threshold" {
# If CPU usage goes above 70%...
upper_bound = 100
lower_bound = 70
# ...add one instance.
delta = 1
}
}
check "low_cpu_usage" {
source = "prometheus"
query = "avg(nomad_client_host_cpu_total)"
strategy "threshold" {
# If CPU usage goes below 30%...
upper_bound = 30
lower_bound = 0
# ...remove one instance.
delta = 1
}
}
target "aws-asg" {
# ...
}
}
}
»Better Cluster Scale-In Control
When the Nomad Autoscaler detects that a cluster can be reduced, it performs a scale-in action to drain and decommission Nomad clients. The first releases of the Autoscaler would simply pick clients in the order returned by the Nomad API. While this works for some applications, it can be quite disruptive for others that require allocations to run to completion.
A new policy target attribute called node_selector_strategy allows changing this client selection mechanism to an option that better fits the types of workloads running in the cluster. There are four strategies to pick from:
least_busyprioritizes clients with the lowest amount of CPU and memory allocated, and it is the new default.emptyonly selects clients that have no allocations running.empty_ignore_systemis similar to theemptystrategy but ignores allocations from system jobs.newest_create_indexis the previous default behavior and uses the same ordering as returned from the Nomad API.
»New Learn Tutorials
To help demonstrate how these new features work, we released new tutorials in our HashiCorp Learn portal. Head over to the Autoscaling section to access them.
More details about the new plugins and node selector strategies can be found on our website.
»What's Next
Autoscaling is a crucial part of modern infrastructure, and it must be a fast and reliable process. For the next releases of the Nomad Autoscaler we will be focusing on production readiness, building highly anticipated features such as high-availability deployments, crash recovery, and improved visibility of what is happening with the Autoscaler.
We would like to thank our community for all the contributions, feature requests and bug reports that allowed us to reach this point. You all help us improve with each release.







