Rapid Cyber Range Development with Vault, Terraform, and Ansible
Learn how HashiCorp Terraform and Ansible can enable rapid development and deployment in a cybersecurity testing range.
Transcript
Hi, I'm Brian Marsh. I'd like to talk to you today about Terraform and Ansible and how they can enable rapid development and deployment in a cyber range.
I'm the St. Louis HashiCorp User Group organizer. I have about 15 years of experience in small and large, public and private IT shops. I cut my teeth on VMware administration but over the years have started to incorporate more configuration management, and most recently I've been doing infrastructure automation in more of a DevOps flow, leveraging the HashiCorp tooling.
A Cyber What?
What do I do? I run and support a cyber range. In a nutshell, a cyber range is like a gun range for offensive and defensive computer security professionals. It allows them to practice their craft in a safe and secured environment.
Effectively, we provide an isolated and secure education space. If you want to see how a worm behaves or how other malware behaves, the cyber range is a great place to do that, because we have isolated infrastructure. It can limit the blast radius in case something goes wrong, and it allows you the freedom to experiment.
We also offer a safe place for training and testing and experimentation. If you're trying to get certified in some security cert, you can practice in the range.
I also get to design and support infosec competitions. This is where multiple companies can come together over a very short but intensive 2-day period, where they bring their own offensive and defensive computer security professionals in a capture-the-flag, gaming points type of competition.
To do that, the range has to spin up hundreds of VMs, dozens of networks, all in an automated fashion.
The less time we spend worrying about how our infrastructure is being provisioned, the more time we can keep things exciting by injecting challenges for the contestants.
I also get to play around with new software and technology. So anything that could benefit the range or augment the existing capabilities, I can bring it in. We can spin up infrastructure, we can demo it, document it, present it to the rest of the team, and adopt it, just like that.
A Tale of a Boat
I make things, whether it's roasting coffee at home, spinning up complex infrastructure to support the range, or even building a boat. And I'm here to tell you today that building infrastructure for the range is a little like building a boat.
Let me tell you a story. In late 2017, I wanted to start a project with my dad. We coalesced around 3 goals. No. 1, we wanted something which wasn't technical but did have a slight learning curve. My dad's a retired English schoolteacher, doesn't do a whole lot with technology. I've got a lot of IT experience.
We wanted something that would challenge us both, be doable, but still give us something to be excited about.
All good projects have a deadline and ours did too. Our second goal was to be finished by summer.
Lastly, we wanted something physical that we could build in addition to the memories that we'd have for years to come. Looking online for something that would fit these criteria, I stumbled across a website where a guy was releasing plans to build boats at home out of plywood. I showed my dad, and we were like, "Yeah, let's build a boat. It's just 2 sheets of plywood. How hard can it be?"
We started the project in January of 2018 as all projects begin: with procurement, we read the plan, got everything all laid out. And things moved along pretty smoothly.
We followed the old adage of measure twice, cut once. And then we had to start over.
Here's a picture of when we joined the 2 sides together at the bow. That bow had to be at a very complex angle to dictate the shape of the boat. And we didn't have the right tooling to cut that angle, so we had to guess and try to do it, and we failed.
Unfortunately, we didn't realize our mistake until after we had permanently affixed everything. We had to throw out weeks' worth of work. All of our materials and our time, we had to bin all of it. But it's OK; we could learn from our mistakes and do better again, which we did.
We started the project again in April 2018, learning from our previous experiences, trying new things.
At this point, we realized that the plans didn't really specify everything that we needed to get the job done, so we had to experiment a little. But it seemed to be pretty successful.
My dad at one point pointed to it and said, "It's actually looking like a boat." So we were able to put the finishing touches on in June, painting, patching, assembly.
At this point we realized that our project fell victim to something I see in IT a lot. And that's where design decisions at the beginning of the project for time savings or cost savings can have unexpected negative consequences later on.
You see, when we got our plywood, we went with a lesser grade, and that meant that when it came time to do the painting, there were all these little knots and holes that needed to be filled in. We had to do little tweaks to help make sure that everything fit together and smoothed out just right.
But we were able to go ahead and do that, and launch day came, July 8, delivered on time. My wife and I deadlifted the 80-pound boat on top of our Subaru, because I don't have a hitch or a trailer, and we took it to our local lake, and it floated. Great.
Looking back at 6 months' worth of effort, there are a couple of lessons that really jumped out at us. No. 1, it took way more than 2 sheets of plywood.
Although the plan was light on details, there was a lot of stuff that just wasn't mentioned at all, from the side supports to the hardware that keeps the oars from floating away when you're in the middle of the lake, which—spoiler alert—is a very bad situation to get into.
The plan just didn't encompass it, and so we had to tack on more things as we went along.
The second lesson: Restarting is painful but very necessary. When we were looking at the work that led to our mistake, joining the sides of the bow at the wrong angle, we tried to think about whether we could salvage this. Could we cut them? Could we just go with a wider angle?
The problem is that the foundation of the design was compromised, and we had to start over to ensure a quality finish.
And I'm glad we did. It floats, but it's also pretty stable, and I think it's a good-quality product.
But that did also lead to our third lesson learned: Repetition leads to confidence, and in some cases wisdom based off of your prior experiences.
So we were able to recover from our mistake in a much faster time. We were able to look at what we had done the first time around and make decisions like, "Let's use less epoxy, so it doesn't make a mess on the garage floor."
We were also able to look forward and make educated decisions on, "Let's use cardboard to template out wood before we permanently affix it." And that saved us from pitfalls later on in the project.
Lastly, tooling is integral to a successful build. We used so many different power tools to cut angles, holes, things to apply the epoxy and paint. We probably could have got away with different tooling, but I don't know if it would have been as quality of a product.
Building Infrastructure, with Boat-Building Lessons
Earlier I said that building infrastructure for the range is a little like building a boat. If you're wondering, "But how?" let's go through the process. I think you'll find there are some similarities.
The first thing you do is you figure out the plan: gathering the requirements, waiting for teams and priorities to align. This could be waiting for the garage to get cleared out so you can stage your plywood, or it could be waiting for additional capacity to be added to a taxed compute cluster.
Once that's done, you can go ahead and try to build stuff, and you'll probably be doing manual builds. Maybe you're using cardboard templates for plywood or VM templates for OS deployments.
But unless everything is completely automated, you're going to be doing tweaks, slight changes here and there to make it all fit together and work.
The problem is, the more manual steps and the more tweaks you do, the greater chance that it's going to go wrong and you're going to have to start again, or at least try redeploying some stuff.
This process eventually results in a successful deployment, but the time to get that successful deployment is highly dependent upon your tooling and workflow.
Tooling on the Cyber Range
Let me tell you about the tooling and workflow that I use in the range. I use Terraform and Ansible, and I chose these products specifically with 1 goal in mind: I wanted to have a single 1-click deploy, with servers and software completely hands-off.
This would keep me from having do all the little tweaks and whatnot later. Terraform enables rapid spin-up and spin-down and modification of complex infrastructure. Ansible can be used to trigger configuration and deployment of software in a very iterative way.
My workflow looks something like this.
First off, I have Terraform deploy, so it will spin up VMs or single VMs or whatever in a staging environment. Infrastructure gets deployed, then it hands off to the configure stage.
This is where Ansible will leverage code from playbooks to roles to install software configure services and users.
And then I check: Did it work? No? Update my code and redeploy.
You may wonder why I don't leave the VMs alone and just iterate over the Ansible code. The reason is I wanted to make sure all those changes necessary for the Ansible code to work were recorded in the playbooks.
When I logged onto the system to see why a service wasn't starting, it was too easy to just create that user or change that folder permission and rerun.
But then I would miss all those little tweaks and little fixes to get the system to the state I wanted it to be. By forcing myself to redeploy from scratch every time, I ensured that if you have the Terraform code and you have the Ansible code, you will have a successful product delivery.
The Successes
Let's look at a few success stories.
First, we have Enterprise DB. Enterprise DB is the paid version of Postgres and offers quite a few helpful additions over the open-source variety. This is critical to the success of the range, because having a centralized, resilient database cluster offers multiple systems that we bring in and other services to have a reliable database backend.
Second one is MinIO. MinIO is a self-hosted, S3-compatible object storage platform. We could have leveraged cloud services for S3, but there are a couple of reasons why I wanted to bring this on site.
First, limiting our blast radius in case something runs amok. If it's on-prem, we don't have to worry about unexpected costs or security implications of leveraging cloud service.
Second, by having it on site, we have the control that we need over how we expand it and how we manage it.
Third, Keycloak, an open-source product that allows for single sign-on, with identity management and access management. We have Active Directory in the range, but Keycloak bridges that customer experience gap to provide single sign-on, with a great splash page that says "Cyber Range," and it's great for our customer experience.
Each of these 3 helps demonstrate something unique about the workflow.
With Postgres, we have this lockstep parallel development of Terraform and Ansible code. When I started out, I had a single VM that I spun up with Terraform, and Ansible configured it. I was able to cut a release of those 2 code blocks together, and it worked.
Then I could say, "Terraform, spin up more servers so we can do replicas, and, Ansible, configure those replicas and cut a release," and that now works. And I could continue iterating in these release-based blocks, ensuring that at every step along the way, the Terraform and Ansible code could be logically linked to a successful product.
MinIO shows how I can get hands-off managed capacity.
The first time I was playing around with MinIO, I just had a 4-node cluster, and then as I started to add more, to 8, to 12, and to the final design of 16 nodes, each time I was able to increase the capacity simply by updating my Terraform code saying, "Now there are more servers," and then updating my Ansible code saying, "Now there are more servers, MinIO." And never having to log on or restart services or do anything. It was just purely a workflow-based expansion of my capacity.
Keycloak really demonstrates how this is a very iterative and rapid deployment cycle. Starting off with Keycloak as a single-VM embedded database, and then, yep, it looks like this product could do the job for us, so let's make it HA.
So we spun up additional servers, and at the time our Postgres database cluster wasn't online. So we spun up a Postgres VM, and Terraform could handle that and Ansible could configure it.
And then as the EDB cluster came online, we were able to decomission our standalone and repoint Keycloak to our highly available cluster, all in a very iterative and controlled way.
The Roles of Terraform and Ansible
Let's go through each of these success stories and talk about the architecture and what role Terraform and Ansible has to play with them.
First, we have EDB. The design here will have 3 nodes, 1 primary and a couple of hot standbys, that are going to be in a cluster.
We're going to use streaming replication to make sure everything is in sync, then we're going to leverage a product called Enterprise Failover Manager, abbreviated EFM, which is part of the Enterprise DB service offering.
This is going to manage heartbeat, failover management, as well as the virtual IP, which will float between the nodes for whichever one is the primary.
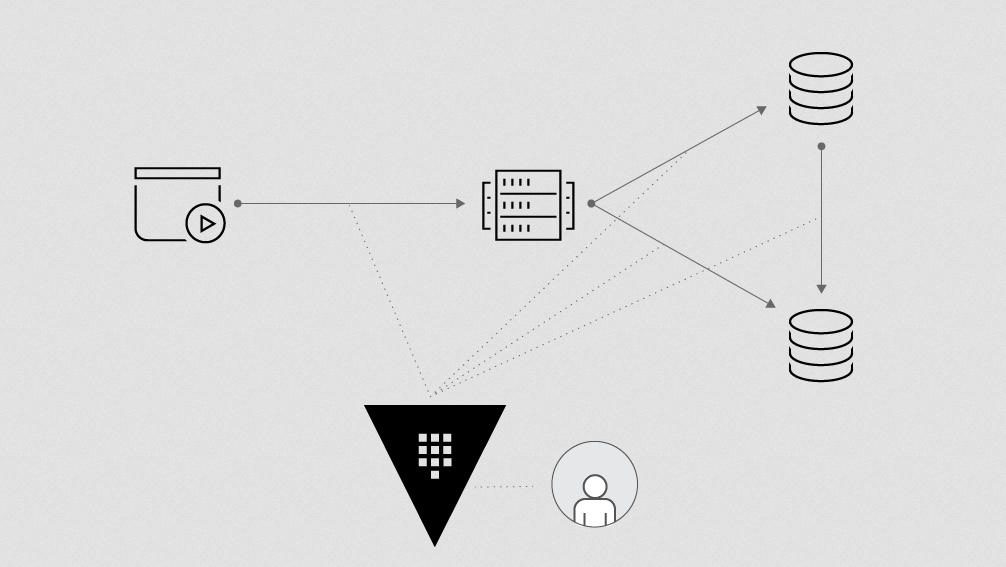
Let's see what Terraform and Ansible will do. Terraform's up first, it will reach into our internal HashiCorp Vault instance and generate TLS certs for all 3 nodes.
It then deploys 3 virtual servers for EDB. Terraform hands off to Ansible, and Ansible will manage the installation and configuration of EDB and installation and configuration of EFM before then configuring the primary and replica relationship, kick-starting the cluster.
There is a second role that I wrote, which manages our ongoing database creation, user management, and access controls with pg_hba.conf. You start with nothing, do a Terraform apply, Terraform runs, Ansible runs, and at the end, you've got a resilient EDB cluster. Pretty cool.
Let's look at MinIO. This is a little more complex. We're going to be doing 16 nodes in our cluster. That's going to enable a ratio coding 4, which means that we can lose up to 4 nodes before we have a service interruption, and we're also going to have encryption.
To keep everything from residing on 1 server, we're going to use host pinning, which is a technology that will allow us to limit 4 of those nodes to a single piece of hardware, a single ESXi Host, and in that way, we guarantee the spread of those 16 nodes across our infrastructure.
We're going to have a single entry point with a load balancer. So let's look at Terraform. Terraform will generate TLS certs for all 16 nodes with our HashiCorp Vault instance. It then deploys those 16 virtual servers from template but customizes it, adding on a 100GB data drive and setting up the host pinning.
Lastly, Terraform will deploy 1 additional virtual server for load balancing. Terraform hands off to Ansible, Ansible can install MinIO, the systemd service. And by the way, MinIO is a special one, because the systemd service has to know about all of the other nodes that are participating in the cluster.
When we started with 4 nodes, it had MinIO 1, 2, 3, 4, but now that we've got 16, it has MinIO 1 through 16, Ansible has that configuration managed in the systemd service.
Ansible will also enable SSL and erasure coding before then reaching into the load balancer VM to install and configure Nginx.
So start with nothing, Terraform apply, Terraform runs, Ansible runs, and then you have an on-prem 16-node S3 cluster.
Our last example is Keycloak. This design goes back to something a little more simplified. We're going to do 3 nodes in standalone-ha mode.
Keycloak themselves say that, although this is a simplified architecture, it can be more difficult to manage. All 3 nodes have to have identical configuration in order for the system to work. But this is where Ansible comes in.
Ansible as a configuration management tool can ensure that all 3 nodes are in lockstep. The design also calls for a shared Postgres backend like I alluded to earlier. So Keycloak currently is pointed to the EDB cluster.
Lastly, we're going to have a single load balancer as our entry point. Let's look at what Terraform does. It will generate our TLS certs from our internal Vault instance. It will also deploy 3 servers for Keycloak before finally deploying 1 server as a load balancer.
Terraform then hands off to Ansible, which is responsible for installing systemd. The Keycloak instance it will go ahead and configure, making sure all 3 are in lockstep before establishing that Postgres conductivity, and then reaching out to the new load balancer VM to configure Nginx with SSL passthrough.
Demo Time
Let's see this in action. You can follow along at this GitHub link.
As we look at our example, the first section we're going to look at is our locals. These are basically local variables that tell Terraform what it's going to do. At the end of this, we will have a standalone web server hosting static content over HTTPS, and we're going to use Nginx as our web server.
The first thing we need is to get a certificate, and that's what this resource will handle. There are a couple of local execs. This first one on lines 31 through 39 is only called when this resource is destroyed.
At the time of this recording, the secret backend cert is not actually revoked when the resource is destroyed. So line 34 issues the API call to handle that revocation. We also clean up some local files that are created in our second local exec.
This section will echo out the contents of the certificate, the ca_chain, and the private key to their corresponding files. Ansible will make use of these later.
Our next resource is a vSphere virtual machine deploy. This is a pretty boilerplate clone of VM, so I'm going to skip over most of it, but I've noted our local exec at the bottom.
First, we will install our requirements from Ansible Galaxy. Our requirement in this case is the geerlingguy Nginx role. The Galaxy is an online repository of roles.
Our second is going to be an Ansible playbook where we target the default IP address for this resource. The playbook looks a little complex, but we can go through it.
The first thing we're going to do is have some variables that tell the role what it's going to do. We're going to remove any default V hosts, before then adding a new V host that does a 301 redirect for anyone going to hdp.nginx.cyber.range, and they're going to redirect to our SSL one.
We have a root directory where our static content is going to be hosted, and then also you can see our SSL certificate and key.
This is a vanilla VM. We haven't actually configured anything in the template, so we need to do some tasks to make sure that this will work.
The first thing we do is we create that etc/ssl directory before copying up our public cert and private key. Finally, we ensure the var.www directory exists before cloning in our static content.
Lastly, we include that geerlingguy.nginx role to tie it all together.
Now, if you have Vault in vSphere, you can play along at home, and we have Docker-ized this to make it a little more simple. The first thing you can run is this gen.env helper script. It will pull your Vault credentials, your vSphere stuff, and populate a file similar to this, docker_env.
These aren't my actual credentials; this just shows that there are key value pairs.
Then run bill.sh, which will kill and remove the HashiConf demo container if it exists and then build and run, mapping in our environment file, and also mounting the deploy folder as a volume mount.
Lastly, we can run the run.sh script, which will get us into an interactive bash terminal.
Let's get it going. The first thing that we'll be doing is running that gen.env script. This populates my file with all of my proper credentials.
Second, we're going to run the bill.sh script, so that just created the container and is running it.
Lastly, we'll enter the container. If we look at the contents of this working directory, we'll the cert directory, our Terraform code, our Ansible stuff. So let's go ahead and do a Terraform init.
This pulls in our providers. This is our vSphere provider and our Vault provider; that looks good. And we can go ahead and do a Terraform apply next.
This is a relatively simple plan; it's just a single cert and a single VM. We've already handled IPs and DNS and all that other stuff, so it'll be pretty easy to follow.
I've also sped up the recording for the sake of time, but we can see how all the certificate stuff was populated into the local files.
Now vSphere is doing its thing creating that VM.
When we look at something like MinIO, where there are 16 different threads going, it can be difficult to follow along with the logs. If anybody has any ideas on how to keep track of that, or if that's something that you've looked at in the past, feel free to reach out in the contact link at the end.
This should be wrapping up shortly, and then we'll be able to see the handoff to Ansible.
The first thing it's going to do is to download those requirements.
A quick shout-out to the geerlingguy; his role here for creating Nginx is phenomenal. If you haven't seen it before, it's really cool.
It will handle the installation based off of the operating system and the variables that you put in, and it makes it straightforward so that I didn't have to figure out how to install this; I could just use his.
You can see the tasks now where we're copping up our stuff, and we're done. Let's see if it worked. There you go, that is our static content hosted with a valid cert at nginx.cyber.range.
Charting a Future Course
There's a lot of stuff that I'm currently working on getting involved in this workflow. There's some other wish-list stuff that's on my road map. Let's go over some of them.
The first is to get Terraform and AWX to talk together. AWX is the upstream, open-source version of Ansible Tower. Tower is used to manage multiple inventories of your Ansible infrastructure, and it'd be great to have Terraform talk directly to AWX's API.
It would do a couple of things. It would reduce the complexity of this workflow, and it would remove the requirements for having a local install of Ansible and installing a program called SSH Pass in order to pass through credentials.
The way it is currently, if I wanted to go to Terraform Enterprise, I'd have to make my own runners, and I don't really want to do that. Having to go directly to the API is a little more streamlined.
The other thing that this can do is enable some flexibility in levels of more dynamic flow.
The second thing would be to have Terraform create vSphere tags, and then have AWX consume those tags to create dynamic inventory.
For example, Terraform could spin up a new Postgres cluster in QA and tag it in vCenter as Postgres QA, and then tell AWX through the API to scrape for the new systems and then apply the Postgres playbook to those newly discovered VMs.
This would give everything a little bit more flexibility and I think would help really streamline the whole process.
Also, I'd like to bring in more HashiCorp tooling. Manually specifying all the members of the cluster in MinIO is fine, but I would like to use a legit service discovery product.
If anybody has experience getting Consul and MinIO to talk together, please reach out.
Lastly, and this is the most important thing, I really need to get a hitch and a trailer, because deadlifting 80 pounds of boat every time I want to take it out is not sustainable.
Thank you guys so much.