

The Nomad team recently released an update in Nomad 1.4.3 that can reduce scheduler loads by 90% when your cluster is handling rapid changes. This post explores how we developed and tested this improvement. You’ll learn about how Nomad coordinates its distributed schedulers and ensures that scheduler plans are applied in the right order.
»Missed heartbeats and evaluation backlog
When you submit a job to Nomad, you're telling the Nomad servers about a desired state of the cluster. The Nomad servers then need to evaluate what changes to make to the cluster (for example, running new allocations) to make the actual state match your desired state. When the actual state changes (for example, an allocation fails or a new node joins the cluster), Nomad needs to re-evaluate the state of the cluster again. Nomad starts this process by creating an evaluation for each job that’s potentially impacted (in Nomad, an evaluation defined as a unit of work).
Each evaluation is written to Raft, Nomad’s distributed data store, and replicated to all followers. A long-lived goroutine on the Nomad leader called the eval broker maintains a queue of those evaluations. Scheduler workers running on all the servers dequeue evaluations from the eval broker. The eval broker ensures that evaluations are processed in order of priority. The schedulers are optimistically concurrent — they can evaluate multiple jobs at the same time, and the resulting plans are checked against the current state of the cluster and applied one at a time (or “serialized”) by the plan applier that runs on the leader.
This edge-triggered architecture scales well up to clusters of thousands of client nodes and many thousands of jobs. But some users reported problems whenever they had large numbers of client nodes go offline at once. This can happen during decommissioning of a portion of the cluster or a temporary network partition that causes clients to miss heartbeats. In these cases, each node failing a heartbeat will result in a new evaluation for each service job running on that node, plus one evaluation for every system job in the cluster.
For example — in a cluster with 100 system jobs, and 5,000 nodes, each with 20 allocations for service jobs — if only 10% of those nodes miss a heartbeat, then (500 * 20) + (500 * 100) = 60,000 evaluations will be created. The Nomad support team has responded to incidents where “flapping” nodes resulted in millions of evaluations. All these evaluations create load on the cluster, and typically are doing so at the worst possible time — in the middle of an incident.
»The investigation and solution
When we investigated the performance of the eval broker, we found several places where we could reduce load. The first was to produce fewer evaluations, by doing first-pass filtering of system jobs by datacenter.
The next area of investigation started with the fact that evaluations are idempotent for a given snapshot of the cluster state. That is, if a scheduler processes an evaluation at one state and then re-runs the evaluation against the unchanged state, the resulting allocation changes will be the same. This meant that in the case of flapping nodes, when a large queue of evaluations would pile up, one or two evaluations would result in changes while thousands more for that same job would need to be uselessly processed by the scheduler.
Ideally, Nomad would determine when an evaluation was going to be safe to drop before it was created, because this would prevent it from being written to Raft. But in practice this proved to be impossible to do safely — Nomad schedulers run not just concurrently but distributed across all the Nomad servers. We could query the eval broker’s state on the leader, but we couldn’t guarantee that a scheduler hadn’t submitted a new plan between the time we checked the eval broker and the time we decide whether or not to write the Raft log entry. Or at least, not without having the eval broker locked to prevent dequeuing, which would slow performance more than the original problem we were trying to fix.
Instead, we accepted that the evaluations were already written to Raft but tried to prevent all the cancelable evaluations from having to be processed by the schedulers. The eval broker maintains several priority queues. One of these is the unacked queue, which represents evaluations that a scheduler has dequeued for processing but not yet processed. Another is the ready queue, which represents evaluations that the scheduler will hand out to schedulers when they dequeue their next evaluation. The remainder of the pending evaluations wait in the pending queue (note that prior to Nomad 1.5 this was referred to as the blocked queue; this is not the same as the blocked evaluation status so it was changed to remove confusion).
When a scheduler successfully plans an evaluation or the evaluation is a no-op, it acknowledges (“acks”) the evaluation to the eval broker. The eval broker finds the next pending evaluation for that job and moves it to the ready queue. In this way the eval broker enforces that at most one evaluation for a given job can be in-flight at a time.
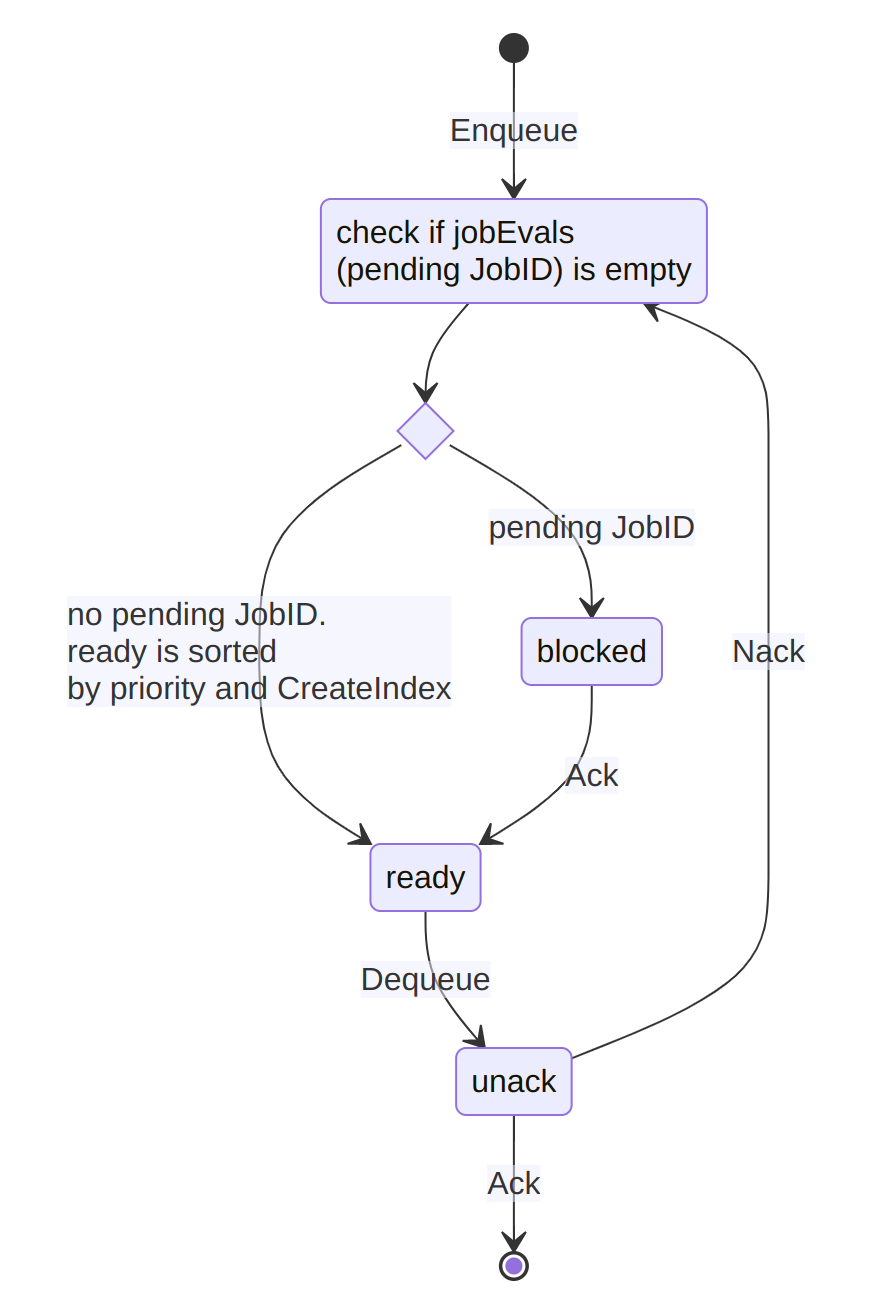
But because evaluations are idempotent over a given state, we knew that once an in-flight evaluation was acknowledged, we could safely drop all but one of the remaining evaluations in the pending queue. These are now moved into a cancelable set. A reaper goroutine marks these cancelable evaluations as "canceled" in the state store, and it can process large batches of evaluations in a single Raft log entry. The reaper runs periodically, but is also “woken up” whenever any scheduler acknowledges an evaluation. This diagram shows the new flow of evaluations through the eval broker introduced in pull request #14621.
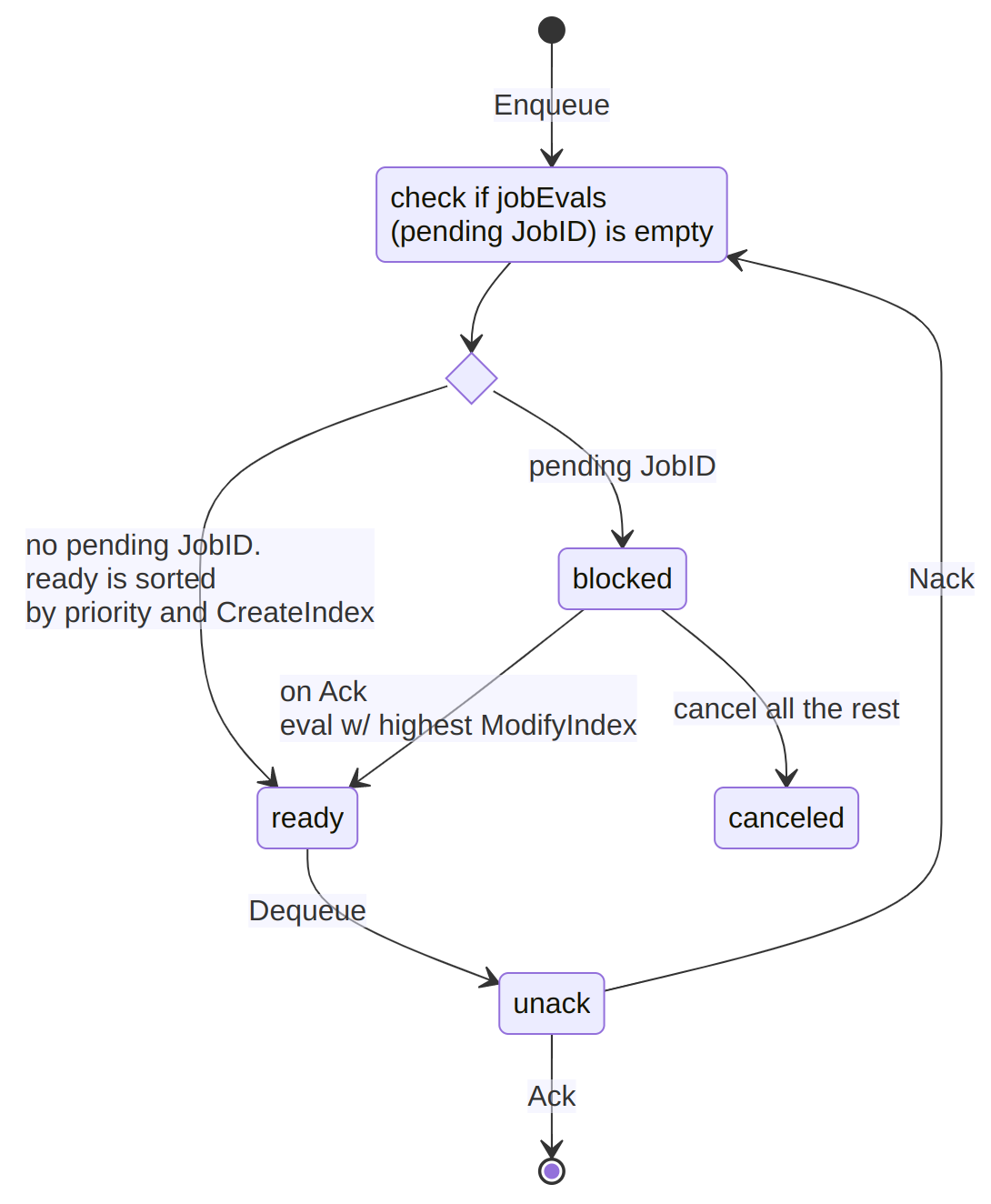
In theory we knew that this change would decrease the number of Raft logs that had to be replicated between servers during these high-load incidents, and it would also decrease the load on the schedulers by reducing the number of evaluations that had to be processed. But by how much?
»Benchmarking the change
The last step of the work was to compare the performance before and after the change. We stood up a Nomad cluster with 3 servers, each with 8GiB of RAM. For each test run, we disabled the schedulers on all 3 instances by setting server.num_schedulers = 0 and reloading. Then we deployed 10 system jobs and started 5,000 simulated client nodes using nomad-nodesim. As each client node registered, a new pending evaluation was written to the state store and the pending queue of the eval broker. At this point, there are roughly 50,000 pending evaluations.
Next, we re-enabled scheduling by commenting-out server.num_schedulers = 0 and reloading the configuration. The schedulers restart and begin processing. The goal of this test is to see how quickly the eval broker is emptied and all evaluations are written to Raft as either completed or canceled.
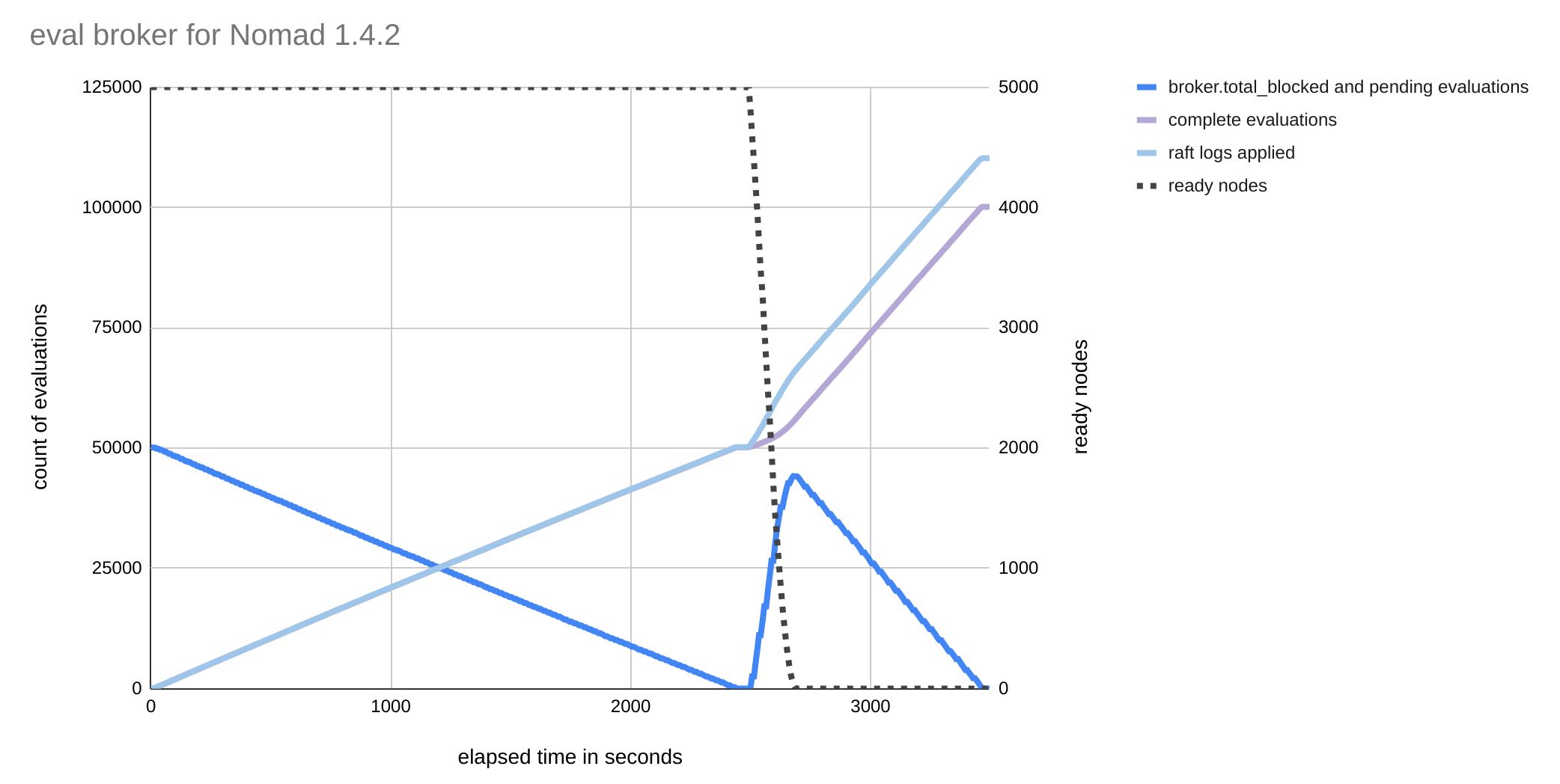
For a version of Nomad without the updated broker logic (v1.4.2), the number of evaluations pending in the broker steadily decreases over the course of roughly 40 minutes until the queue is finally emptied. Because there are 10 system jobs, only 10 of these evaluations result in plans and the remaining evaluations are marked as complete. The scheduler workers must dequeue, process, and acknowledge all 50,000 evaluations. The Raft index increases by 50,193, which means that 50,193 new Raft logs had to be written and replicated by the leader (this doesn’t exactly match the number of evaluations because Nomad generates its own Raft logs for internal bookkeeping). This creates enough load on the servers to cause the test cluster to miss a few heartbeats during the test run.
Next, we stopped all the simulated clients so that they would miss heartbeats and emit new evaluations for all jobs over the course of roughly three minutes. The number of evaluations in the broker's pending queue initially increases, because the schedulers for these nodes can’t keep up with the load of new evaluations. The schedulers eventually catch up and all evaluations are processed after roughly 13 minutes. The leader writes and replicates another 43,656 Raft logs.
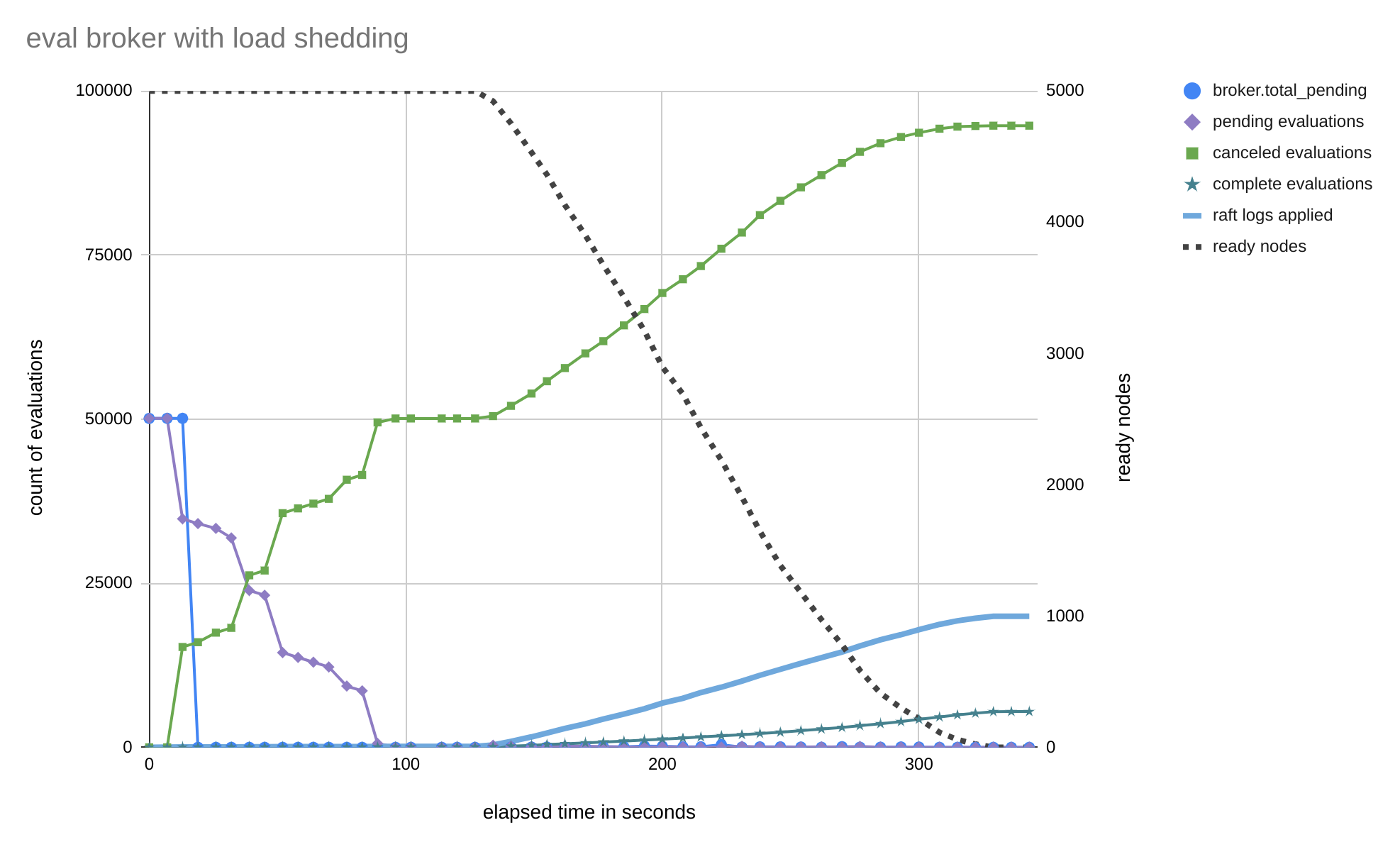
When we run the same test with the version of Nomad that has the new broker logic (v1.4.3), the number of evaluations in the broker's pending queue immediately drops to near-zero. Each scheduler worker picks up an evaluation for a different system job and then, upon acknowledging that evaluation, all but one evaluation for that job are immediately moved to the cancelable queue. Within 90 seconds, all of those cancelable evaluations have been canceled in batches. Only 20 evaluations in total need to be processed by the schedulers, and the Raft index at the completion of this step has only increased by 128, which means the leader has had to replicate 0.2% as many Raft log entries.
Next, we stop all the simulated clients. With the new broker logic and the schedulers still running, the broker's pending queue never fills up. The broker can immediately discard extraneous evaluations as the scheduler workers process and acknowledge them. The cancelable evaluations reaper marks all the new evaluations as canceled in batches. Because the servers are processing client updates as they come in, the batches are smaller so there are more writes than before we stopped the client. But the total number of Raft log entries written is only 19,969 (18%), and we've completed the work for this step in a little over 3 minutes instead of 13.
»Conclusion
Overall, the changes to the eval broker reduce Raft load by over 80% and scheduler load by 99%. By upgrading to Nomad 1.4.3 or newer, you’ll enjoy reduced recovery time by 90% when your cluster is in the middle of an incident. This gets Nomad back to scheduling your workloads faster.







