Don't make application security a network layer problem
Treating a network like it is already compromised is a core tenet of zero trust security. Knowing this, why are so many “secure” systems still taking a network-centric approach, relying mainly on their firewalls to protect them?
This article examines why migrating to a service-based network architecture and moving up the OSI stack, specifically to Layer 7 for observability and traffic management, can help you end your reliance on traditional castle-and-moat network security. It will also identify the key components for implementing the National Institute of Standards and Technology’s (NIST) zero trust architecture.
»The age of castle-and-moat must end
Let’s begin with a common scenario seen in many enterprises — migrating applications from on-premises infrastructure to one of the public cloud vendors. As these organizations move into the cloud, they tend to focus on protecting their applications mainly at Layer 3 — the network layer. They’ll use security groups, access control lists, and virtual private clouds (VPCs) to keep things inside the network “safe.” A common stack is the F5 load balancer and Palo Alto “sandwich” (DMZ). While these tools are fine layers in securing a network, they’re not enough.
It’s not enough to just expand these network security walls anytime your system grows and consider everything on the “inside” safe. It’s not enough
to break out and inspect each network packet that comes into a datacenter. Most breaches (82%) are due to a human element (social engineering, errors, misuse of privileges), meaning that many threats will be able to get into your network.
The reality is that it’s just a matter of time before someone gets on your network, behind your castle and moat. It’s already happened to Target, Neiman Marcus, Google, Equifax, and the list of breaches goes on.
As companies transition to more dynamic, cloud-based infrastructure, the issue with many network security practices is that they make application security a network layer problem.
»A fundamental change in thinking
In a typical on-premises environment, a single error in a firewall rule does not usually result in complete exposure to the outside world. But in the cloud, a single change can expose resources in any VPC to the outside world. As an example, a misplaced default route or security group rule is enough to expose access to everything.
That’s the key issue with maintaining a security posture that was meant for on-premises, host-based network architectures. They make application security a network layer problem.
Placing firewalls all over your environment, even with more modern, micro-segmenting firewall solutions, is no longer the most practical, cost-efficient, or least complex option in environments with ephemeral cloud infrastructure. That’s still a static mindset — still focused on the host and the IP address.
In a dynamic cloud environment, the application service should be the core primitive of your network.

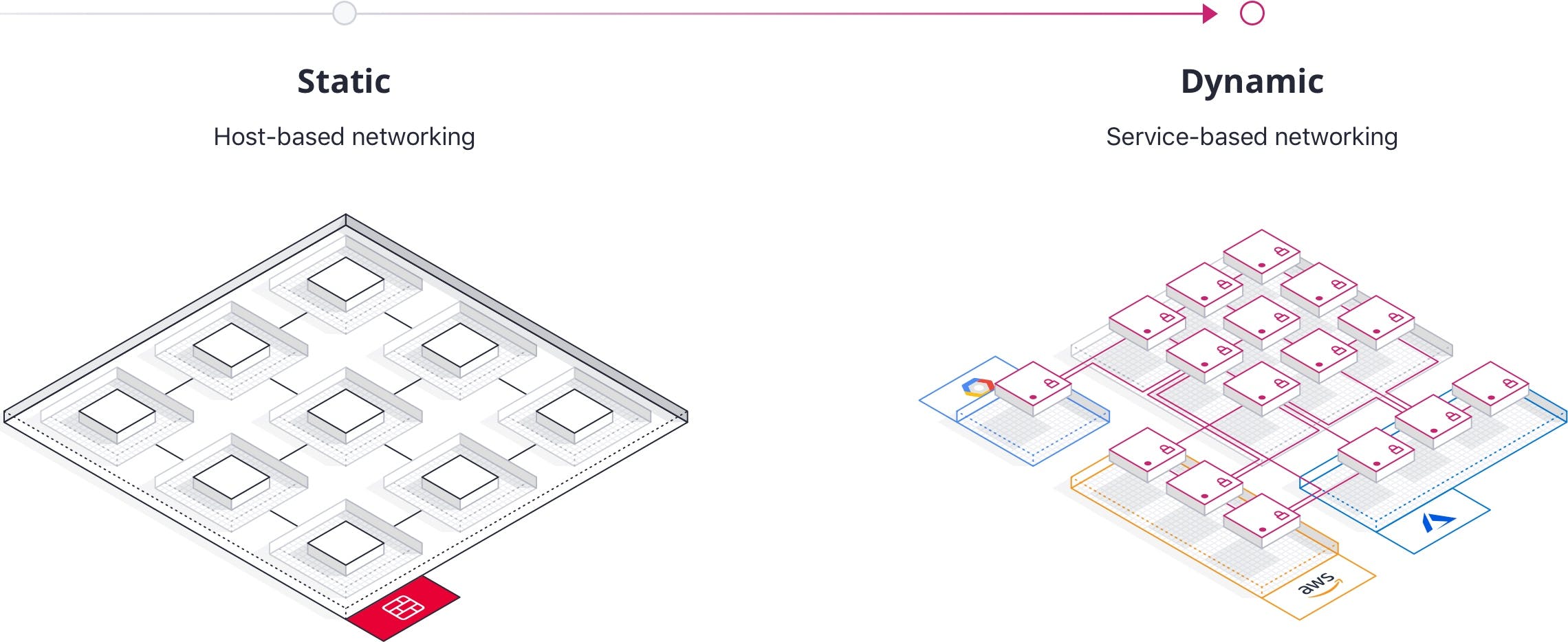
Host-based vs. service-based networking
IPs are changing constantly in cloud environments, which means their direct use is no longer a safe, scalable means of identifying entities and opening barriers in your network.
In service-based networking, the IP addresses are mapped with a service catalog to the service registry, where they are assigned DNS. Ideally, you’re also using a modern networking platform that can manage and observe traffic at Layer 7 of the OSI-stack, instead of just Layer 3 or 4.
Layer 7 gives logical automation controls for HTTP traffic routing and shaping along with a tight control over the resolution of services while also providing failover and rerouting capabilities. It also opens up a new world of observability and monitoring opportunities.
The emerging best practice for service-based network security is zero trust security. NIST has a framework for this architecture.
»How to implement NIST’s zero trust architecture
NIST Special Publication 800-207 presents an abstract zero trust conceptual framework that includes three core components: A policy enforcement point (PEP), a policy administrator (PA), and a policy engine (PE).
The PEP is “responsible for enabling, monitoring, and eventually terminating connections between a subject and an enterprise resource.”
The PA is “responsible for establishing and shutting down the communication path between a subject and a resource.”
The PE is “responsible for the ultimate decision to grant access to a resource for a given subject,” which includes machine-to-machine or human-to-machine communications.
Here’s how they look in NIST’s zero trust architecture diagram:

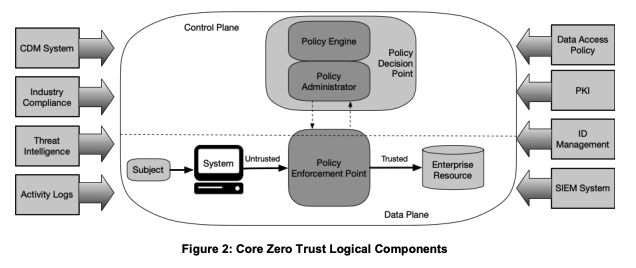
NIST SP 800-207: This diagram shows the logical components of a zero trust architecture. Note the PE, PA, and PEP in the center.
NIST SP 800-207 also includes several zero trust requirements:
The enterprise must know its equipment, and not via a MAC address or a serial number, spreadsheet, etc. The enterprise must have a cryptographic credential that proves the identity of the device that meets FIPS 140-2.
The enterprise must be able to audit and log all network traffic of every layer of the network, including L7 traffic on the data plane.
All traffic must use a policy enforcement point such as intentions, policy as code, and access control lists (ACLs). All traffic must be encrypted at rest and in transit (ideally with mTLS) and should be able to connect only after passing the PEP, PA, and a PE.
The data plane and control plane must be logically separated, meaning the PE, PA, and PEPs need to communicate on a network that is logically separate and not directly accessible by enterprise assets and resources. They use the control plane to manage connections between assets, while the data plane is used for application/service data traffic. This ensures that the security controls of the control plane can function even when parts of the system are down.
Enterprise assets must be able to reach the PEP component to gain access to a resource. This means an agent or sidecar can be applied to ensure nothing can bypass the PEP. An example is a transparent proxy.
Remote enterprise assets should be able to access resources traversing the network first. A remote user shouldn’t have to use a link back to the enterprise network, such as a virtual private network (VPN), to access public cloud services such as email. An identity aware proxy can help with this.
The underlying infrastructure and the service level networking must be scalable and performant based on service-level indicator/service-level indicator to ensure that a PEP is not down, which would pose a risk to the zero trust architecture.
Enterprises should have some assets not able to reach certain PEPs due to things like geographic location, or other criteria.
These requirements all clearly point toward a well-known networking architecture: a service mesh.
»A journey to zero trust via service mesh
A service mesh has the capabilities to act as PEP, PA, and PE. It builds off the foundation of service discovery to register all services and connections, and then uses intentions and access control lists to manage which services can connect with each other. No connection is trusted by default — there’s no assumed-safe network.
A service mesh pushes routing, authorization, and other networking functions to the endpoints in the network, rather than imposing them through middleware. This makes the network topology easier to manage, removes the need for expensive third-party solutions, and makes service-to-service communication reliable and scalable.
Service mesh also encourages an organizational shift toward microservices and self-service networking for developers. And it encourages networking roles to take on more of a platform team mindset as an enabler and builder of a networking platform that unifies workflows and technologies into one golden path.
If you have trouble deciding on a service mesh platform, try HashiCorp Consul. Compared to other service mesh options, it’s highly focused on user experience and ease of onboarding. It’s the most widely used service discovery solution on AWS, and James Governor of the consulting firm Red Monk says it offers a more straightforward experience than the competition does.
If you’re looking for straightforward solutions to zero trust, check out this whiteboard video and transcript by HashiCorp Co-founder and CTO Armon Dadgar.



