Now Witness the Firepower of This Fully Automated and Immutable Vault Cluster
Learn how to quickly set up an immutable, recoverable HashiCorp Vault cluster in this talk.
Speakers
 Peter SouterTechnical Account Manager, HashiCorp
Peter SouterTechnical Account Manager, HashiCorp

Vault is an excellent tool to secure, store, and tightly control access to secrets. But like with any tool, you need to know how to feed and maintain it. Luckily, there are a number of great features and tooling that can help.
This talk will demo:
- Bootstrapping your Vault configuration and secrets with Terraform and other tooling
- How to make a Consul backend fully immutable with auto-pilot
- Backing up your Vault data automatically
Transcript
My name is Peter Souter, and I'm a senior technical account manager at HashiCorp. This basically means that I work with organizations that have started on their journey of using our enterprise versions of the HashiCorp stack on that deployment journey.
This could be anything from discussing roadmap, talking about use cases, coordinating with engineering and support, and things like that.
Ultimately, the point of my job and the name of my team is Customer Success. I'm not successful until my customers are successful; hence the name. As you can probably tell from my accent, I'm from London in the UK. I've been with HashiCorp since February of 2018.
A funny fact about me is that, even though I'm from the UK, I'm super into baseball. I went to the Mariners game last night and they won, so woo! I really love coffee as well. So Seattle is the perfect place for it. And the weather really made me feel very much like home.
There's a small, indie series of movies—I don't know if you've heard of them—called Star Wars. In Return of the Jedi, there's a famous scene where Luke finally finds out that the Death Star isn't as under construction as he thinks it is; it's a fully operational system, and it's going to start doing bad things to the rebels.
I thought, "That's a pretty cool line. I'll use that in my talk."
Vault automation
The main thing we're here to talk about is automation for Vault. Why do I want to talk about that?
As I mentioned, I'm on the Customer Success team. It's my job to make sure customers are successful with Vault. I've worked with a lot of customers all over the EMEA (Europe, Middle East, and Africa) region, anywhere from finance companies to small, medium enterprises. There's a big variety of what people are using, but all of them are getting lots of value from Vault.
The analogy I like to use is that, when you first start using Vault, especially when you're in the proof-of-concept phase or in the dev environment, it's a lot like a cool, nifty speedboat. It can do a lot of cool things. You're using it as a secrets server and everything's really good.
The problem is, as you start to productionize it, as you start to integrate other teams, you're going to start using manual processes to start with. You're going to end up with something like a really big anchor dragging on the seabed and slowing everything down.
To stretch the metaphor even further, we're going to use the scissors of automation to cut that cord to the anchor.
To give you a peek behind the scenes, when I submitted this talk, my idea was, "Let's talk about automation. Let's talk about explicitly how to deploy Vault with tools that already exist." I was going to do a demo. I was going to go into the explicit things of what to do and what not to do when deploying Vault.
The problem with that is, as they say in the UK, how long is a piece of string? There's no perfect way to deploy Vault. There are some guidelines we give, there are some recommendations we have, but guidelines or recommendations don't always fit exactly with what your organization or company is doing.
So instead I thought we'd take a top-down view. The idea is that we're going to talk about some of the core concepts when automating Vault, and I'm going to throw in 2 bonus, really cool automation features that I'm not sure everyone knows about. Every time I've worked with customers on them, they found them really valuable.
So hopefully you are not feeling too cheated by the fact I don't go into explicit detail about automation.
One key thing that I'm going to be hammering home in terms of automating Vault is that you want to reduce the blast radius. No system is perfect. What you want to do is have a controlled way when things go wrong. If a token leaks, if something goes wrong with the deployment or automation, it should be a very small, controlled way of it going wrong. You want to control that blast radius.
Let's get started.
Some recommended Vault documentation
With any task or project, you want to start off by planning and thinking about things. These are the 4 key docs that I would recommend to anyone:
Go and read. Even if you've got a slight interest in Vault, these will help you figure out where you're going to go in the future.
The first one is the security model. This will go through what is and is not included in the threat model of Vault. It's a really good thing, especially if you're introducing Vault to a security team. A lot of the time, they might say something like, "What is the threat model?” And you can say, "Here's the doc saying what is the threat model."
Some things are within scope; some things aren't. It's good to know those off the bat before you try to start automating and deploying it in a way where it's something that we don't have as part of our framework.
The production hardening guide goes into specifics about how to deploy and harden for infrastructure. We're going to pick out some of those and drill down where they relate to automation.
The first one is single tenancy. The idea is that Vault should be the only and main process running on the machine. When you do that, you're reducing the risk that, if the machine is compromised, another process can interact with Vault and cause problems.
We also talk about single tenancy in terms of the abstraction layer that you're using Vault within. The lowest abstraction is going to be bare metal, then VMs, then containers. The idea is that as you go up the abstraction levels, the higher the surface area of attack can be.
I'm not saying that we don't support Vault on containers, and I'm not telling you to throw your VMs away and start using bare metal, but it's a good idea to know that for each level, you're going to increase that risk. And most of the time that's fine, as long as you understand that as part of your risk when doing this stuff.
Tokens
When Vault is first initialized, you get a root token, and that's pretty much the keys to the kingdom. It can do anything. It can initialize, it can re-roll, it has permissions to everything underneath it. You should pretty much only use that to do some initial, very small bootstrapping and to maybe set up some authentication methods that you then use to create sub-tokens.
As soon as you've done that, you should be rotating that root token away. You can create more root tokens with another token that has promotions to do that.
One thing I recommend is that you log when a root token is used, and that should be something that you're alerting on or have monitoring around.
The idea is that if a root token is being used, that should be an extraordinary event. That should be something that people should know about. It shouldn't just be, in the middle of the day, a root token is being used. Something has definitely gone wrong there.
Immutability
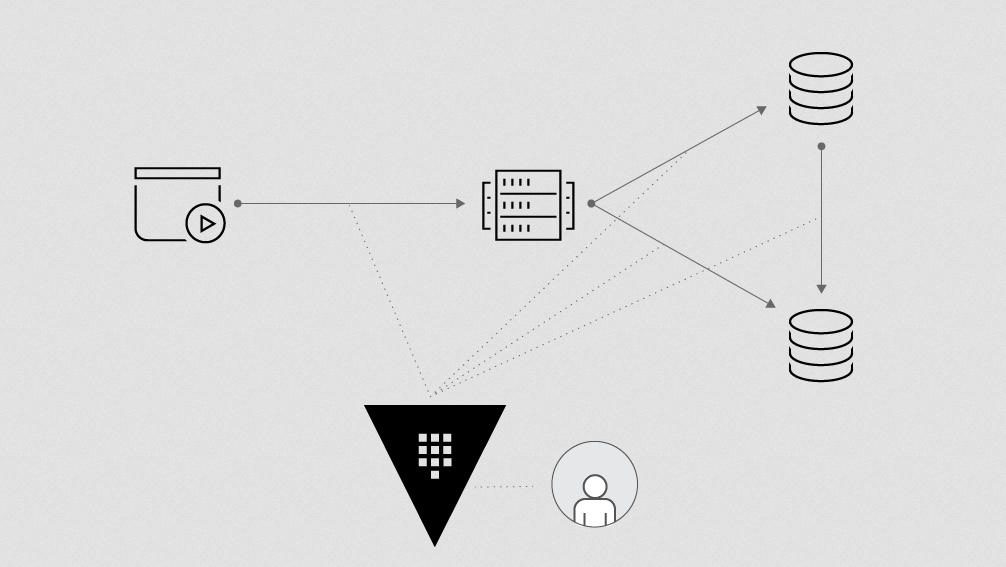
This is one of the other key features we talk about when doing automation. The idea is that Vault itself, all its persistent storage, is done from the storage backend.
Because Vault is using that for its persistence, if you decouple that, it allows Vault to be managed pretty immutably.
If you need to do something like upgrade to new versions, if you need to expand your cluster, if you need to move it around, all of the ongoing data is kept in the storage backend.
As long as you're attaching to the same storage, you can bring old servers away and bring them back up. It means the upgrade process is a lot easier. You can just have a cluster, take the old one out, put a new one in, and everything works great from there.
Doing this means that you reduce the need for remote access and the more direct orchestration that could introduce security gaps. You don't want someone logging into root on a Vault box.
Auditability
Related to that, no system is perfect, and Vault is no exception. The idea is that you want to have all of the things that you're doing with Vault audited and logged somewhere. You want a second system of record as a way of finding out what's happened with your Vault service.
Vault has several audit backends. What you need to do is plug them into some sort of a log analyzing tool, an ELK stack, Splunk, Datadog, whatever it is. You should have that tied into your monitoring and your alerting and your observability. You should be able to know what's happening and where, and detect those outliers.
With all that in mind, one thing I like to highlight: Even on the page, we talk about production hardening. We try and hit these where possible. We're not expecting you to hit every single one.
Some company policies, maybe they're even stronger than the ones we have, or maybe they directly contradict the advice we give. So things like turning off core DMS or turning off remote access completely, it's not always going to work with how you do deployments. But the idea is that you should be trying to hit as many of these as you can where possible.
Virality
When it comes to automation, there's one extra point that I like to talk about that I call virality. The idea is that whatever processes, tools, or even people are part of the automation pipeline and system you're dealing with in Vault, they need to be as secure as Vault is. They're going to be part of Vault's threat model.
There's no point having a super-hardened wide set cap and everything all enabled in your Vault server if you have a Jenkins server that can interact with it with a root token and do whatever it wants.
It's the equivalent of having a super-secure safe and then just having a Post-it with the combination on the front.
You want to make sure that anything that's interacting with Vault is part of that threat model.
Architecting Vault
We've done the reading, we've figured things out. Now we need to begin architecting.
The most basic Vault architecture would be a single node with the storage backend. The idea is that it's just a Vault server running is using storage on local disk. That's pretty simple. You can set that up in a couple of minutes. But that's not very resilient.
The minimum we recommend would be a 3-node Vault cluster and a 5-node Consul cluster.
The idea behind that is that you want to achieve n-2 consistency, where if you lose 2 of the objects within the failure domain, it can be tolerated. The ideal size of a Vault cluster would be 3.
Consul achieves replication and leadership through the use of its consensus and gossip protocols. There have been a few good talks about that, if you want to know more about that. But the idea is that the leader is done by consensus. You need a quorum of active servers for that. For that you need 5 servers. This is the simplest high-availability (HA) version of a Vault deployment you can think of.
But as you can probably guess, this isn't really giving us Availability Zone-level HA. Because if that Availability Zone (AZ) goes down, your entire Vault cluster goes down.
Similar to what I said at the start of this talk, there's no silver-bullet solution to deploying Vault. This is why I ended up pivoting from my original idea for the talk.
What you need to do is decide, based on your organizational needs, what you're going to do with your Vault deployment. Are you on-prem? Are you in the cloud? Are you doing a hybrid solution? Are you replicating between some VMware on-prem stuff with the cloud? Are you using an on-prem server but talking to services within a cloud.
That's one of the things to think about and thinking about your failure domains. Are you worried about AWS going wrong? Are you worried about your on-prem server going wrong? If so, figure out which ways you want to do the replication.
Are you on open-source Vault or Vault Enterprise, and if you're on Enterprise, have you thought about disaster recovery and performance replicas?
If you go back to the links we talked about earlier on, in the reference architecture, we go through pretty much every combination of Vault you can go for.
Are you worried about AZ failure? If you are worried about AZ failure, do you have open source or do you have Enterprise? If you have Enterprise, are you worried about multiple AZ failures?
We have lots of different scenarios for doing that. How long is the string? There are loads of bits to it.
Automation building blocks
We've decided things, we've figured out the core concepts, we've got the initial architecture. Now let's start building the building blocks behind the automation of Vault.
Is there some sort of tool out there, some way of interacting with APIs and clouds to create these resources? It sounds like something we should probably do.
Terraform is pretty good at doing that. We've got some pretty good prior art for doing this. Under the HashiCorp namespace on GitHub, there are repos for deploying Vault, most of the architectures that we talked about:
Again, not extensively, because there are so many variables, but it's at least a good baseline for doing this stuff.
Who's heard of the Vault-Guides repo on GitHub? It's little snippets of Terraform or scripting or just general step-by-step guides on how to do stuff—practical guides and how to do everything.
If you need to figure out how to automate a particular process—maybe it's the initial Shamir's Secret sharing algorithm or an auth backend or how to deploy in GCP versus AWS—those little snippets are a really good baseline for kicking around that stuff.
And as I said, I'm part of the Customer Success team. We also have an enterprise architecture team. I work very closely with them, and we have some more detailed plans around the best practice guide for doing Terraform.
We have more options and selected ways of doing that.
Vault policy and mount configuration
Now we've created the resources behind Vault, the networking, the compute, the storage, and all that. How do we configure Vault itself? You can do it with scripting, you can do it just using the Vault CLI, or maybe even hitting the API endpoints yourself or something like curl.
What we really can use, especially if you're already in Terraform to create those resources, is there’s a Vault Terraform provider that will do this itself. It will talk to the Vault APIs. It will configure it through that with the added benefit that you can take the variables, the data sources, the resources you're creating as part of your initial creation and reference those in your Vault configuration.
For example, if you're configuring a particular IAM role to create the auth backend, you can reference that information within your authentication backend configuration for AWS. That's pretty cool.
But remember, Vault security is viral, and Terraform is no exception there. We had a pretty cool webinar where we explain some of the approaches you can take to make sure that you're not leaking secrets and things like that.
Most of the stuff is as you expect. Even when using Terraform, you should be using for-real tokens. We actually did a big rehaul of the Vault provider in 2.0 a few months ago. One of the things that it can do is create sub-tokens as part of the Terraform provider process.
The idea is that you're using your for-real tokens for that. So if someone manages to get the token that you used as part of that Terraform run, they can't do anything with it afterwards. You're keeping best practices across the board there. I recommend watching that webinar. You're going to know more.
Testing the automation
One important thing is, with any automation, there's no point automating everything and then just hoping that every time that you do it, it doesn't go wrong. You want to automate the testing of it as well.
This is fairly easy to set up. There's an example for Travis CI. All we're doing is, there is a flag to run a Vault server as dev. And when you're running it as dev, it starts unsealed with a single root token and a single unsealed token.
You can also, as a parameter, set what the root token will be. For your test, it'll spin up a temporary Vault server, where everything is stored in memory, if you don't use it in prod. I hope people don't need to be told that.
In this step, we're doing an install, we're downloading the latest version of Vault, we're doing some linting with Terraform, we're doing an apply and then going through and doing that test. We can consistently test that.
What's really good is that, with that, you can start testing provider versions. You can test new Terraform versions. You can test new Vault versions. So you've got a pretty good idea that doing a Vault upgrade or changing to a new provider or changing the Vault version won't cause any problems for your deployments.
And if you really want to go all out with the testing, you can test the entire creation of your cluster with Terraform itself. Gruntwork, who wrote the original modules that I referenced earlier on, have a tool called Terratest. It's a bunch of helpers to write tests to test the cluster itself.
In this example, it's creating a Vault cluster and then SSH'ing on and running the Vault operator init. So it's not just doing a Terraform run and seeing if the plan-apply works. It will do explicit tests on that.
Obviously, depending on your cloud resourcing, your costs internally, this might not always be possible, especially if you're going for the big, beefy boxes or you're doing a really big Vault deployment. But if you want to reduce risk and you want to know that any changes you make won't cause any problems, this is a really good way of doing it.
Early on we talked about immutability and about using the full Hashi stack, and one of the benefits of the Hashistack is, everything works together. Packer is perfect for this. You can create a golden image of Vault.
If anything goes wrong with it, if you need to do an upgrade, all you need to do is create a new image—and as we said, upgrading is just the case of adding it in—and if it's an HA cluster, you would just upgrade all the standbys. Then, when the standbys are upgraded, turn the active off and go through them.
If you're doing a single-node cluster, it's literally just the case of upgrading the image and everything goes from there.
Ongoing management
For ongoing management, there are tons of config management tools out there:
Full disclosure: I used to work at Puppet. I've been using Puppet for 7 or 8 years now. I have code in the Puppet module that's on the screen.
I use Puppet code to manage my own Vault clusters at home. So I'm pretty biased when it comes to that. But the idea is, as long as you keep in mind what we talked earlier on about virality, about how whatever tools you're using will also be part of the Vault threat model, it's fine to use conflict management to manage Vault in the future.
Because conflict management generally already is running as some sort of very high-level process, because it's making file and system changes, it's not a huge worry most of the time, but it's one thing to think about.
That's the high-level view. That's automation of Vault. And that's all the various things you need to think about.
2 cool tips
When it comes to automation of the Consul backend in terms of upgrades, there's a really cool feature in Consul Enterprise called Autopilot. What it will do is automate the server upgrades for avoiding downtime. That process works.
New servers are added in. As higher versions of Consul are added in, they will auto-join. Autopilot will wait till enough upgraded Consul clusters have been added in and joined the cluster and there's enough quorum for them, and then it will start to demote the old clusters and promote the new ones.
It's a pretty cool blue/green automated way of doing this. You can do this yourself with scripting and things like that. But this is fully automated as part of the product itself.
When it comes to automation, there's this extra feature that not a lot of people know about called upgrade_version_tag. What this will do is, instead of looking at the Consul version itself, you can specify a version that you want to use to compare between the 2.
Let's say there's a new vulnerability for OpenSSL or you want to upgrade the version of Ubuntu on the image itself. If you have 2 Consul versions that you want to upgrade and both are 1.5 and then you try and do that with Autopilot, it's going to say, "These are the same version. I'm not going to do that." So with this, you specify a little bit of meta-information, and it will use that to compare between the 2.
In this example, I've got a CalVer of 2019.09.01. I do my upgrade or upgrade my images. Maybe the Consul version still stays the same. But then I change the upgrade tag to 2019.09.02. When it comes in, Autopilot looks between the 2 numbers, compares the 2, and says, "This is newer." Then the process will work the same. So there's a really good way of doing a rolling update without having to have Consul be a newer version.
Second one that's really important: Vault backups. In terms of a full cluster backup, the main way of doing that would be using something like a performance replica, which is a part of the Vault Enterprise stack.
The idea is that you have a standby Vault cluster. It's kept synchronized with the active Vault cluster. Everything is in there, ethereal authentication tokens, time-based authentication tokens, token usage data. Everything's in there. Basically, it's a cold standby.
It gives you a pretty aggressive recovery point if you have any sort of situations where keeping things going are the utmost concern. It's pretty good.
But this doesn't cover every single use case. There's a certain kind of error field that you can have for this that you don't really get covered.
And that's unintentional or intentional sabotage. If you have purposeful or accidental corruption of data or even someone's stolen your cloud control access—maybe someone's phished your keys or something like that—you have no real way of recovering from that. Because the DR replication is designed to replicate live data, any intentional or unintentional corruption would be replicated across, and then you've got 2 useless systems.
You should be backing up Vault storage back into itself.
Consul has a snapshot feature. All that does is it will take a snapshot of the current data that it has and just save it to disk. All pretty normal. If you're using open source, you'd have to write some sort of scripting, maybe Cronjob, to run a snapshot and then ship it off-site into whatever way you want to do.
If you're running Enterprise, you have the backup agent feature. It will run the snapshot command as a service in Consul with the full health checks that you get from that. It does all the standard minutiae that you expect from a backup solution: It does rotation of files, it saves things off-site, it tells you how often you want to run the task, and how much you want to retain, and that kind of thing. All the things you expect from a backup solution.
The idea is that it would run as a service. It uses the same binary as Consul. You run it, and it will perform a mini-leadership election to make sure that when it does the backup process, it isn't in the middle of doing something Consul-related. So it won't try to do a backup in the middle of a leadership election, or something's gone wrong. That's a really good way of making sure that when you're doing these full-scale backups, nothing's going wrong at the time.
As you can see, it's scanning for leadership. It's got the leadership, it's saved the snapshot. If you're running in S3, it's going to ship the packets up, duress-free. You can encrypt the backups with another key.
Remember, that information in Consul is already encrypted with the master key from Vault. But if you want to double-encrypt it because that's just how you are, you can encrypt it with a separate key as well.
And then you probably want to write something like this, like a systemd unit file, and just have that running at the same time as Consul's running. Then you have a full backup that you can hydrate a full system back to if you worry about anything going wrong.
As I said, either unintentional or intentional sabotage.
What about the future?
Who here is on Vault 1.2? A few hands. Who here is using the internal Raft storage? Good, because it's still in tech preview, so you shouldn't be using it.
But the idea is to reduce the kind of operational complexity that comes with trying to run a Consul cluster. In Vault 1.2—and it will be hardened within a few releases' time—we have tech preview of internal storage. It's using the same Raft protocol that Consul is using, but it's built into Vault. So instead of needing 5 Consul servers and 3 Vaults servers, you just need 3 Vault servers.
The idea is, in terms of backups, it works in the same kind of way. Instead of using a Consul snapshot, you'll be hitting the API of Vault directly. In the future, we're going to be trying to integrate as many features as we can from the way that Consul is doing it. Obviously, it's a tech release to start with. Right now you'd have to do some sort of scripting to do that.
So what have we learned? We have learned to keep in mind the core concepts to follow when automating Vault, because how long is a piece of string? There are so many pieces to it.
We've reduced the blast radius wherever possible. We've learned where we can and cannot follow the recommendations we have. We've read the documents and figured out the automation requirements and then adapted those based on your organizational needs.
We've created the compute resources with Terraform. We've continuously tested those to make sure that we're not doing anything wrong.
We've used Consul snapshot for full backups in case of sabotage or accidental problems, and we've enabled Consul Autopilot so we've got a nice, automated way of upgrading the Consul backend.
And that's it. Thanks for listening, everyone. If you have questions, I am @petersouter on Twitter, and my email is up there as well. I've got lots of thoughts about how to deploy Vault and the future of things coming on. If any of you have any questions about things like enterprise architecture, come up to me afterwards. Thanks, everyone.