The Infrastructure Cloud
Do cloud right with a unified platform for your entire digital estate. The Infrastructure Cloud lets you manage the full lifecycle of your infrastructure and security resources and make the most of your cloud investment.
TRUSTED BY LEADING ORGANIZATIONS
You’re probably doing cloud wrong
It’s not your fault — doing cloud right is hard. Infrastructure management is already complex, and the rise of AI demands even more from infrastructure, data, and security.
Most enterprises run across a mix of on-premises, hybrid, and multi-cloud, where operations are fragmented, costs spiral, and security risks increase. Traditional datacenter tools and workflows can’t keep up, leaving organizations struggling to get the results they expect — and unprepared to scale AI safely.


Meet The Infrastructure Cloud
The Infrastructure Cloud from HashiCorp unifies how you manage infrastructure and security lifecycles across on-premises, hybrid, and multi-cloud environments. It helps you cut through complexity by standardizing workflows, automating security, and providing a single source of truth for your applications and services.

What happens when you start doing cloud right?
Do cloud right with scalable, automated processes that reduce costs and risk while keeping you ahead of the competition. Here’s how HashiCorp helps you move faster and get more value from the cloud with all the right controls in one place.
Accelerate delivery and innovation
Go to market 5x faster without compromising security. The Infrastructure Cloud helps you do cloud right with self-service tools, built-in guardrails, and automated workflows that accelerate app delivery across hybrid cloud environments.

How to start using The Infrastructure Cloud
Getting started with The Infrastructure Cloud means choosing the right mix of HashiCorp products for your team — whether that’s SaaS offerings on the HashiCorp Cloud Platform, self-managed software, or a combination of both.
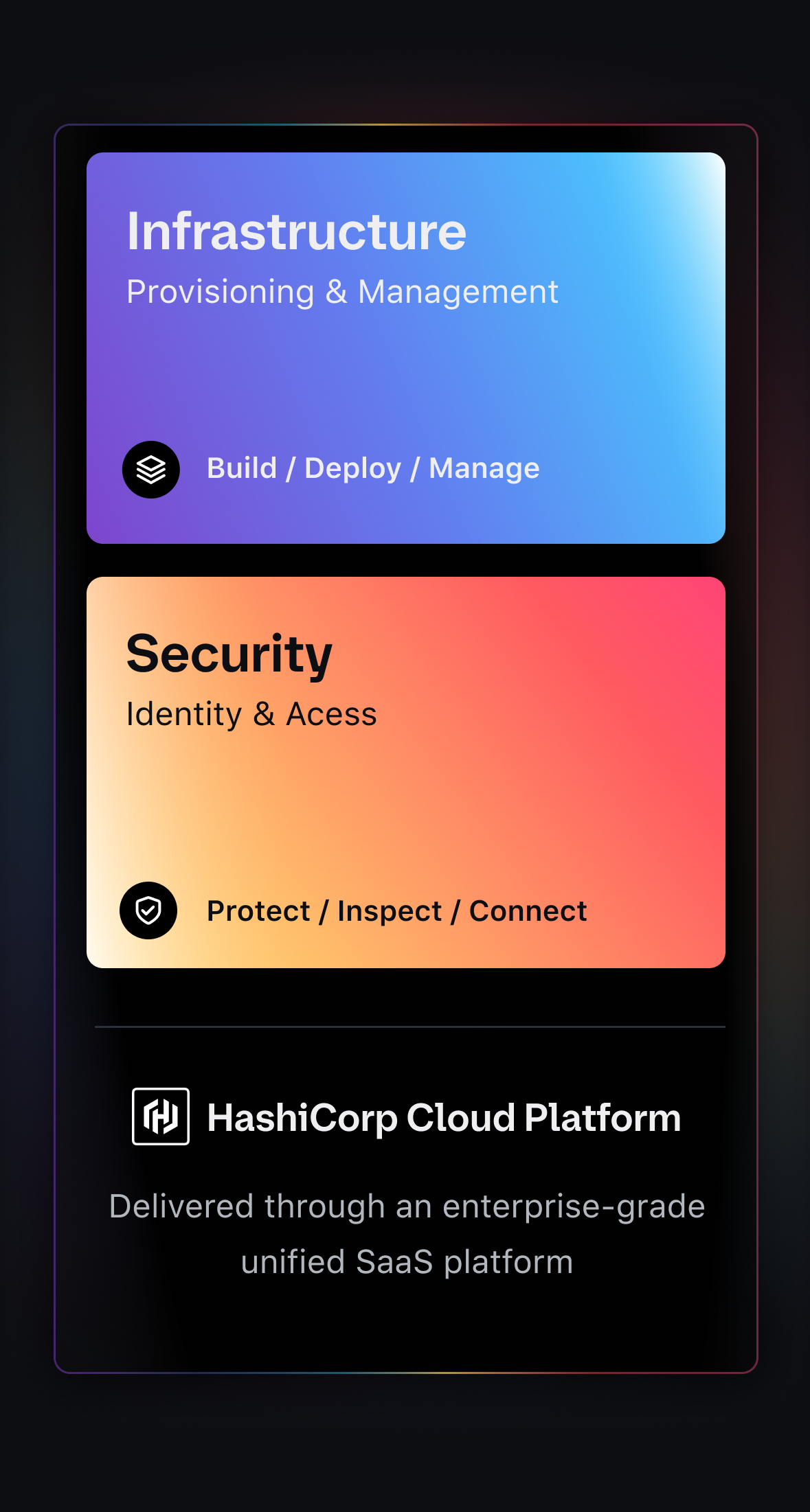
- Operate on one trusted platformBring infrastructure provisioning, identity-based access, and compliance together on the HashiCorp Cloud Platform — built for scale and ready for AI.
- Standardize with ILM and SLMDeliver speed, security, and consistency by unifying Infrastructure and Security Lifecycle Management (ILM and SLM) across all environments.
- Unlock enterprise-grade featuresGo beyond open source with advanced automation, policy enforcement, and governance designed for the world’s most complex organizations.
Infrastructure Lifecycle Management
ILM creates a scalable, modern system of record for infrastructure, built on infrastructure as code. It goes beyond provisioning to enable consistent automation, reusable workflows, integrated cost and policy guardrails, and platform-level visibility across all environments.

Security Lifecycle Management
SLM complements ILM by embedding zero trust principles into infrastructure workflows at enterprise scale. It goes beyond secrets management to deliver identity-based access, dynamic credentials, and automated enforcement of security and compliance policies — all woven into how infrastructure is provisioned and managed.

How leading organizations are using The Infrastructure Cloud
Global enterprises are modernizing how they build, secure, and scale their digital estates with HashiCorp. From accelerating application delivery to strengthening security and optimizing costs, see how organizations are realizing the value of The Infrastructure Cloud.






Get the 2025 Cloud Complexity Report
The 2025 Cloud Complexity Report is out now. Download it now to learn how 1.1k leaders are handling enterprise cloud, security, and AI.