

This is the third in a series Building Resilient Infrastructure with Nomad (Part 1, Part 2). In this series we explore how Nomad handles unexpected failures, outages, and routine maintenance of cluster infrastructure, often without operator intervention required.
In this post we’ll look at how Nomad adds resiliency to your computing infrastructure by providing a consistent workflow for managing the entire job lifecycle, including robust options for updating and migrating jobs that help minimize or even eliminate down time.
»Workflow for operating a job
The Nomad job specification allows operators to specify a schema for all aspects of running the job. This includes tasks, images, deployment strategy, resources, priorities, constraints, service registrations, secrets, and other information required to deploy the workload.

The workflow for operating a job has four main steps:
Create or modify the job file according to the job specification
Plan and review the changes with a Nomad server
Submit the job file to a Nomad server
(Optional) Review job status and logs
When updating a job, there are a number of built-in update strategies which may be defined in the job file. Update strategies help operators safely manage rolling out new versions of the job. Because the job file defines the update strategy (blue/green, rolling updates, etc.), the workflow remains the same regardless of whether this is an initial deployment or an update to an existing job.
The update stanza specifies the update strategy Nomad will employ when deploying a new version of that task group. If omitted, rolling updates and canaries are disabled.
»Rolling and serial updates
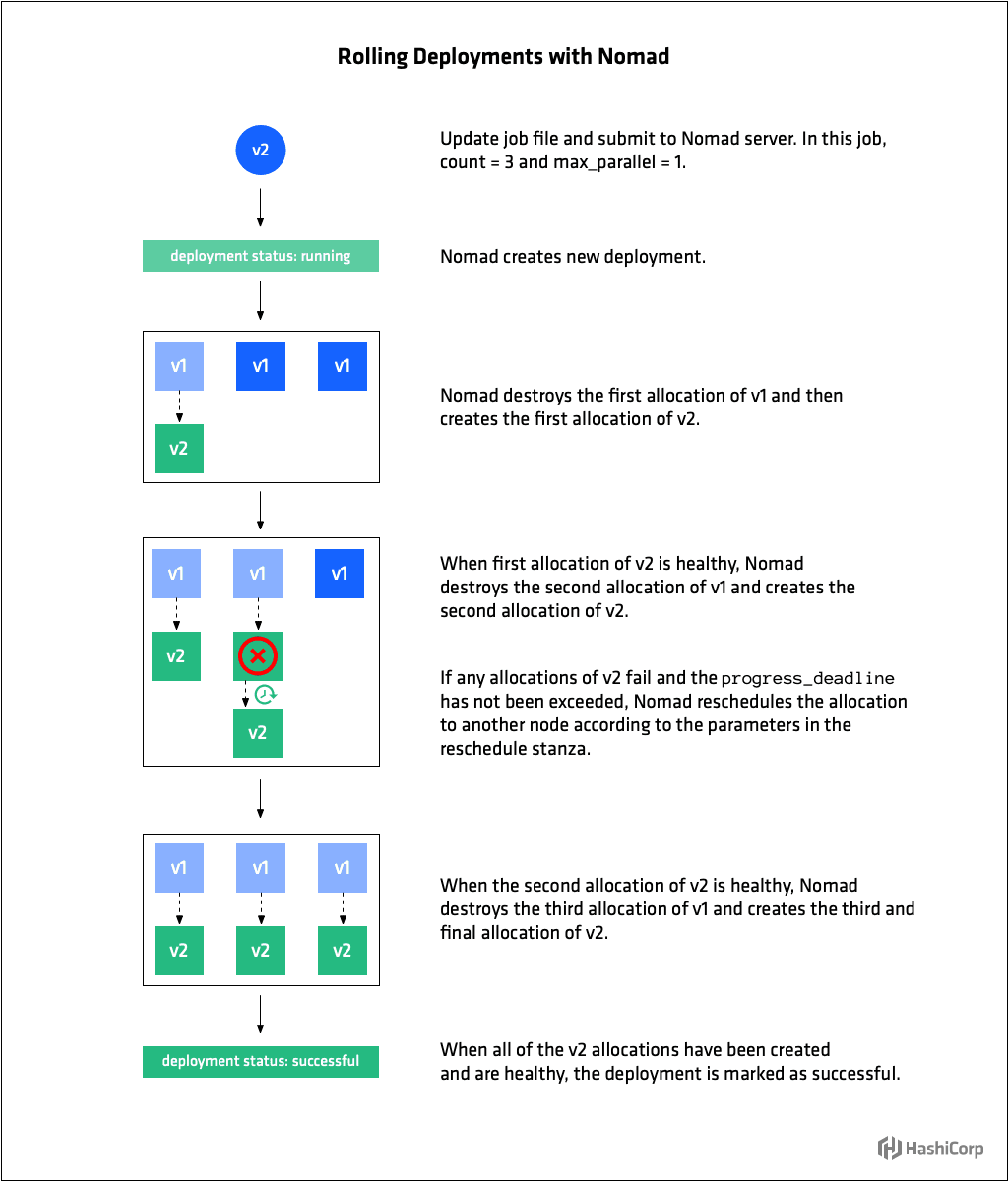
In the update stanza operators specify how many job allocations to update concurrently with max_parallel. Setting max_parallel to 1 tells Nomad to employ a serial upgrade strategy whereby at most one allocation is upgraded at a time. Setting it to a value greater than 1 will enable parallel upgrades, whereby multiple allocation are upgrade simultaneously**.**
When updating, Nomad stops max_parallel number of old allocations and then starts the same number of new allocations. Nomad then waits for health checks on updated nodes to pass before updating the next set of max_parallel allocations.
Use health_check to specify the mechanism by which allocation health is determined. The default value is checks, which tells Nomad to wait until all tasks are running and Consul health checks are passing. Other options are task_states (all tasks running and not failed) and manual (operator will set health status manually using the HTTP API).
Three parameters specify the conditions under which allocations are considered healthy and their deadline for acquiring that state. Use min_healthy_time to specify the minimum time the allocation must be in the healthy state before it is marked as healthy and unblocks further allocations from being updated. Use healthy_deadline to specify the deadline in which the allocation must be marked as healthy after which the allocation is automatically transitioned to unhealthy. Finally, use progress_deadline to specify the deadline by which an allocation must be marked as healthy. The deadline begins when the first allocation for the deployment is created and is reset whenever an allocation as part of the deployment transitions to a healthy state. If no allocation transitions to the healthy state before the progress deadline, the deployment is marked as failed.
If an allocation that is part of deployment fails, as long as the progress_deadline has not been exceeded, Nomad reschedules it according to the parameters in the reschedule stanza. This allows Nomad to gracefully handle transient errors specific to a particular node. Nomad will continue to reschedule until the progress_deadline is hit at which point the issue is likely with the update itself and the entire deployment is marked as failed.
Use auto_revert = true to specify that the job should auto-revert to the last stable version upon deployment failure. A job is marked as stable when all the allocations of its deployment are marked healthy.
The following update stanza tells Nomad to perform rolling updates 3 at a time and to wait until all tasks for an allocation are running and their Consul health checks are passing for at least 10 seconds before considering the allocation healthy. It sets a deadline of 5 minutes for an allocation to become healthy, after which Nomad will mark it as unhealthy. And, if any one allocation fails to become healthy after 10 minutes, the entire deployment will be marked as failed and Nomad will auto revert to the last known stable deployment.
job "example" {
update {
max_parallel = 3
health_check = "checks"
min_healthy_time = "10s"
healthy_deadline = "5m"
progress_deadline = "10m"
auto_revert = true
}
}For system jobs, only max_parallel and stagger are enforced. The job is updated at a rate of max_parallel, waiting stagger amount of time before the next set of updates.
»Canary deployments

Canary updates are a useful way to test a new version of a job before beginning a rolling upgrade. The update stanza supports setting the number of canaries the job operator would like Nomad to create when the job changes via the canary parameter. When the job specification is updated, Nomad creates the canaries without stopping any allocations from the previous version of the job.
This pattern allows operators to achieve higher confidence in the new job version because they can route traffic, examine logs, etc, to determine the new application is performing properly.
When canary is set to 1 or more, any changes to the job that would result in destructive updates will cause Nomad to create the specified number of canaries without stopping any previous allocations. Once the operator determines the canaries are healthy, they can be promoted and Nomad will proceed with a rolling update of the remaining allocations at a rate of max_parallel. Canary promotion can be done manually by an operator, or automated using the APIs.
The following update stanza tells Nomad to perform a canary update with 1 canary and once that canary has been promoted, to perform rolling updates 3 at a time for remaining allocations.
job "example" {
update {
canary = 1
max_parallel = 3
}
}»Blue/green deployments

Blue/Green deployments have several other names including Red/Black or A/B, but the concept is generally the same. In a blue/green deployment, there are two versions of the workload deployed. Only one version is active at a time, except during the transition phase from one version to the next. The term "active" tends to mean "receiving traffic" or "in service."
Blue/Green deployments are enabled in Nomad by setting the value of canary in the update stanza to match that of count in the group stanza. When these values are the same, instead of doing a rolling upgrade of the existing allocations when a new version of the job is submitted, the new version of the group is deployed along side the existing set. The operator can then verify that the new version of the group is stable. When satisfied they are, the group can be promoted and all allocations for the old versions of the group will be shutdown. Blue-green deployments duplicate the resources required during the upgrade process, but enable very safe deployments as the original version of the group is untouched.
The following update stanza tells Nomad to perform a blue/green update by launching 3 canary allocations (same number as count ) while the previous allocations are still running.
group "cache" {
count = 3
update {
canary = 3
}
}Nomad’s job lifecycle, including update, allows operators to minimize disruption to their infrastructure by employing the best update procedure(s) for their situation, be it rolling upgrades, canaries, or blue/green deployments. Operators can mix and match and change deployments types without having to change their cluster management workflow.
»Migrating tasks and decommissioning nodes
In Part 2 of this series, we talked about how Nomad detects when a client node has failed and automatically reschedules jobs the jobs that were running on the failed node.
When you know a node needs to come out of service, you can decommission, or “drain” it with the node drain command. This will toggle drain mode for a given node. When a node is marked for draining, Nomad will no longer schedule any tasks on that node and will begin migrating all existing jobs to other nodes. Draining continues until all allocations have migrated off the node or the deadline is reached at which point all allocations are force migrated off the node.
Job authors can use the migrate stanza to specify Nomad’s strategy for migrating tasks off of draining nodes. Migrate directives only apply to service type jobs because batch jobs are generally short-lived and system jobs run on every client node. For jobs with a count of 1, it is not necessary to supply a migrate stanza. Because there is only one instance of the job, it will be migrated immediately upon initiating the drain.
Use max_parallel to specify the number of allocations that can be migrated at the same time. This number must be less than the total count for the group because count - max_parallel allocations will be left running during migrations. Use health_check to specify the mechanism by which allocation health is determined. As with update , the default value is checks, which tells Nomad to wait until all tasks are running and Consul health checks are passing. The other option is task_states (all tasks running and not failed). There is no manual health check option for migrate.
Node draining will not continue until replacement allocations have been healthy for their min_healthy_time or healthy_deadline is reached. This allows a large set of machines to be drained while ensuring that the jobs on those nodes don’t incur any downtime.
The following migrate stanza tells Nomad to migrate one allocation at a time, to mark migrated allocations healthy only once all their tasks are running and associated health checks are passing for 10 seconds or more within a 5 minute deadline.
job "example" {
migrate {
max_parallel = 1
health_check = "checks"
min_healthy_time = "10s"
healthy_deadline = "5m"
}
}The migrate stanza is for job authors to define how their services should be migrated, while the node drain deadline is for system operators to put hard limits on how long a drain may take.
Node draining is a routine part of cluster maintenance that occurs due to things like server maintenance and operating system upgrades. In a traditional datacenter, operators need to coordinate node maintenance with developers to ensure an outage is not caused. Nomad instead allows developers to control how applications are migrated, so that operators do not need to coordinate tightly when doing cluster maintenance.
For further details, see Decommissioning Nomad Client Nodes and Advanced Node Draining With HashiCorp Nomad.
»Summary
In this third post in our series on Building Resilient Infrastructure with Nomad (Part 1, Part 2), we covered how Nomad adds resiliency to your computing infrastructure by providing a consistent workflow for managing the entire job lifecycle, including robust options for deploying updates and migrating jobs that help minimize or even eliminate down time.
The update strategy for jobs is controlled by the update stanza of the job file. Operators can configure a number of options for safely managing updates, including: serial and parallel updates, canaries, and blue/green deployments. Nomad gracefully handles transient issues during deployments by automatically rescheduling failed allocations until the deployment’s progress_deadline has been met.
The migrate stanza enables job authors to specify Nomad’s strategy for migrating tasks off of draining nodes. This helps operators perform cluster maintenance without having to coordinate tightly and to execute the draining of many nodes without incurring downtime.
In the next and final post of this series, we’ll look at how Nomad provides resiliency against data loss, and how to recover from outages.







