The Two Million Container Challenge
HashiCorp Nomad scheduled 2,000,000 Docker containers on 6,100 hosts in 10 AWS regions in 22 minutes.
»Intro
In March 2016, we demonstrated HashiCorp Nomad could run 1 million containers across 5,000 hosts. Four years and 10 major releases later we set out to replicate the original challenge at higher scale:
C2M | Original C1M |
Nomad 1.0 | Nomad 0.3.1 |
2 million containers | 1 million containers |
6,100 AWS Spot Instances | 5,000 GCE Instances |
3 Schedulers | 5 Schedulers |
10 AWS Regions | 1 GCE Region |
Nomad, borrowing terminology from Google’s Borg scheduler, refers to its basic unit of work as a job. Each job is composed of many tasks. A task is an application to run, which is a Docker container in this test. Nomad can also schedule other tasks such as VMs, binaries, etc, but only Docker containers were used as part of C2M.
Thank you to the AWS Spot team for providing the credits and support necessary to run the infrastructure for C2M on AWS.
»C2M Results
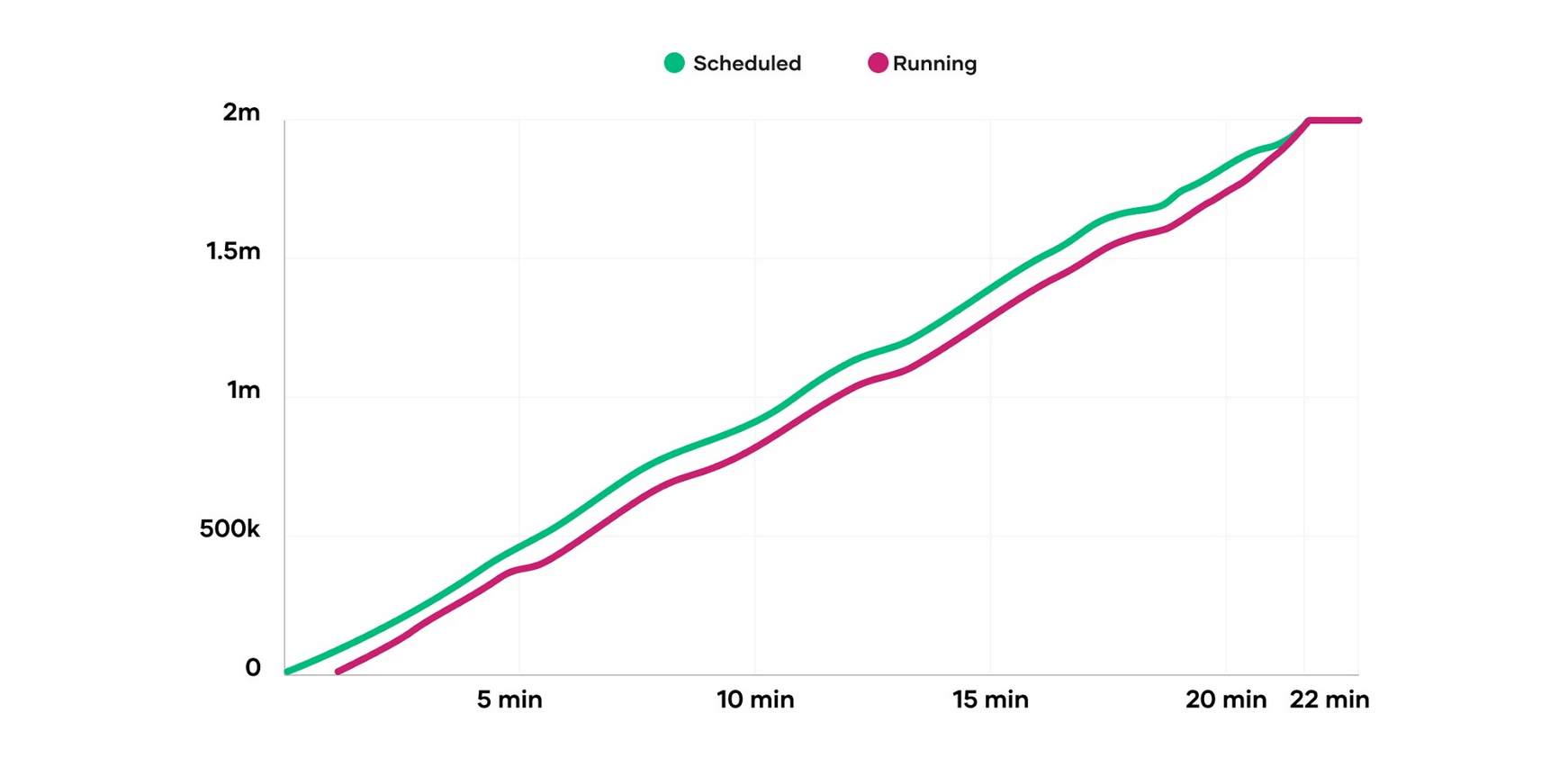
Nomad scheduled 2 million containers in 22 minutes and 14 seconds at an average rate of nearly 1,500 containers per second. The above graph demonstrates Nomad’s scheduling performance is nearly linear. The number of containers already placed does not negatively affect the placement of future containers. In the graph above, the Y-axis is the number of containers and the X-axis is the elapsed time. The first line, Scheduled, represents when a container was assigned to a node. The second line, Running, represents when a container was running on its assigned node.
»A Global Deployment on AWS Spot
Our partners at Amazon Web Services generously provided the credits to run C2M on AWS with all of the workloads placed on AWS Spot Instances. EC2 Spot was chosen for this project as it offers savings of up to 90% with no commitment other than pay-by-the-second on the same AWS EC2 instances used by On-Demand. Spot instances are spare capacity sold at a discount and may be interrupted by AWS should supplies diminish. Stateless, fault-tolerant, and decoupled workloads are a great fit for Spot, and are a common model within container workloads on Nomad, as well as other scheduling platforms. Total costs for this run were reduced by 68% in aggregate using popular instance types and sizes in a mix of day and night locales. The following map shows the location of all instances with the white dot representing the schedulers colocated in us-east-1 region (in North Virginia).
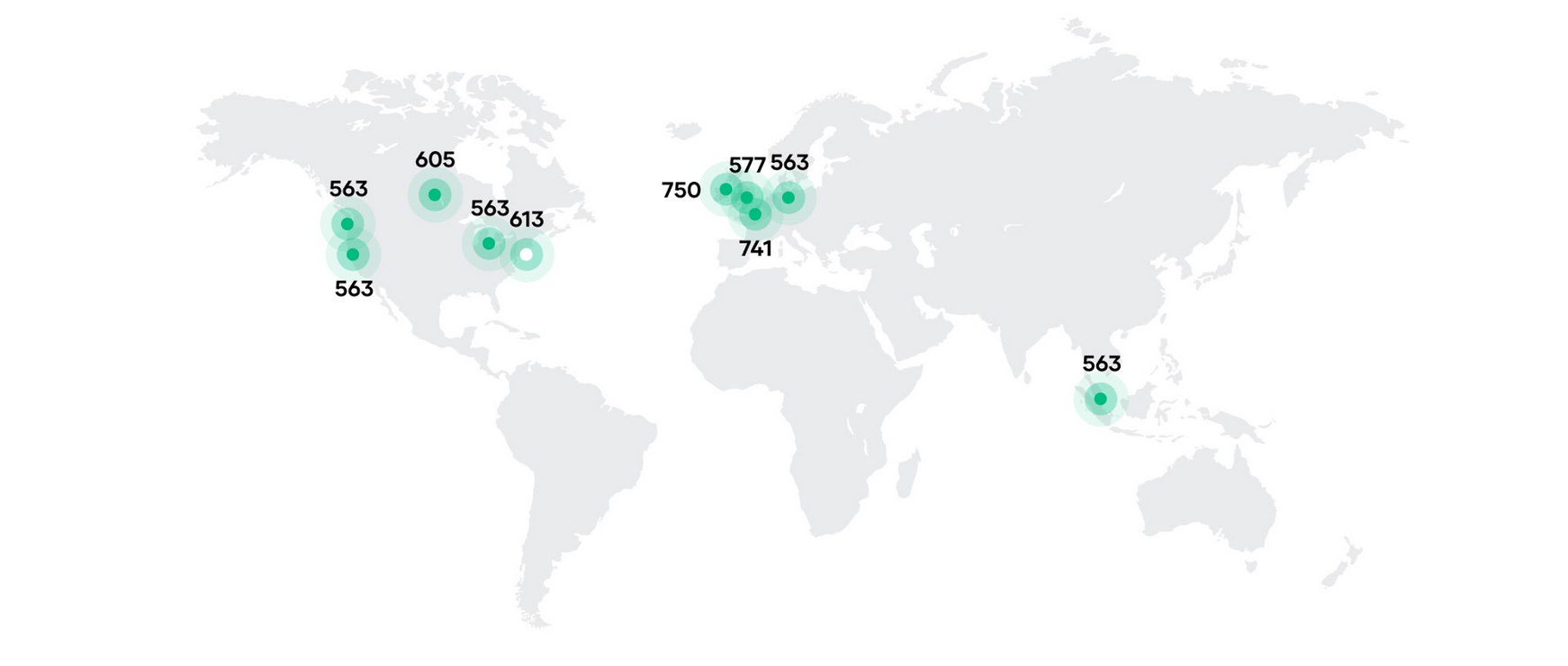
Spread across 10 AWS regions that spanned the globe, a distinct auto-scaling group (ASG) was created in each to launch the client virtual machines. Target capacity for each ASG was requested by specifying 18 TB of RAM, the restraining resource for the test deployment, rather than machine or CPU count. Having defined multiple instance types that could contribute as clients in the Nomad cluster, AWS used a capacity-optimized allocation strategy to provision instances from the deepest pools of machine types in each of the different availability zones across the 10 regions. The capacity-optimized allocation strategy can add to the durability of Spot instance fleets. In this particular test, however, none of the 6,100 instances were interrupted.
In the chart below, you can see how that footprint spread across instance types in each region. Learn more about Spot instances here.

The 3 i3.16xlarge instances represent the 3 Nomad schedulers on reserved instances. The single m5a.large was a reserved instance used for command and control of C2M’s test harness. All other instances were Spot instances provisioned by the ASG. The speed with which ASG can provide thousands of hosts made iteratively developing and testing C2M possible. All 6,100 instances were running and registered as ready to receive work from the Nomad schedulers within 6 minutes and 30 seconds.

C2M was run once all 6,100 instances had registered.
»Differences from C1M
Nomad has evolved significantly from version 0.3.1 used for C1M back in 2016 to the 1.0 beta used for C2M. While C2M tried not to diverge drastically from C1M, we did try to evolve our benchmark to focus more on Nomad’s global scalability and less on raw scheduling throughput (containers placed per second). We shifted our focus as we learned that Nomad’s throughput already exceeded users’ expectations, deciding that Nomad’s global scalability offers more relevant infrastructure opportunities.
»Scheduling Algorithm
Nomad 0.11 added the option to use a spread scheduling algorithm as opposed to the default binpacking algorithm. The benefit of binpacking algorithms is that they optimize placements to use the minimum number of nodes. The result is that services are run using the fewest nodes possible, saving costs. However, when using a pre-existing cluster of nodes, there’s no reason to binpack on a subset. In this situation, a spread algorithm is optimal as it evenly distributes work across all available nodes.
Both C1M and C2M created clusters before running containers, but while C1M only had the binpacking algorithm available, C2M could use the more appropriate spread algorithm. Spread and binpacking have unique scheduling performance characteristics as well. Concurrent schedulers, especially when scheduling identical workloads as in these benchmarks, are much more likely to make overlapping optimistic placements when using binpacking than when using spread. This means the leader must reject more attempted placements, causing binpacking to make more scheduling attempts per container than spread.
C1M partially avoided this performance penalty by manually sharding containers across arbitrary sets of nodes using node class constraints. C2M could avoid this specialization and required no templating in its test job file.
However, spread incurs a different performance penalty: since containers are more evenly spread among nodes, more nodes are reporting container status updates to schedulers. These updates are serialized via Raft and therefore are limited by disk IO throughput. During binpacking, once a node is full and all of its containers are running, it no longer needs to send container state changes to the schedulers. When spreading containers evenly over all nodes, all nodes are consistently reporting state changes to schedulers. Since C1M manually spread containers it faced similarly high rates of updates. Overall, spread’s benefits to optimistic scheduling appear to far outweigh the penalty of increased node update load.
»Journey
The test harness, codenamed Journey, was adjusted to favor stability over throughput. While C1M’s test harness registered all jobs as quickly as possible and reached placement rates of 5,500 containers per second, C2M’s test harness favored a consistent time-to-running. Therefore while the majority of C1M’s benchmark time is dominated by waiting for containers to start, C2M more evenly paces scheduling with containers running. Since cluster state is kept in memory on each Nomad scheduler, scheduling is a largely CPU-bound process. As you can see from the graph of scheduler CPU usage, all of the schedulers have spare capacity. Tweaking our test harness may produce higher scheduling throughput.

»C2M Setup
C2M infrastructure was provisioned with HashiCorp Terraform with an AWS auto-scaling group providing the desired node capacity using Spot instances. Schedulers were provisioned with On-Demand i3.16xlarge instances as we did not intend benchmarks to include leader elections which would be more likely using interruptible Spot instances.
All assets to provision and run C2M may be found on GitHub. These include the HashiCorp Packer templates, Terraform files, Journey test harness (Go), Test jobspec, and associated scripts.
»Global Cluster Topology
Nomad is designed for global scale. While Nomad schedulers should be colocated in a region, spread across availability zones for high availability, the Nomad nodes which run workloads may be globally distributed.
Nomad schedulers (“servers” in Nomad terminology) were colocated in the North Virginia (us-east-1) region spread across 3 AZs. Since Nomad schedulers benefit from CPU capacity and low latency disk writes, i3.16xlarge On-Demand instances were used with Nomad data on the NVMe SSD-backed instance storage.
Nomad nodes (“clients” in Nomad terminology) were spread across 10 regions and a total of 32 Availability Zones. All nodes were managed by an AWS ASG with 13 instance types weighted by memory: m4, m5(a), and t3(a). Sizes ranged from xlarge to 4xlarge.
Nomad nodes connect to schedulers and all communication takes place over bidirectional RPC using a single TCP connection. This means Nomad nodes did not require public IP addresses and used a NAT Gateway when connecting to the schedulers. By default Nomad schedulers limit individual IP addresses to 100 TCP connections for RPC. Due to hundreds of nodes connecting from a single NAT Gateway the RPC connection limits were disabled.
Nomad schedulers automatically adjust the rate at which nodes must heartbeat before they are considered “down” and their work is rescheduled. The larger a cluster, the longer between heartbeats to ease heartbeat processing overhead on Nomad schedulers. This feature allowed C2M to use the default heartbeat parameters. Global roundtrip times do not have a detrimental effect on Nomad nodes.
mTLS forms the basis of Nomad’s network security. C2M secured all communication, whether over the public Internet or within a single region, with mTLS.
»Jobspec
The job file is a basic Docker container using the Alpine image. Since container performance (once running) was not part of our benchmark goals, a simple sleep command is executed and minimal resources are allocated (50 MHz and 30 MB memory). Two significant exceptions to normal best practices were made in the test job file:
Deployments were disabled to match C1M and increase throughput.
No networks were specified to match C1M and increase throughput.
These characteristics are common in batch workloads, but not best practice for production service workloads.
Every job that uses Deployments must monitor cluster state and perform processing every time a container for that job changes state (such as running successfully or crashing). Without deployments, containers are updated as quickly as possible regardless of their health. Since C2M does not update existing jobs, the cost of monitoring deployments offered no benefits. Since Nomad had not implemented deployments when C1M was performed, deployment overhead was avoided in both C1M and C2M.
Similarly, since the benchmark container did not perform any network operations, networking was skipped. Nomad inherits Borg’s design of assigning ports on a node to jobs that request them. This means Nomad’s scheduler must track which ports are already in use on each node. C1M did perform network operations but used the “host” networking mode since only outgoing connections were made and port accounting was unnecessary.
»Scheduler Disk IO
Nomad’s scheduler keeps all cluster state in-memory. All state changes are performed via the Raft consensus protocol to ensure consistent state even if one scheduler crashes. Cluster state must be persisted to durable storage (disk) in case all schedulers are down simultaneously. Nomad periodically snapshots its state to disk as well as maintains a write-ahead log (WAL) of Raft messages to recreate cluster state on scheduler restart.
Nomad uses multiple concurrent scheduling threads spread across all scheduler servers to optimistically propose container placements. The optimistic scheduling process is almost entirely CPU-bound since it operates on the in-memory cluster state. However, since these placements are optimistic they must be serially validated by the Raft leader and committed by a quorum of schedulers before moving on to the next placement.
IO utilization during C2M was high for the majority of the scheduling work as placements were made and container state updates were received from Nomad nodes. The variable nature of the IO graphs is likely due to the periodic snapshotting of in-memory cluster state on top of the constant small Raft WAL writes.

»Scheduler Memory Usage
Since Nomad’s schedulers maintain the entire cluster state in memory, RAM is a significant consideration when provisioning Nomad clusters. C2M demonstrated that Nomad scheduler memory usage scales linearly with the number of containers scheduled.

Prior to scheduling any containers, the Nomad schedulers used 3.5 GB of memory (RSS). The majority of the initial memory usage was tracking the 6,100 nodes. Nomad schedulers without running nodes or workloads use less than 100 MB of memory.
Nomad schedulers do not need memory reserved for disk caching. Except when restarting schedulers, Nomad only writes to disk, so unlike many other data-intensive applications, operators do not have to reserve a large amount of memory for disk caching. Disk caching optimizes reads as well as writes, which do not have to be immediately flushed to durable storage. Neither affects Nomad schedulers at runtime.
The Go runtime’s garbage collector performed exceptionally well with few pauses over 10ms. Pauses are when Go’s memory garbage collector must prevent (“pause”) any new allocations while performing part of its garbage collection process. Garbage collection pauses are a notorious source of problems for distributed systems as little-to-no application work can be done and therefore their impact is similar to that of a temporary network partition. However, the longest pause Nomad’s schedulers observed was 50ms with an average pause time under 1ms. These pauses are at least an order magnitude away from causing issues aside from decreased scheduling throughput. By default pauses over 100ms may negatively impact the performance of Raft, and pauses over 1 second would appear as network partitions to the other schedulers. However, the raft_multiplier configuration parameter may be tuned higher than its default of 1 if long pauses or network partitions are a concern. C2M used a raft_multiplier of 5 out of an abundance of caution, but we observed no pauses or anomalies that would require this tweak.
»Conclusion
At HashiCorp, we build solutions to problems that are technically sound and are a joy to use. We do not take shortcuts with the technologies we choose. C2M is a public showcase of our approach and commitment to creating software designed to scale.
Nomad and AWS Spot instances offer optimal cost-efficiency for compute capacity. We hope to demonstrate more Nomad and AWS joint use cases in the future. We will also collaborate with other organizations and innovative technology companies on cutting-edge research to continue to push the performance of Nomad.