Managing a golden image factory across all major cloud platforms at Experian
Learn how Experian manages machine image governance and standards across AWS, Azure, Google Cloud, Oracle Cloud, and Alibaba Cloud.
»Transcript
Thanks a lot for joining me in this last talk. I'm the Principal Cloud Automation Engineer at Experian. Today, I'm going to walk you through the process we have for our golden image factory.
But before going through that, I wanted to talk about one of my passions, and that is hiking. If you have done hiking before, probably you know that it requires some level of preparation depending on what type of hike you're doing.
If you're a beginner, or if it is a more advanced one, you might need to take your hiking poles. If the weather is cold, you need to make sure you wear layered clothes and all of those things. In my case, I like the ones that require more preparation than the others — so, the more advanced ones.
First, I'm from Costa Rica. This picture here is from one of the hikes I did three months ago. This is in the Chirripó National Park, and this place specifically is called Cerro Crestones. It wasn't an easy hike at all. It took us two days to get here. It was a lot of effort. My whole body was really in pain, and it was a lot of steep hills that we needed to walk through.
I have a friend that usually tells me I like extreme adventures or something that is dangerous, but I think it's more about the challenge. Once you overcome all of those challenges and you get to that place, you get to this imposing landscape. You notice that it's worth the effort.
»Journey to a multi-cloud environment
I feel that it's the same when you go through the cloud journey. In our case, when we were starting five or six years ago on this journey and of getting on the cloud and offering cloud environments to our customers, it was exploring. Understanding the need, working with our other engineers — with the people from security, from architecture — to know what we need to do to make sure that we would be providing secure environments to our customers.
In this case, we started with one cloud. It was just AWS. We were just five engineers at the time, but then we started getting other requirements. It started getting a bit more difficult. The trail was steeper now, so we started getting requirements for other cloud platforms like Azure, GCP. So, how were we going to be providing environments for those different landing zones?
We also had customers with different cloud skill levels. In our case, it's a full organization that we are supporting. There will be customers that are really mature in the cloud — that have been there probably even before our team came to provide this set of standards and security. Then there are other customers starting to engage into the cloud. They were probably migrating from on-prem, or they started to play a bit on the cloud platforms.
»How it all began
You might have thought when I was saying the major cloud platforms just like AWS, Azure, and Google Cloud, that is a little bit more than that. We also have Oracle Cloud and Alibaba Cloud.
And not just that, we also are a global company. We need to make sure these different variables here — for PCI, login, security, monitoring, governance — are all included in the whole cloud environment. Not just in our cloud general configuration but also on the images we provide to the customers.
These images need to be easy to use. It's not like they would need to do something manual after they launch them to make them compliant. Everything should be in place and correctly configured even if they go to deploy it in the US or in South Africa.
»Automating the process of a global multi-cloud golden image
We defined this process that you see here. This is a monthly process, but it could happen out of cycle. As you know, in Windows, sometimes there might be some specific vulnerabilities that happen out of cycle, like MVP1 vulnerabilities. So, of course, we can run our full pipeline automation to build the images across the world.
How is this going to work? We're going to have Packer, which is going to be building those images from the cloud marketplace images. This one is going to be the vendor-offered images, which is going to get us the latest ones.
Then, thanks to Packer, since the ACL language, it's easy to simply provide the specific variables we need for each of the different builders in AWS, Azure, GCP. That's one of the first levels. We have our Packer build level for each of the cloud platforms, our HCL language. And in HCL, we provide those regions and what we need on this image.
Then, we use the Packer provisioner. In this case we use Ansible to pull the latest security agents we need into that image — like the virus scan agent, observability agents, or any agent we need for security scans as well. That's all going to be embedded into that image.
We also need to make sure that the image is hardened. We use the CIS benchmarks as a base to know what we need to configure so it is secure. I'm going to be talking about that in a minute there.
We get the image built. We need to make sure it is built on all the cloud platforms. But we also need to make sure it is going to be properly configured in the post-build phase. As part of the build image we need to make sure there is a file that lets us know which cloud platform this image is being built on because we're going to use it later.
Then the other part, once this image is built, we're going to review that all of the tests pass. We have some integration tests we developed along with another team. Then we need to make sure the image is free of vulnerabilities. Once we know there might be vulnerabilities that are there but haven’t been fixed by the vendor — we document any changes. There could be new features as well.
Once that's done, we publish those images across the board, across all of those regions, and all of our organizations, and we communicate. Of course, in this case — thanks, Packer — we don't really need to know that deep into the new essence of each of the cloud platforms since Packer does this abstraction for us.
»Integration tests — validations
As I was saying before, this is a little bit beyond just building the image. We also need to make sure that this image is not broken. I'm saying this because we had times where we built an image today, and maybe we didn't do any changes, and then next month, for some reason, it doesn't work.
Last month, on Windows, we built a new image, and it wasn't accessible for some reason. I don't have anything against Windows either, but that happens. So, we need to make sure that the different services, that the instances, get up— that's one of the things. Then we start getting the other tests:


»Observability
Making sure that the monitoring agents are working. In our case, we are working on a private network, so making sure that the firewalls are in place and the connectivity works so these agents can reach the different management servers. Then, we need to make sure that's also reviewed as part of these integration tests.
»Security and inventory
The same for the endpoint security tools, virus scan tools, and anything related to security is going to be in place. Inventory: We have certain conditions for the instance to get discovered on our CMDB database as well.
»Authorization
We manage our privileged accounts on Vault, and we need to make sure that's working — we need to make sure users can authenticate and it actually works. I think that last month it happened, and we had been reviewing that from the UK. Some customers couldn't SSH into the instances because of a problem with the crypto policies that we needed to change due to the hardening. That's also something we are reviewing to improve as well on the authorization. There's always something that we can evolve on.
»Hardening
We make sure all of those benchmarks from CIS are in place. Some of those things could be something like ‘you cannot SSH into the instance with brute usage,’ that should be disabled. There is an LBM partitioning scheme you need to follow with /tmp/var/home. They are all in their separate partitions. So, that's something we add as well. And file integrity monitoring should be enabled for PCI workloads. We also need to make sure that is in place.
»Vulnerability results
The vulnerability scanning tool has an API that we're using. With this API, we are pulling the details on vulnerabilities that are found, if any. Hopefully, we don't have any. But, as I mentioned before, there may be a new vulnerability that hasn't been resolved by the vendor, and we need to document that.
This API gets those results. In this case, this is an example from an Amazon Linux to an image where, at that point in time, it didn't have a fix for this specific vulnerability — and we provide a link to the report. Why am I showing this? This is an object from the table where we upload those results.
But it would actually show like this — it's a page that we are embedding in our documentation place. We have an API gateway, which pulls that data from our NoSQL table. So, in this case, when customers are auditing — if there is an auditing team that will also be interested in these kinds of reports — when they come here, and they click view report, they should be able to download the report that we got. Hopefully, that's usually not the case.
»Managing versions on HCP Packer
We have been exploring a little bit on HCP Packer. This has been mind-blowing. Something that you should know if you started with Packer really early, like me, if you were using the JSON format, you should migrate to HCL. And even if you don't use HCP Packer, it's a great idea. It has a lot more features, and you can add a lot more logic into your code.

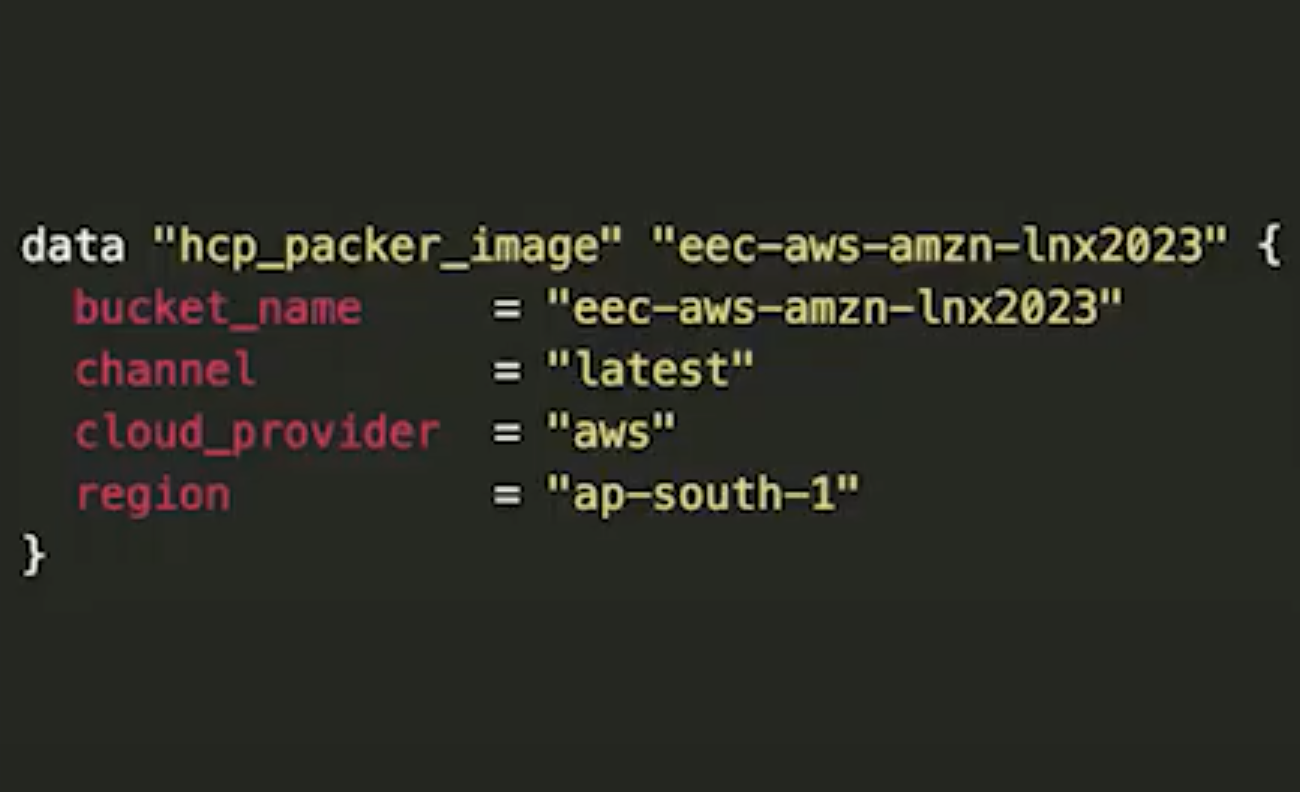

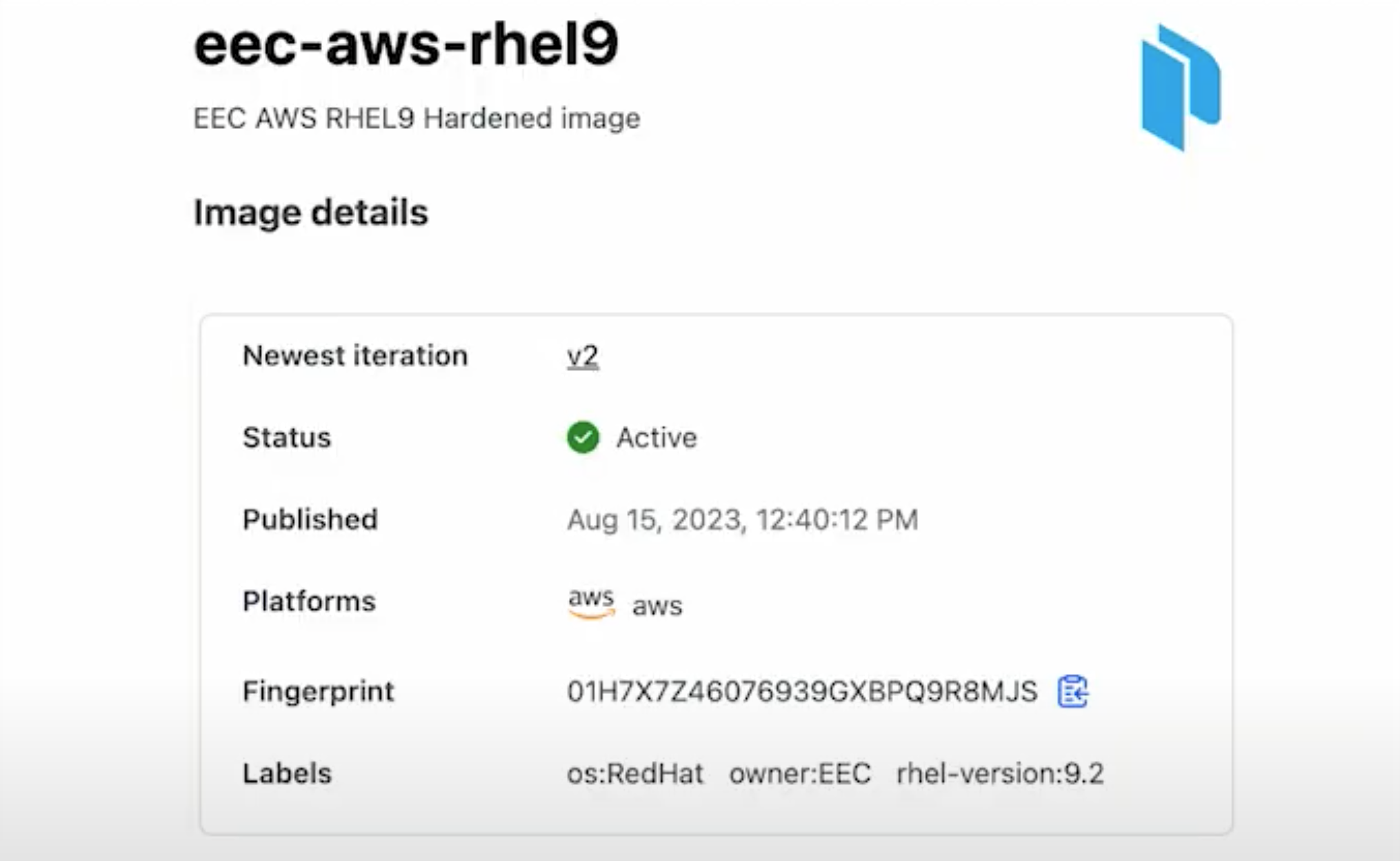
This is an example of one image we built with HCP Packer. Something useful for us is that the customers know when the image is owned by our team. Our team is called EEC. That stands for Experian Express Cloud. When you go to the image version (it was huge, so I couldn't fit it on the presentation) you will see all the regions these images are available on. In our case, it was 13 regions — it was never-ending.
Something pretty neat, as well: When you use it on Terraform, you can simply use a data source from HCP Packer to pull the latest image from that channel. You just need to provide the specific region of the image you need to use. That's going to give you the idea you can use later to build your instances.
»An obstacle in our path
But not all the paths are so easy. It's not all unicorns and flowers, I think someone said before. I think three months ago, we had an issue on an LBM for Amazon Linux 2023 and Rail 9. The issue was that — and this time, it's not a problem with Windows, it was on Rail 9 and the latest major version.
That's mostly because in AWS, specifically, when you change the instance type, the device name changes. So, when the customers were deploying new instances with the new instance type, and they tried to change the precise partition, they were getting a device not found error. Of course, that image was buggy, so we didn't want to run it. We had to fix it. And we needed to make sure that the previous image was not going to be available for the customers.
HCP Packer achieves that easily. And in our case, since we manage it through all of those regions, this helps a lot. In a single click, I can just remove it from the iteration. You can also schedule a removal, if you want, in front of the images that are way too old. That's definitely useful on the image lifecycle as well.
»Post-build automation logic
Once that image is built, then it needs to be used by our customers — and it should be easy for them to use. They shouldn't think about how to configure each of the things that are going or each of the agents that are coming into that image.

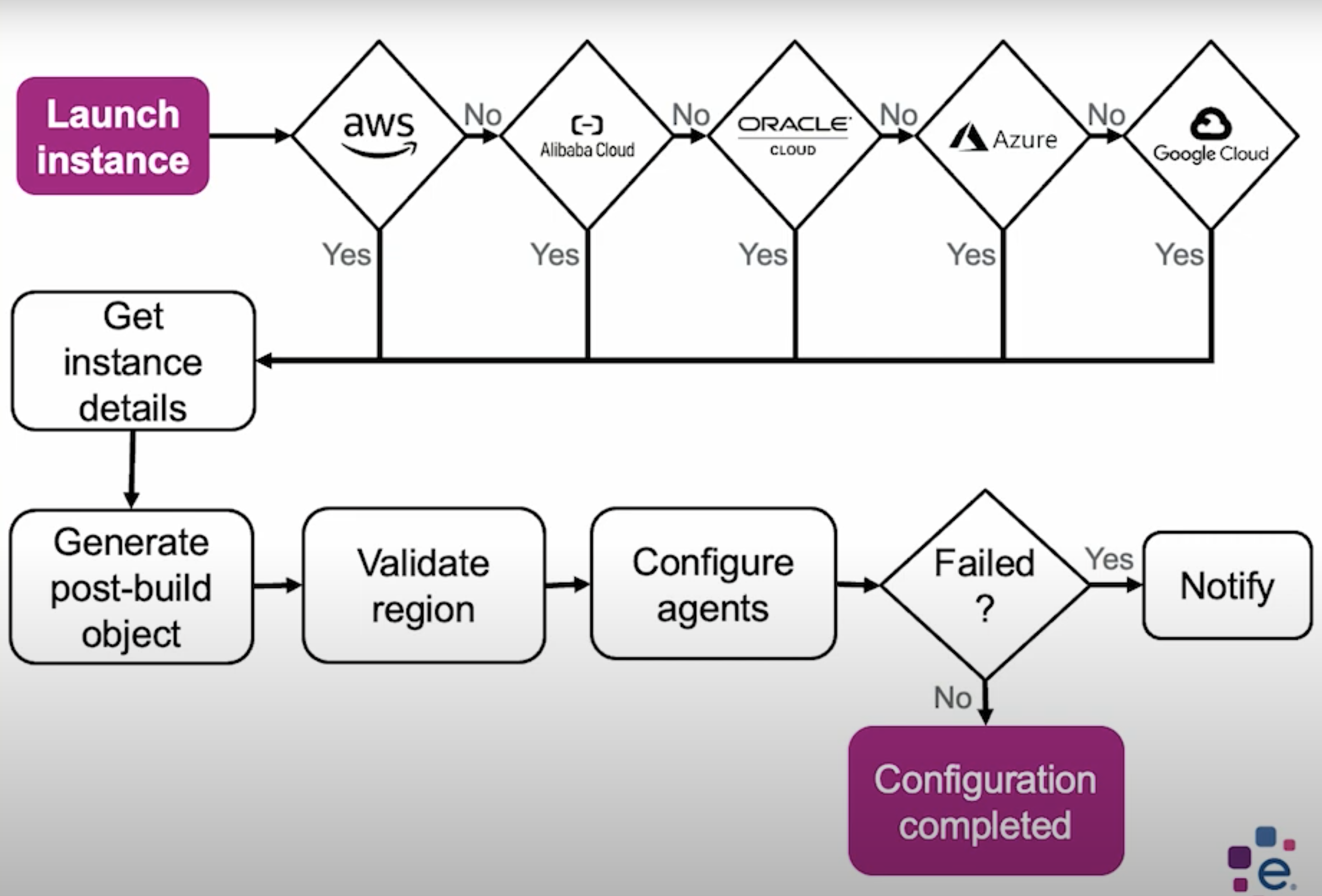
As I was saying before, we have a file first of all, that we get into the images to know what cloud platform it is running on. We have some logic in our Ansible playbook that's going to get the instance details based on that. So, what are the instance details? That would be the region. We also get the instance stacks. If it is in AWS, the EC2 stacks. If it is in Oracle cloud, it is the compute instance stack.
We build an object — like a JSON object — and based on that, we start configuring the agents through different roles in our Ansible playbook. If it fails, we notify the customers why it failed. Sometimes, it could be they provide a wrong value on the tag or something like that, and if not, they will get a completely configured instance — so, without much effort.
To give you an example, from one of the stacks — it could be for logging. Customers can provide an index that they can monitor. We can get that index from the tags and provide some custom configuration for them based on that. That's similar for the other agents that we support. There is a separate job as well that registers the DNS.
»Instance decommissioning process
We have a new image build. Just guest customers are using it. But in the cloud, the environment is usually really dynamic. So, we have a process that when an instance is terminated, it's going to trigger an event, and run a workflow. I am on the LAN icon there, but it's any kind of functions from the different cloud platforms. So, Google Cloud will be the cloud functions with POP and SAP integration, and so on.
This is going to call our Ansible workflow, which is going to get all the details from the instance. So, from our database, it's going to know what is based on the instance ID. It's going to know the name, if it had an AD object created, and those kinds of things — so we can clean it completely from our environments. Otherwise, we're wasting those licenses for an object that doesn't exist anymore. And finally, we remove the DNS record, so everything is completely clean.
»Embrace the challenge
In conclusion, take advantage of cloud-agnostic tools for your automation. In our case, Packer, of course, Terraform — when we test those images by the way we use Terraform. And we are excited and interested in Terraform stacks because of our huge environment and all those regions I mentioned.
Something else that is important if you are probably not the person who is building those images. We have a lot of customers that have been using our images as well, they have been re-hydrating their environment. They are really mature in the cloud, so they have all their automation to support this. But we also have other customers that are not there yet, and honestly, they're having a hard time just trying to keep patching them. But as you know, in the cloud, if something doesn't work, just destroy it and re-create it.
As you know, this is a lot of effort as well. For me, as I was saying before, I'm doing a hike, and all of that effort, when you come to this part that is a bit more stable, and you can see the landscape, you know that all of that effort was fully worth it.
But as humans, we are never comfortable with where we are. We need to move to the next big mountain. Same in our case, we'll keep evolving our process and make it more automated.
Thanks everyone for your time today. If you have any questions or if you want to discuss, let me know. We can either meet in the hallway, or there's also my LinkedIn profile. You can find me as Natalia Marine on LinkedIn. You can also add Natalia Marine Experian, and you'll find that it's the first thing that you'll see. Thank you very much. Goodnight.



