

Improving application resiliency is a particularly difficult challenge for many organizations. Some organizations attempt to improve resiliency by deploying additional infrastructure (such as load balancers), abstracting application responsibilities, and/or changing the application code. In many cases, however, the intended solutions introduce new complexity to the application architecture and don’t actually lead to significant improvements in resiliency.
One method for improving application resilience without deploying additional infrastructure or making application changes is to deploy applications to a HashiCorp Consul service mesh. And a great way to test whether this approach is actually working is through chaos engineering.
»What is Chaos Engineering?
At a high level, chaos engineering is all about executing an intentional test or series of tests designed to validate and build confidence in your system’s ability to handle a variety of failure scenarios — “chaos” — in real-world production situations. The chaos introduced to intentionally stress your environment to identify potential weaknesses can range from hardware failures to any number of network scenarios that could result in an application failure.
Each set of chaos engineering experiments should be accompanied by a hypothesis you are trying to disprove, for example: “The backend service can handle container failures.” The more challenging it is to prove the hypothesis wrong, the more confident you can be in your application's ability to handle error scenarios of that type. If you can disprove the hypothesis, you now have information on areas that need improvement.
For our example hypothesis, the purpose of the chaos experiments would be to intentionally break the backend service in an attempt to disprove the hypothesis. If the chaos experiments are unable to take down the service, then you can be more confident the application is resilient. However, the backend is just one component of the application. Ideally, you want to test the system as a whole and all of its parts.
»Improve Application Resiliency with Consul
Consul plays a vital role in helping you pass chaos experiments due to its decentralization of networking responsibilities such as routing, retry, failover, and other L7 traffic management. The ability for applications to dynamically change network behavior without requiring human intervention and making application code changes are key benefits of a Consul service mesh. The dynamic network traffic behaviors are what help you improve application resiliency and pass chaos experiments.
Consul decentralizes the networking logic by using proxy sidecars, with Envoy being the preferred proxy sidecar. By abstracting networking logic out of applications and delegating this to Consul and Envoy, application owners can instead focus on developing the application logic.
Assuming you have multiple instances of a service deployed in various locations, Consul and Envoy help ensure automatic failover occurs and that the traffic reaches a healthy service instance. You can see the flow of failover logic with Consul and Envoy in this diagram:
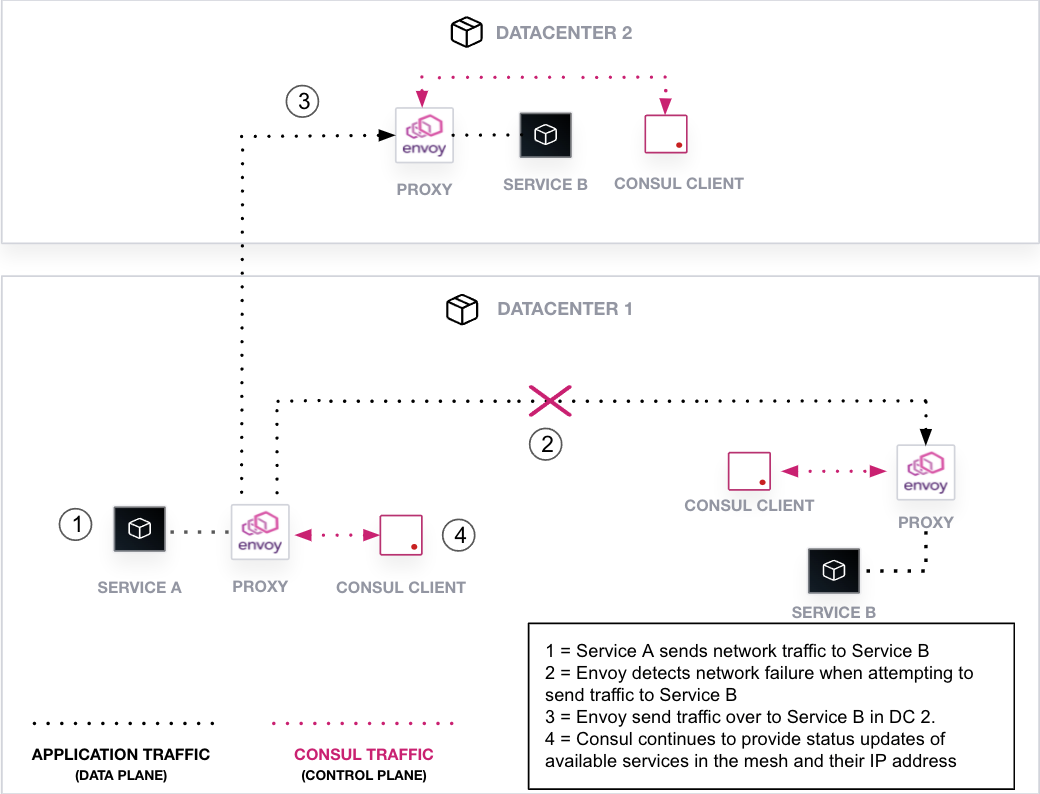
It works something like this:
Service A sends network traffic to service B in datacenter 1.
Envoy detects a network failure when attempting to send traffic to service B.
In response, Envoy reroutes traffic to service B in datacenter 2, ensuring that the application remains available.
Consul continues to provide status updates of available services — and their IP addresses — in the service mesh.
»Learn More About Consul and Chaos Engineering
We have developed a tutorial specifically to help you learn more about chaos engineering and better understand how Consul can improve your application resiliency without changing the application logic. The tutorial includes a free sandbox environment, so there is no need to install anything locally. Go check out the Consul and Chaos Engineering tutorial and start conducting chaos experiments with Consul.

Resources:







