


We often get asked, “How does HashiCorp Consul scale when there is a large number of nodes and services?” The reason this comes up is because when talking about service mesh, we often have this idea of thousands of microservices seamlessly connecting through the mesh, but we don’t always talk about the expected performance of these environments. In an effort to test and document what running a Consul service mesh at enterprise scale would look like, we teamed up with our friends at Datadog and Amazon Web Services to create a benchmark. We wanted to find out what happens when we run a service mesh that consists of 10,000 nodes?
To test the control plane scalability of HashiCorp Consul, we constructed the Consul Global Scale Benchmark.
As a quick refresher, a service mesh consists of a control plane and a data plane. This helps separate the performance-sensitive data path from the rest of the system. The control plane is responsible for providing the management API, maintaining a global state, coordinating traffic, and configuring the data plane, which can be software proxies or hardware appliances. The control plane in a service mesh must be highly available and fault-tolerant.
»Results
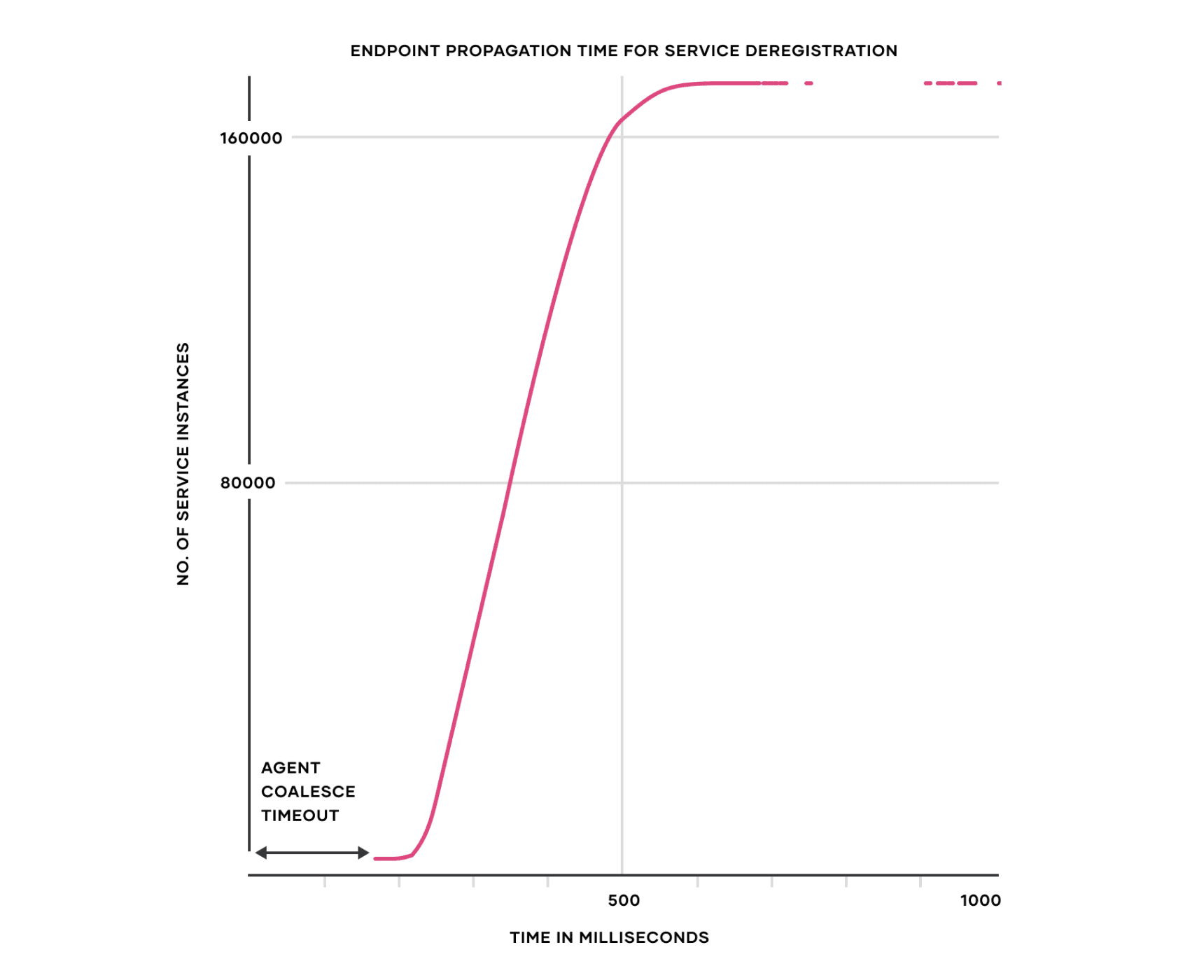
The Consul Global Scale benchmark was designed to test the control plane responsiveness of Consul with thousands of nodes and hundreds and thousands of services in the Consul cluster. We measured how long an upstream service change would take to propagate to services running on a large number of nodes.
The key result shows that 5 Consul servers were able to deliver control plane updates to 172,000 service instances (containers) in under 1 second in a Consul cluster of 10,000 virtual machines. Below is a graph that shows the endpoint propagation time of removal of an upstream service that causes an update in Envoy proxy configuration of approximately 172,000 service instances (~96.6% of the total service instances) in under 1 second. The X-axis is the propagation time in milliseconds and the Y-axis is the number of service instances (Envoy proxies).
We want to thank our friends at AWS and Datadog, who provided us with credits and support to run this benchmark.
To learn more, read the detailed write-up on the Consul Global Scale benchmark page.
»Conclusion
This benchmark may not reflect the scale of most users’ service meshes, but it illustrates an important point: The goal of thousands or tens of thousands of services running across multiple clusters and cloud environments is achievable. Our goal was to show that Consul is capable of handling just about anything that you can throw at it — and we did just that. That’s not to say we didn’t hit some hiccups along the way, but this experiment clearly illustrated the art of the possible.
So what’s next? We encourage you to try running Consul at whatever scale your business or home lab requires. Our users and customers expect our products to be reliable at scale, and we continue to use large-scale benchmarks to explore and push the boundaries of our products.
We greatly appreciate the partnership with our friends at Datadog and AWS, which provided us with credits and support to run this benchmark. For more information about Consul service mesh, please visit our documentation, and for more information about the Consul Global Scale benchmark, please visit the benchmark’s landing page.







