

We are excited to announce that HashiCorp Nomad 1.6 is now generally available. Nomad is a simple and flexible orchestrator used to deploy and manage containers and non-containerized applications. Nomad works across multiple cloud, on-premises, and edge environments.
Here’s what’s new in Nomad and the Nomad ecosystem:
Node pools
Node pool governance (Nomad Enterprise)
Job status page redesign
Jobspec sources in the UI
Nomad Pack 0.1
Production-ready Podman
Job restart command
»Node pools
Node pools are a new way to determine which client nodes are eligible to receive workloads. To use node pools, first add a node_pool value to a Nomad client in its agent configuration file. Clients are added to the node pool called “default” unless otherwise specified in the client config:
client {
node_pool = "gpu-nodes"
…
}
Since this client is part of a non-default node pool, no tasks will be placed onto it unless a job opts into using the node pool. To opt a job into a node pool, simply add the node_pool attribute at the job level:
job "ml-job" {
node_pool = "gpu-nodes"
type = "service"
group "core-work" {
…
}
}
Unlike constraints, node pools allow job writers to avoid sets of nodes without having to know anything about the overall cluster architecture. By default, tasks are opted-out of non-default node pools. This means job authors don’t have to repeatedly add the same constraints to every job just to avoid certain nodes. Node pools can also be used across datacenters, providing an additional layer of hierarchy and control for workload placement.
»Node pool governance (Enterprise)
Nomad Enterprise users can use node pools to control workload placement using namespaces.
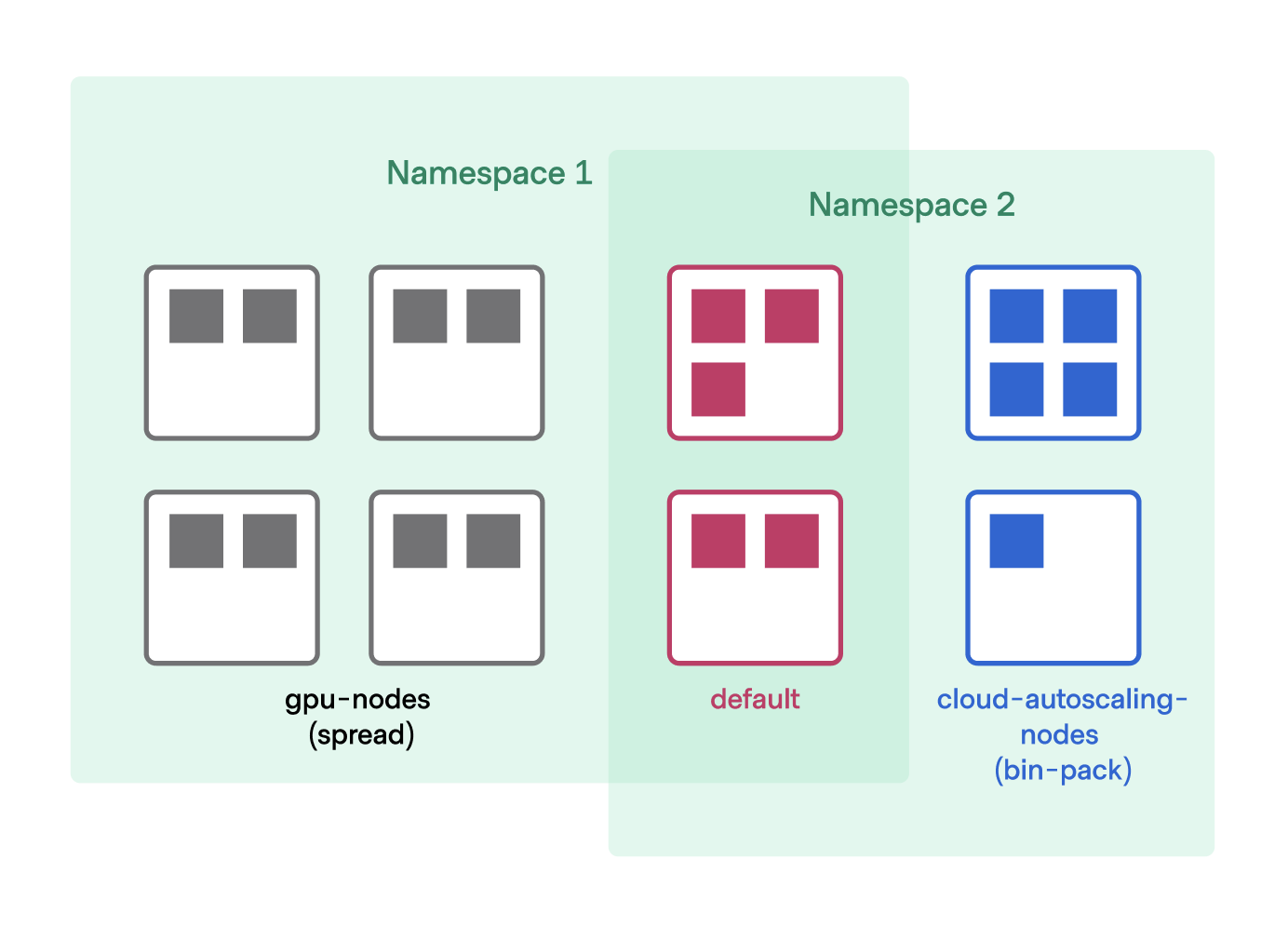
In Nomad open source, all namespaces have access to all node pools and jobs are put on the default node pool unless otherwise specified. In Nomad Enterprise, when creating a namespace, a default node pool value can be specified on the namespace, and other node pools can be allowed or disallowed:
name = "machine-learning-namespace"
node_pool_config {
default = "gpu-nodes"
allowed = ["default", "autoscaling-nodes"]
}
This gives Nomad administrators fine-grained control over which users can put work on which machines. End users of Nomad jobspecs don’t have to know anything about the broader system. Workloads are automatically sent to the correct nodes and separated from each other.
This approach enables multi-tenant Nomad clusters with multiple user groups running on different namespaces whose workloads cannot conflict with one another. Nomad administrators running multiple Nomad clusters to achieve workload isolation can now combine separate clusters into one, reducing administrative and resource overhead.
Additionally, node pools can be configured to use different scheduling algorithms and have different memory-oversubscription values. This can help get the most use out of certain nodes while maximizing stability on others.
For example, a user might have one set of nodes they’ve already paid for in an on-premises pool called gpu-nodes, and another set of nodes they pay for by the hour in a node pool called cloud-autoscaling. Jobs sent to the gpu-nodes pool could use the spread scheduling algorithm and use no memory oversubscription. Jobs sent to the cloud-autoscaling pool could use the bin-pack scheduling algorithm and turn on memory oversubscription:
node_pool_config "gpu-nodes" {
description = "Pool of nodes in our on prem datacenter"
scheduler_config {
scheduler_algorithm = "spread"
memory_oversubscription_enabled = false
}
}
This allows node pool users to customize Nomad’s behavior depending on node type. For many Nomad users, this will enable cost savings and efficiency while keeping their most important workloads stable.
Node pool governance is available on the Nomad Enterprise Governance package.
»Job status and deployments redesign
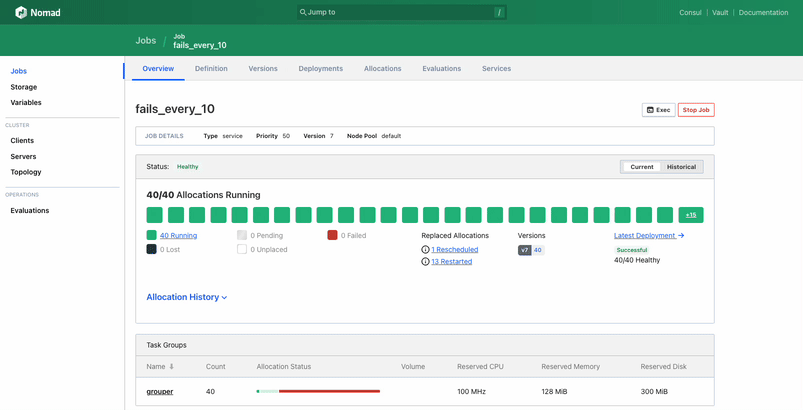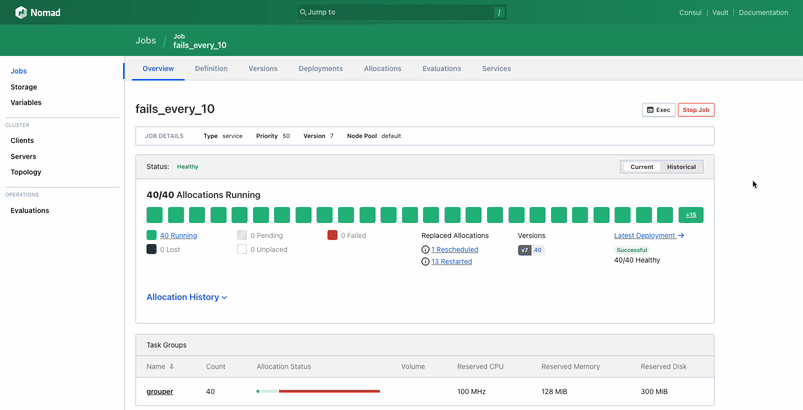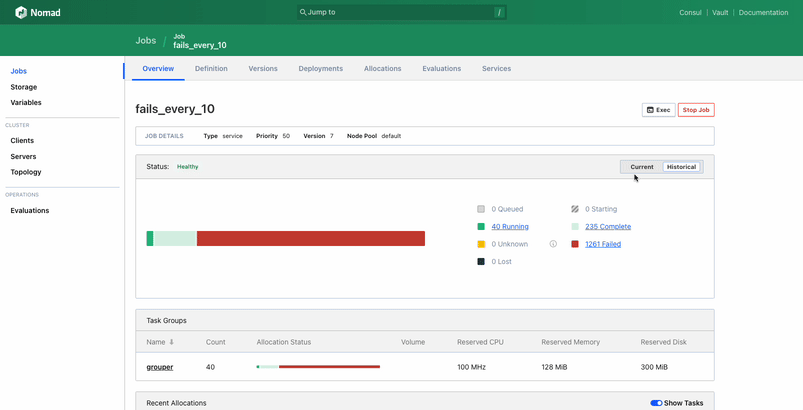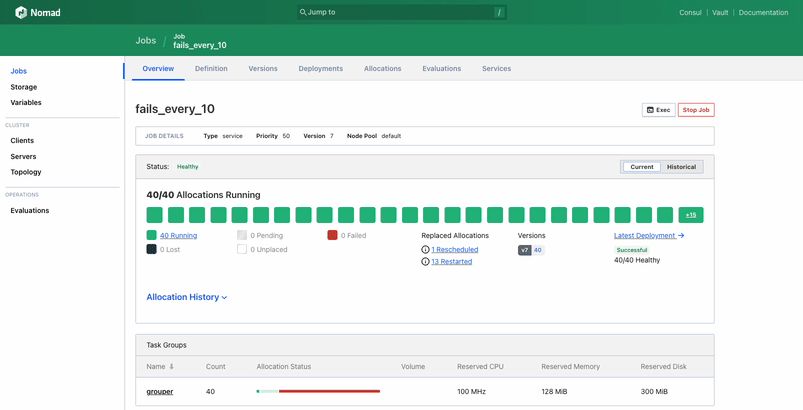
Upon visiting the job page, users can now quickly determine if their job is running and in a healthy state. The new design clarifies how many allocations are meant to be running versus how many actually are running. Additionally, the top-level status of the job reflects if a job is fully healthy, deploying an update, in a degraded state, or recovering from a degraded state.
The update also makes it easier to understand allocation status. The top-level visualization for allocations now shows the status of allocations from the current deployment by default, not the status of all historical allocations. Each allocation block shows its status and its health-check status, and provides a link to the allocation page. This surfaces more important information to the user in an easily understandable format.
Additionally, the deployments interface has been upgraded to make it clearer when a deployment is active, show the status of every allocation associated with a deployment, and outline the rules Nomad is following for each deployment. Plus, a list of events related to the deployment, such as when allocations were placed, when a canary promotion happened, and when allocations failed, is included in the UI. Even users who are unfamiliar with Nomad’s deployment process should be able to follow along without consulting the documentation.
Altogether, these changes add up to the largest improvements to Nomad’s job page in several years.
»Jobspec sources in the UI
Nomad 1.6 makes it easier than ever to understand how a job is supposed to behave, by surfacing jobspec source code directly from the UI.
The job definition tab previously showed only the full jobspec definition in raw JSON, which included the values set by the submitter and all of the default values for the job. This made it difficult to quickly understand and debug jobs from the UI.
Nomad 1.6 includes the full jobspec file that was used to submit the job. This makes it far easier to understand what a job is doing and how it is supposed to behave. Users won’t have to reference their version control system just to read a job file.
Users who wish to make ad-hoc changes to jobs in the UI can do so via HashiCorp configuration language (HCL) as well. While we suggest a git-based flow for regular production use, editing in the UI can be helpful for quickly fixing jobs under time constraints or for trial-and-error while writing a new job.
Submitting and saving large jobspec files in Nomad can increase the storage requirements for high-use clusters. Therefore, for performance-oriented clusters, we’ve included the ability to set a job_max_source_size size limit. Setting this limit to 0 will cause Nomad to disregard any HCL jobspec files. By default, Nomad will not store a jobspec source over 1MB.
See the new submission value in the job API and submissions API endpoints for more information on how to save jobspec files using the API.
»Nomad Pack 0.1
Nomad Pack is a package manager and templating tool built for Nomad. It allows users to easily templatize Nomad jobs, pass in user-provided parameters, and deploy jobs to Nomad. Platform teams setting up Nomad for their developers can use Pack to standardize the way Nomad jobs are run within their organization. New Nomad users can use Pack to deploy common applications to Nomad.
Nomad Pack’s upcoming 0.1 release includes many major improvements to writing and using packs.
First, Nomad Pack 0.1 will include improved support for versioned dependencies. When writing a Pack, to include a dependency, include it in the metadata using a dependency block, then call the new nomad-pack deps vendor command from the Pack’s root directory. This will bundle the dependencies at the specified version within your pack. To update a dependency’s version, just bump the version in the metadata file, and call the command again:
# metadata.hcl
dependency "redis" {
source = "git://github.com/acmecorp/canonical-redis@1.0.2"
}
# cli (from pack directory)
nomad-pack deps vendor
This lets Nomad Pack users share code between packs in a simple way. For instance, you can write a helper pack that contains your organization’s canonical definitions for health checks, stateful services, or common Nomad tasks. These packs can be used by other packs, with dependencies pinned to specific versions and updated safely.
Next, Nomad Pack will allow users to templatize and render files that are not Nomad jobs. For instance, you can render configuration files that need to be submitted to a Nomad job once it is deployed, or Nomad policies that determine your tasks’ access level. Any file ending in .tpl in the templates directory will be rendered when calling the nomad-pack render command.
Additionally, Nomad Pack 0.1 supports optional jobs. Say you have a pack that could use a database running on Nomad itself or in your cloud provider. You may want to conditionalize running a database Nomad job based on a user-supplied variable. Nomad Pack 0.1 will ignore jobs when templates are blank, allowing users to wrap full jobspec templates in conditionals based on user-supplied variables:
# ./my-pack/templates/database.nomad.tpl
# only deploy database if include_db variable is true
[[ if ( var "include_db" . )]]
job "database" {
# rest of pack code
…
}
[[ end ]]
Other improvements to Nomad Pack include:
A new
var-filecommand to auto-generate a variable overrides file for a pack by runningnomad-pack generate var-file <pack-name>.A new
listcommand lists available packs, while theregistry listcommand has been changed to list registries.HCL job files are auto-formatted when rendering a pack.
Users can pass in variables that are unspecified by the pack they are deploying. This allows for more easily shareable variable override files, such as
devorprodvariable files that provide values specific to each environment.A new syntax for passing in variable values for child packs.
Author and URL fields have been removed from pack metadata.
Nomad UI can filter the jobs index to show only packs.
Multiple bug fixes
Lastly, Nomad Packs are now available in the Nomad Integrations Registry. Currently, any packs submitted to the Nomad Pack Community Registry will be auto-imported to the Integrations Registry. In the near future, we will be opening up the integrations registry to other repositories. This self-serve model will allow pack writers to more easily maintain and share packs with other Nomad users. More information will be shared on how to contribute packs in your own GitHub repos once we open the registry to the public.
Nomad Pack 0.1 is expected to be released in the coming weeks.
»Production-ready Podman
One of Nomad’s guiding principles is to let the user run workloads how they like, and for many Nomad users who wanted to run containers, this meant running Podman. The Nomad ecosystem has long had a Podman task driver supported by many members of the community. The Nomad team has lent a hand to our community over the last release cycle and closed gaps between the official Docker driver and Podman on Nomad.
This means improved quality of life and fewer bugs for users in the RHEL ecosystem. Nomad’s Consul Connect integration now also handles Podman without any customized code. With previous releases of Nomad, Podman users had to specify a custom connect.sidecar_task to properly run Envoy as a Podman container. Now, Nomad automatically recognizes if a task is running Podman and launches Envoy using Podman. This allows users to take full advantage of Nomad’s user-friendly integration with HashiCorp Consul.
Additionally, the Podman driver now correctly supports cgroup v2 and bridge networking, and has had several major bugs fixed.
»Job restart command
Nomad 1.6 includes a new 'nomad job restart' command to make it easier to restart or reschedule all the allocations in a job.
nomad job restart app-serverThis will be the equivalent of calling nomad alloc restart on every allocation deployed by the job. If you wish to restart all the tasks associated with an allocation, including prestart and sidecar tasks, include the -all-tasks flag.
Add the –reschedule flag to place allocations on new nodes. This can be helpful in rebalancing allocations in a cluster in response to changes since the last job deployment.
»More Nomad updates
Outside of these core improvements, new additions in Nomad 1.6 and in minor releases since Nomad 1.5 was released include:
JWT authentication method for machine-to-machine authentication and identity token based login. This can enable improved authentication workflows, such as this GitHub Action for authentication using JWTs or UI logins using JWTs.
The
nomad alloc logscommand now streams bothstdoutandstderrby default when following an allocation.A new
drain_on_shutdownblock has been added to Nomad client configuration to allow jobs to more gracefully stop on node shutdown.Log collection can now be disabled for deployments with out-of-band log shipping. This can cut down on memory overhead for edge deployments.
Custom templates or JSON can be produced when calling the
alloc checks,namespace status,quota status,server members, andquota inspectendpoints by using the-tand-jsonflags.Additional keyboard shortcuts added for running, stopping, and purging jobs, running exec, promoting canaries, failing deployments, and switching regions.
Support for Docker’s group_add parameter has been added.
Raft traffic due to client updates has been reduced.
»Community highlights: Wasm and Cilium on Nomad
One of the joys of working on Nomad is watching our community use the product in unexpected ways. The Nomad team wanted to highlight some of the great work done by our community to push Nomad into exciting new territory.
Web Assembly (Wasm) for server-side work is becoming increasingly popular. Rather than running full containers to isolate and encapsulate workloads, some are using WebAssembly modules. Because Nomad can run more than just containers, it is a perfect fit for this sort of workload. Community members have written a wasmtime driver and a Spin driver to run Wasm on Nomad.
Nomad also provides flexibility at the networking level. Users have a high degree of control over how they want their networking stack to work on Nomad. Nomad users at Cosmonic wanted to use Cilium to connect their Wasm workloads. They have open sourced the great Netreap tool in order to do that.
As Nomad embraces flexibility and “workflows not technologies”, we think it is a perfect fit for those experimenting with server-side Wasm. We look forward to continuing to see this space grow over time.
»Community updates
Nomad is committed to being an open source-first project, and we’re always looking for open source contributors. If you’re familiar with Go or interested in learning/honing your Golang skills, we invite you to join the group of Nomad contributors helping to improve the product.
Looking for a place to start? Head to the Nomad contribute page for a curated list of good first issues. If you’re a returning Nomad contributor looking for an interesting problem to tackle, take a glance at issues labeled “help-wanted” or “good first issue”. For help getting started, check out the Nomad contributing documentation or comment directly on the issue with any questions you have. Community members can also contribute integrations to Nomad or to the Nomad Pack Community Registry.
We also encourage users to go to the official Nomad Community Forums or join us for community office hours if they have Nomad questions or feedback. We also would like to recognize some of our community members for creating unofficial spaces for Nomad users to connect. Thank you to the communities on Gitter and the HashiCorp Community Discord.
»Getting started with Nomad 1.6
We encourage you to try out the new features in Nomad 1.6:
Download Nomad 1.6 from the project website.
Learn more about Nomad with tutorials on the HashiCorp Learn site.
Contribute to Nomad by submitting a pull request for a GitHub issue with the “help wanted” or “good first issue” label.
Participate in our community forums, office hours, and other events.
This post was originally published on June 28 for the beta release.







