

Even as service mesh adoption continues to grow, some organizations are still trying to understand the full extent of what a service mesh can and can’t do.
They may not realize that a service mesh is not just another single-purpose tool, but one that addresses a wide variety of networking needs. A service mesh may actually help consolidate multiple existing tools to help reduce management toil and costs.
Just take a look at these two multi-cloud network architectures:
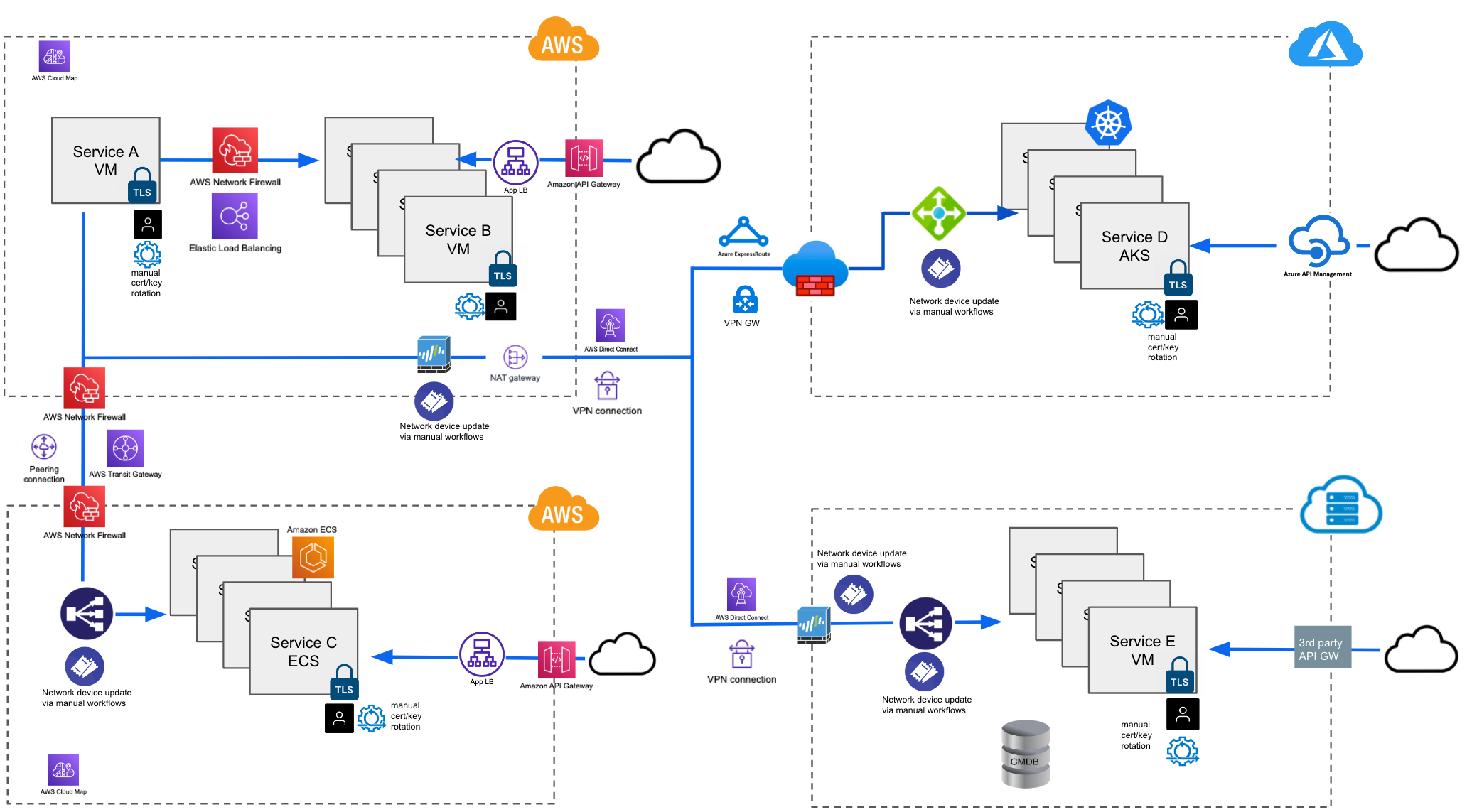
First image: A multi-cloud architecture using cloud-vendor-specific networking solutions.
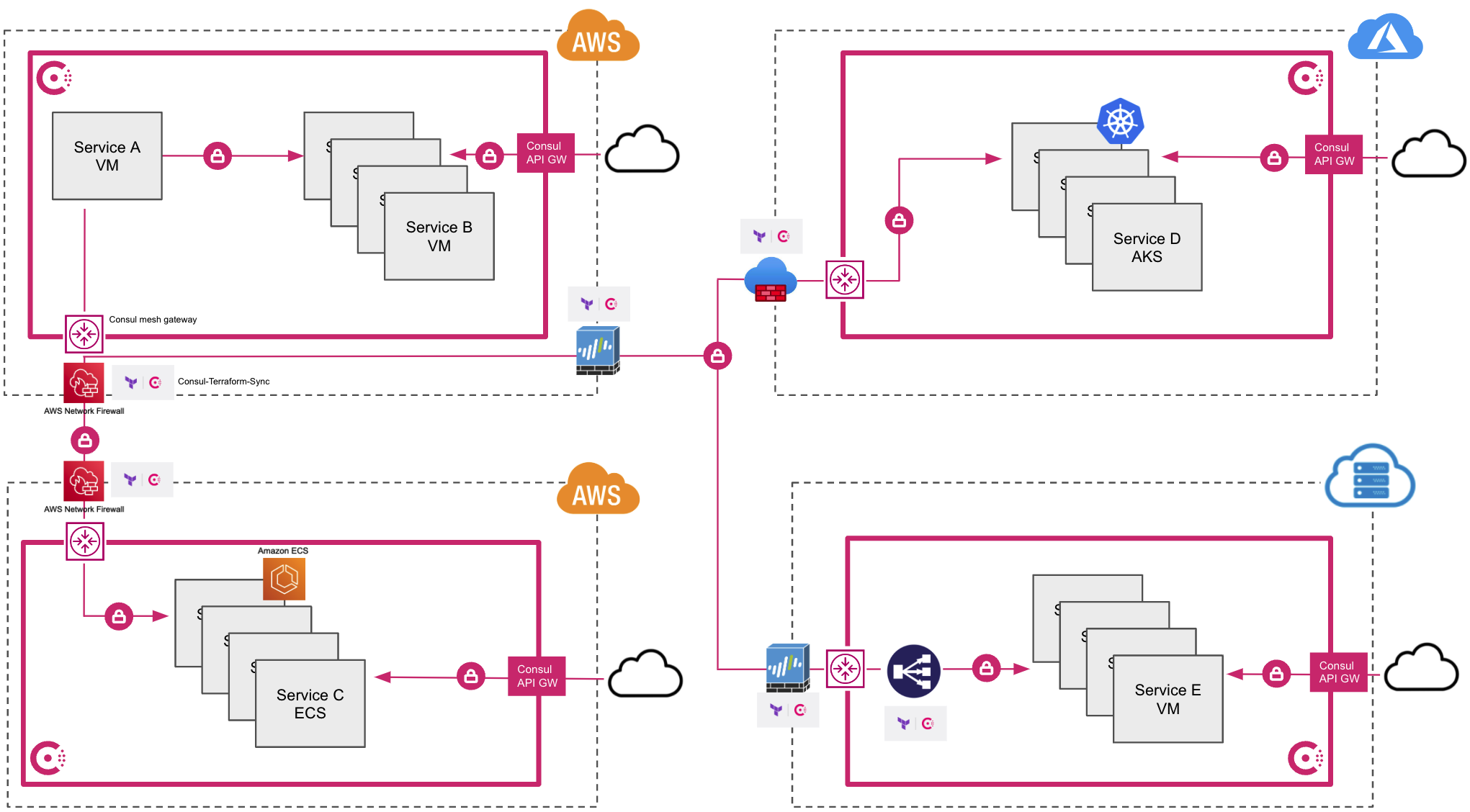
Second image: Using a cloud-agnostic service mesh.
Which looks less complex to you?
If the service mesh you choose is cloud-agnostic, you can greatly simplify a multi-cloud architecture. Not only that, but many service mesh products include service discovery, secure service-to-service communication, load-balancing capabilities, and L7 and L4 network management capabilities that include progressive delivery patterns.
Some other service mesh products extend even further to provide multi-cloud/multi-runtime connectivity, network infrastructure automation, and north-south traffic control. Let’s take a look at the capabilities of a cloud-agnostic service mesh and its potential for consolidating existing tools across environments to help toil and expenses.
»Service Discovery
Service discovery allows developers to catalog and track the network location and health of all registered services on their networks. It is an important capability in a dynamic environment where services are constantly scaling up and down. It’s often the first step on the journey to service mesh adoption.
There are many ways to get service discovery capabilities. But commonly used capabilities built into Kubernetes, Amazon EKS, Azure AKS, Google GKE, or service-discovery tools like AWS Cloud Map and Configuration Management Databases (CMDB) are typically specific to the platform or cloud they are running on. The scope of services that they can discover is limited to the boundaries of their particular platform or cloud. Today, though, most organizations run applications across multiple platforms or cloud environments, which means they need to learn, install, and manage multiple service-discovery solutions.
A better approach is a cloud-agnostic service mesh that can span multiple runtimes. For example, HashiCorp Consul is an agnostic service mesh that includes support for Kubernetes, virtual machines, Amazon ECS, and HashiCorp Nomad, allowing organizations to centralize global service discovery across multiple heterogeneous environments.
By consolidating service discovery onto a service mesh, platform teams can offer service discovery as a global shared service, which reduces cost, improves compliance, and eases management compared to relying on individual teams to run and manage their own service-discovery tools without any oversight.
»Zero Trust Networking
Rather than solely relying on traditional methods of protecting network perimeters, organizations are increasingly looking to zero trust networking to protect their networks and infrastructure.
Instead of traditional castle-and-moat security approaches that rely on defending a perimeter that may not exist in modern cloud-based environments, zero trust security holds that no service — whether inside or outside of the perimeter — should be granted access until it is authorized and authenticated and all communications are encrypted.
Applying the zero trust networking principles of authentication, authorization, and encryption is a primary service mesh capability. Service meshes automatically redirect ingress and egress traffic between services through a proxy, typically Envoy. This allows authorization, authentication, and encryption responsibilities to be offloaded onto the proxy.
Service meshes use service identities instead of IP addresses as the unit to which authorization is allowed or denied, dramatically simplifying management of service-to-service communication.
Administrators can configure a single deny-all policy that will be enforced by the proxy to prevent all services-to-service communication. Developers can add more granular policies to authorize specific services to communicate on an as-needed basis.
The service mesh proxy will also ensure all service-to-service communication is automatically authenticated and encrypted. Prior to any service communication, proxies ensure that TLS certificates are exchanged and all traffic over the network is encrypted. This results in a more secure network, preventing lateral movement between services even after a network breach has taken place.
Lastly, service meshes inherently help organizations shift left by providing administrators and developers with the ability to authorize, authenticate, and encrypt their network services earlier in the development cycle. By shifting left, organizations reduce the risk of last-minute delays due to unforeseen security gaps right before going into production. Furthermore, shifting left with a service mesh frees network administrators to focus on protecting network perimeters instead of managing individual IP addresses.
A service mesh is a force multiplier for network administrators and an abstraction layer that allows developers to focus on their applications instead of security logic and avoid the toil of managing and rotating certificates and keys.
»Load Balancing
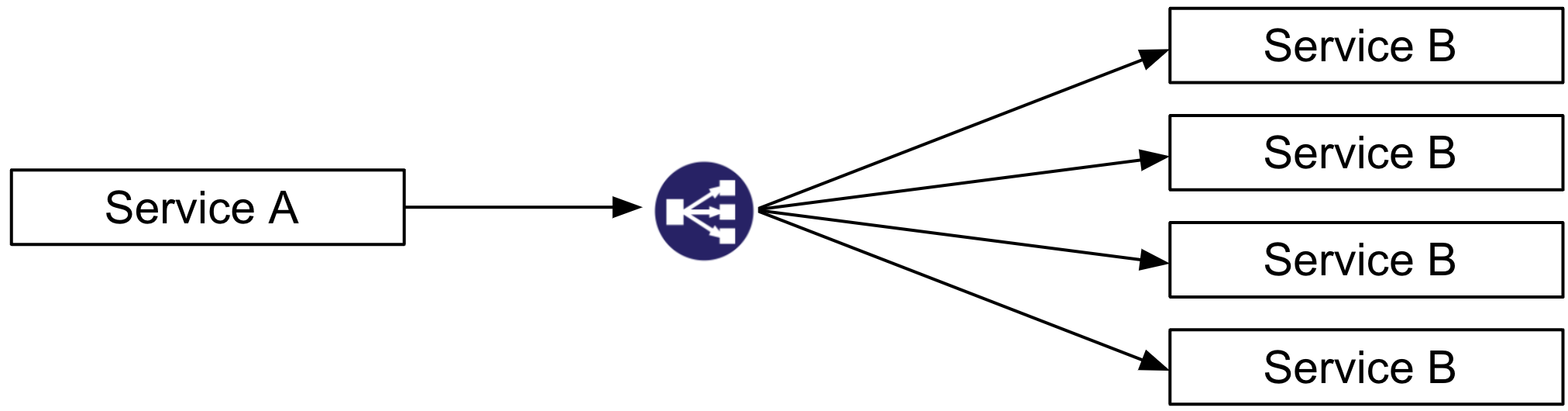
Since data traffic on a service mesh flows through the proxy, a service mesh can also control capabilities like traffic shaping. A simple example is load balancing among multiple instances of a service. Service meshes allow custom traffic patterns to be distributed directly between instances rather than taking additional network hops through separate load balancing devices. Even as instances scale up or down, service meshes can dynamically adjust traffic distribution. Using a service mesh can greatly reduce the cost and complexity of managing multiple different load balancing devices across multiple different environments and clouds.
Here is a traditional load balancing topology with an extra network hop to the load balancer before service A talks to service B:
In a service mesh like Consul, there's no extra hop since the sidecar proxies communicate directly and Consul centrally manages traffic balancing between each proxy:
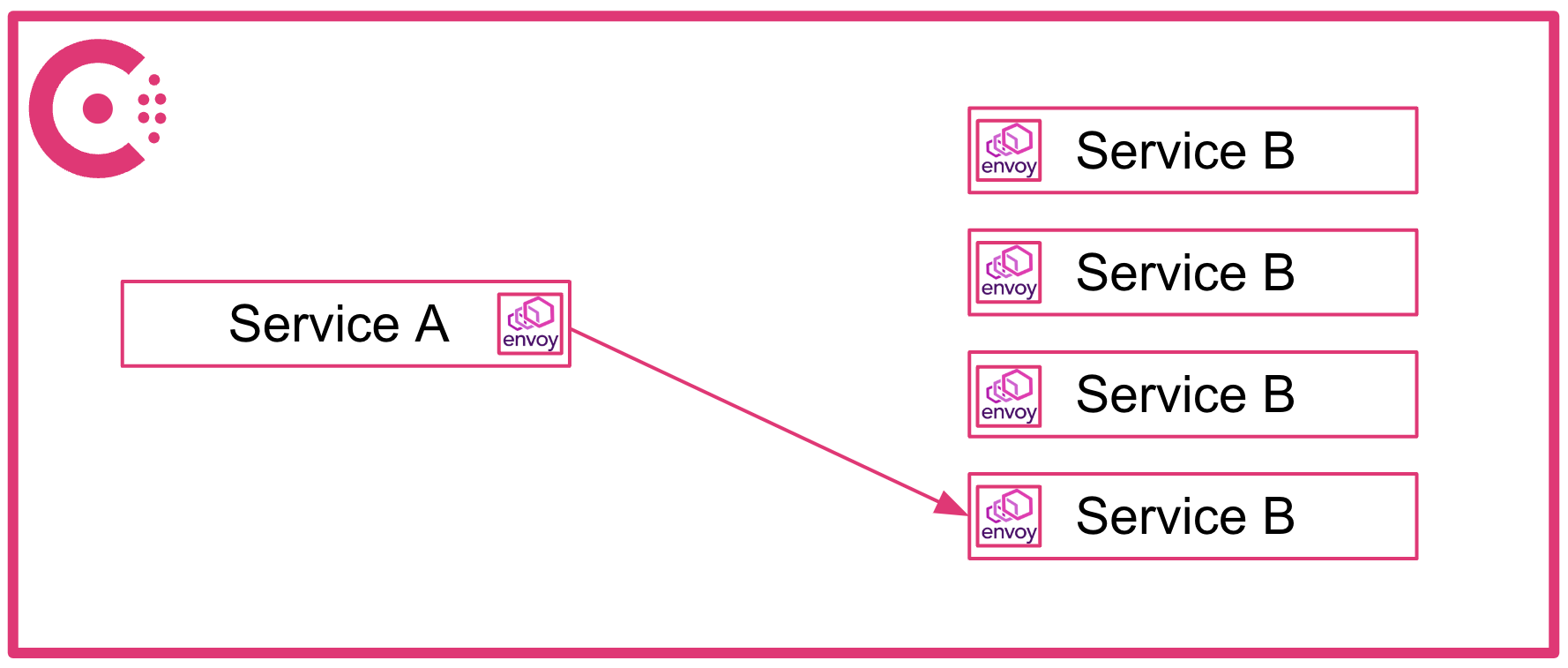
»Multi-Cloud Connectivity
Many organizations have different teams and services dispersed across different networks and regions of a given cloud. Many also have services deployed across multiple cloud environments. Securely connecting these services across different cloud networks is a highly desirable function that typically requires significant effort by network teams. In addition, limitations that require non-overlapping Classless Inter-Domain Routing (CIDR) ranges between subnets can prevent network connectivity between virtual private clouds (VPCs) and virtual networks (VNETs). Service mesh products can securely connect services running on different cloud networks without requiring the same level of effort.
HashiCorp Consul, for example, supports a multi-datacenter topology that uses mesh gateways to establish secure connections between multiple Consul deployments running in different networks across clouds. Team A can deploy a Consul cluster on EKS. Team B can deploy a separate Consul cluster on AKS. Team C can deploy a Consul cluster on virtual machines in a private on-premises datacenter. A multi-datacenter configuration can be established between the three Consul clusters, allowing secure connectivity for services running between EKS, AKS, and virtual machines without additional network configurations like VPNs, Direct Connects, or ExpressRoutes. Consul mesh gateways allow the clustering of multiple Consul deployments even when IP ranges overlap across networks.
»Automation
Automation is especially advantageous in dynamic environments. Fluctuating demand requires operators to scale the number of instances of a service, a fairly trivial task. However, network firewalls, load balancers, or other network infrastructure may need to be updated for new instances to be reachable. Similarly, new application services may require updates to network devices before clients can reach them.
Since most organizations have separate networking and security teams, these workflows often involve a manual ticket request for network device updates that may take hours or even days to complete. Scaling down or retiring services can lead to additional concerns. This is because requests for network teams to remove IP addresses from network devices can easily be overlooked, resulting in potential security gaps.
To address these challenges, some service meshes have built unique integrations with infrastructure provisioning tools such as HashiCorp Terraform. Consul has a unique integration with Terraform that enables automatically triggered network device updates and reprovisioning. Operators can configure Consul-Terraform-Sync (CTS) to automatically update devices like firewalls and load balancers based on changes to services within Consul’s catalog. Automating these tasks reduces dependence on manual ticketing systems, improves workflow efficiency, and strengthens the organization’s security posture.
»North-South Traffic Control
In addition to shaping and routing traffic between services within an organization's network, there is also a need to provide access to these services from external clients. Cloud native options such as the AWS API Gateway, Azure API Management, and Google Cloud API Gateway can be good choices for organizations that do not plan to scale beyond a single cloud. For organizations that run on multiple clouds, however, there is value in standardizing on a single common platform.
Some agnostic service meshes, including Consul, have a built-in API gateway that can provide similar functionality to the cloud native options. This lets organizations manage traffic within the service mesh traffic (east-west) as well as from external clients (north-south) using one consistent management plane, removing the need to deploy multiple different API gateways across different environments.
»Who Benefits from a Service Mesh’s Tool Consolidation?
If a service mesh can help consolidate the many disparate tools between different runtimes, should every organization incorporate service meshes into their infrastructure? Well, that depends.
For the 81% of organizations that are already using multiple clouds, or plan to do so, service meshes can definitely help contain the sprawl of tools.
Even organizations dedicated to a single cloud provider may be dealing with diverse runtimes chosen by different development teams. Standardizing on a service mesh to provide global service discovery, zero trust networking, and load balancing can help these organizations reduce tool sprawl as well. Agnostic service meshes like Consul can provide further tool consolidation with built-in features to connect services between clouds, automate network device updates, and control access to services from external clients.
While some smaller organizations may not see significant consolidation of tools, at a minimum they can still benefit by adopting a service mesh as a force multiplier to improve their overall security posture without imposing additional effort on developers, platform engineers, or networking engineers.
A version of this blog post was originally published on The New Stack.







