

In this post, I will explore three different methods for integrating HashiCorp Vault with Kubernetes:
The Vault Sidecar Agent Injector
The Vault Container Storage Interface (CSI) provider
The Vault Secrets Operator
I’ll provide practical guidance for each method to help you understand and choose the best method for your use case.
This post is not intended to be a product documentation or step-by-step implementation guide. It is for DevOps practitioners familiar with HashiCorp Vault and Kubernetes who also have a basic understanding of secrets-management concepts.
»Vault Sidecar Agent Injector
The Vault Sidecar Agent Injector leverages the sidecar pattern to alter pod specifications to include a Vault Agent container that renders Vault secrets to a shared memory volume. By rendering secrets to a shared volume, containers within the pod can consume Vault secrets without being Vault-aware. The injector is a Kubernetes mutating webhook controller. The controller intercepts pod events and applies mutations to the pod if annotations exist within the request. This functionality is provided by the vault-k8s project and can be automatically installed and configured using the Vault Helm chart.
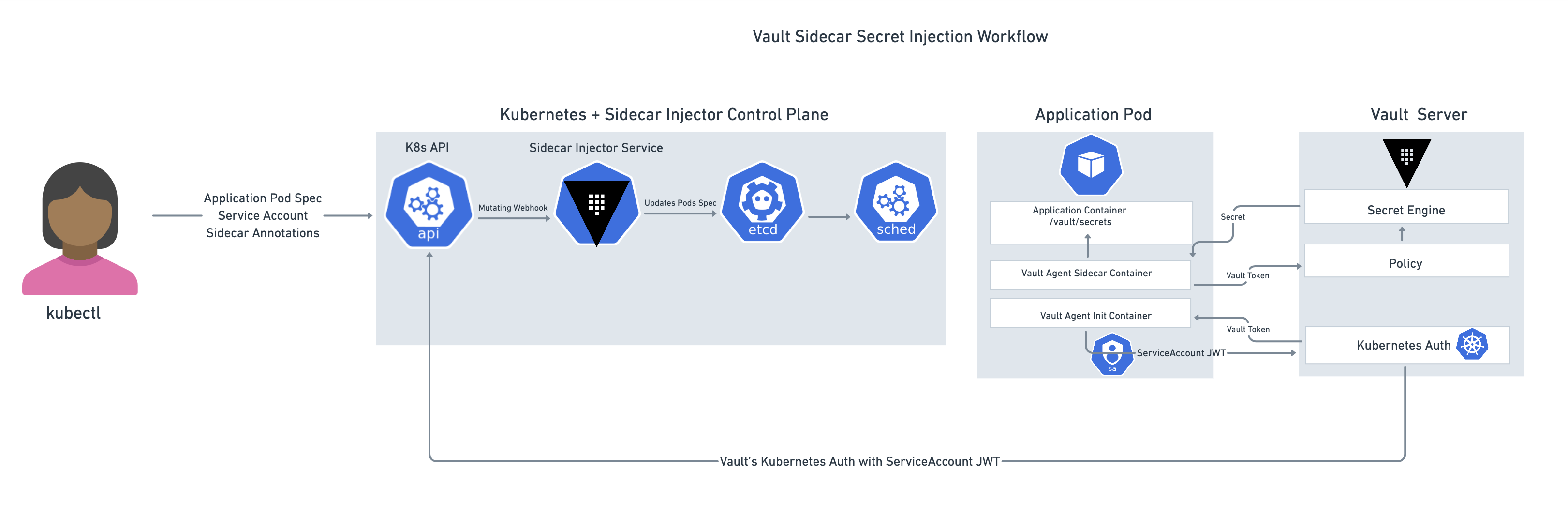
»Vault CSI provider
The Vault CSI provider allows pods to consume Vault secrets by using ephemeral CSI Secrets Store volumes. At a high level, the CSI Secrets Store driver allows users to create SecretProviderClass objects. These objects define which secret provider to use and what secrets to retrieve. When pods requesting CSI volumes are created, the CSI Secrets Store driver sends the request to the Vault CSI provider if the provider is vault. The Vault CSI provider then uses the specified SecretProviderClass and the pod’s service account to retrieve the secrets from Vault and mount them into the pod’s CSI volume. Note that the secret is retrieved from Vault and populated to the CSI secrets store volume during the ContainerCreation phase. This means that pods will be blocked from starting until the secrets have been read from Vault and written to the volume.
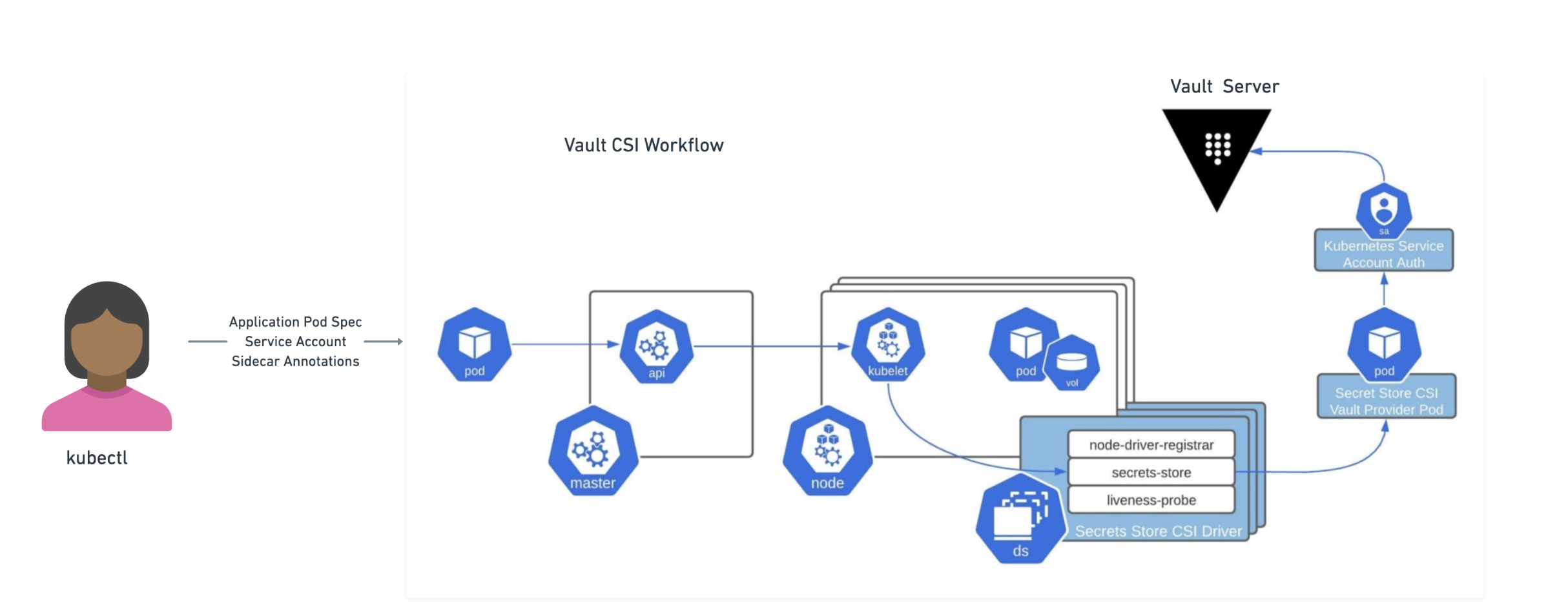
»Vault Secrets Operator
The Vault Secrets Operator is a new integration method that implements a Kubernetes Secrets Operator with a set of CRDs responsible for synchronizing Vault secrets to Kubernetes Secrets natively. The Operator supports synchronizing the full lifecycle of secrets management including static, dynamic, and PKI-based secrets from one or more Vault server instances. The Operator is also capable of managing secret rotation and performing post rotation actions including notifying an application directly via a rolling update of a Deployment or by triggering a rolling update.
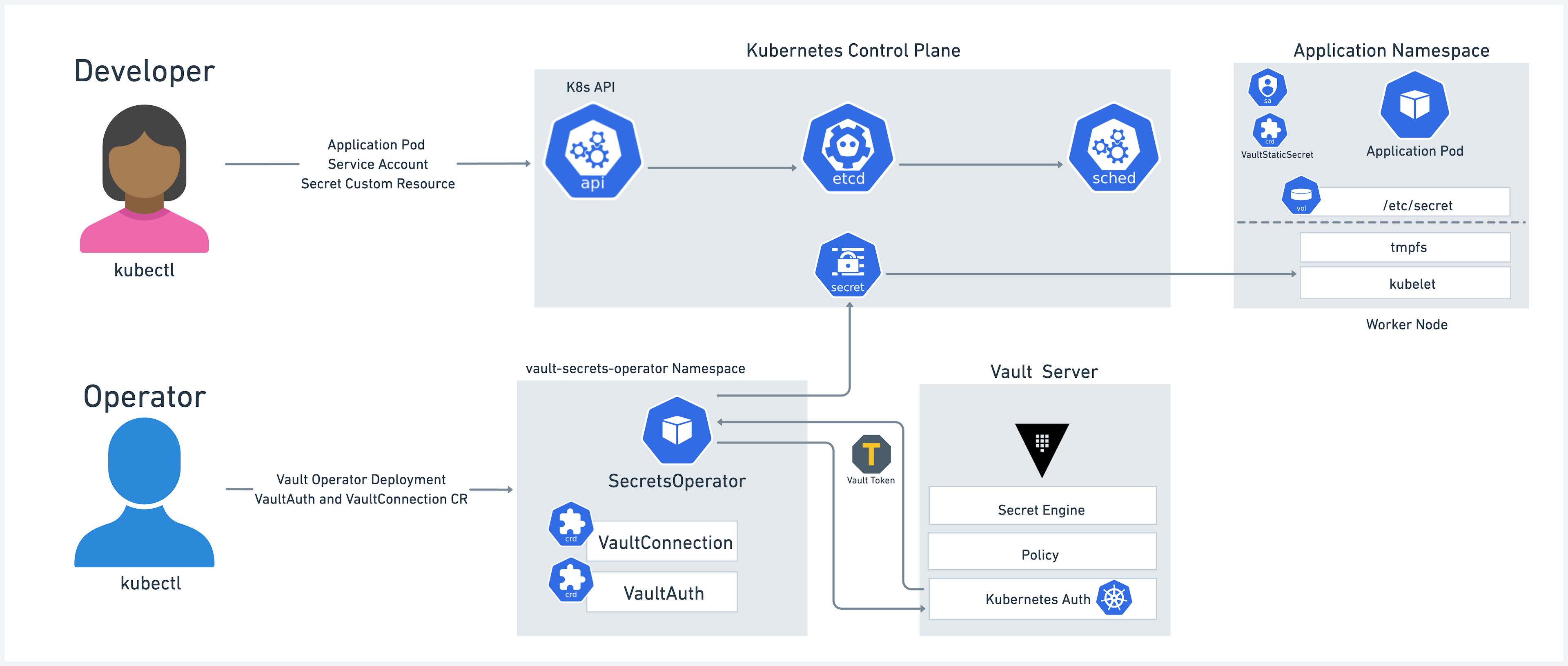
»Common design considerations
There are some similarities and differences between the three solutions that you should consider when designing and implementing your secrets management strategy in Kubernetes environments.
Secret projections: Every application requires secrets to be presented to it in a specific way. Typically, applications expect secrets to be either exported as environment variables or written to a file that the application can read on startup. Keep that in mind as you’re deciding on the right method to use.
Secret scope: Some applications are deployed across multiple Kubernetes environments (e.g. dev, qa, prod) across your datacenters, the edge, or public clouds. Some services run outside of Kubernetes on VMs, serverless, or other cloud-managed services. You may face scenarios where these applications need to share sets of secrets across these heterogeneous environments. Scoping the secrets correctly to be either local to the Kubernetes environment or global across different environments helps ensure that each application can easily and securely access its own set of secrets within the environment it is deployed in.
Secret types: Secrets can be text files, binary files, tokens, or certs. They can be statically or dynamically generated. They can be valid permanently or time-scoped. They also vary in size. You need to consider the secret types your application requires and how they’re projected into the application.
Secret definition: You also need to consider how each secret is defined, created, updated, and removed, as well as the tooling associated with that process.
Encryption: Encrypting secrets both at rest and in transit is a critical requirement for many enterprise organizations.
Governance: Applications and secrets can have a many-to-many relationship that requires careful considerations when it comes to granting access for applications to retrieve their respective secrets. As the number of applications and secrets scale, so does the challenge of managing their access policies.
Secrets updates and rotation: Secrets can be leased, time-scoped, or automatically rotated, and each scenario needs be a programmatic process to ensure the new secret is properly propagated to the application pods.
Secret caching: In certain Kubernetes environments (e.g. edge or retail) there is a potential need for secret caching in the case of communication or network failures between the environment and the secret storage.
Auditability: Keeping a secret access audit log detailing all secret access information is critical to ensure traceability of secret-access events.
Keeping these design considerations in mind, let’s go over some of the similarities and differences between the three integration solutions.
»Similarities
Vault Operator, CSI, and sidecar solutions:
Simplify retrieving different types of secrets stored in Vault and expose them to the target pod running on Kubernetes without it being aware of the not-so-trivial Vault processes. It’s important to note that there is no need to make any changes in the application logic or code in order for it to use these solutions, making it easier to migrate brownfield applications into Kubernetes. Developers working on greenfield applications can leverage the Vault SDKs to directly integrate with Vault.
Support all types of Vault secrets engines. This means that you can leverage an extensive set of secret types, ranging from static key-value secrets to dynamically generated database credentials and TLS certs with customized TTL.
Leverage the application’s Kubernetes pod service account token as “Secret Zero” to authenticate with Vault via the Kubernetes auth method. This means that there is no need to manage yet another separate identity to identify the application pods when authenticating to Vault.
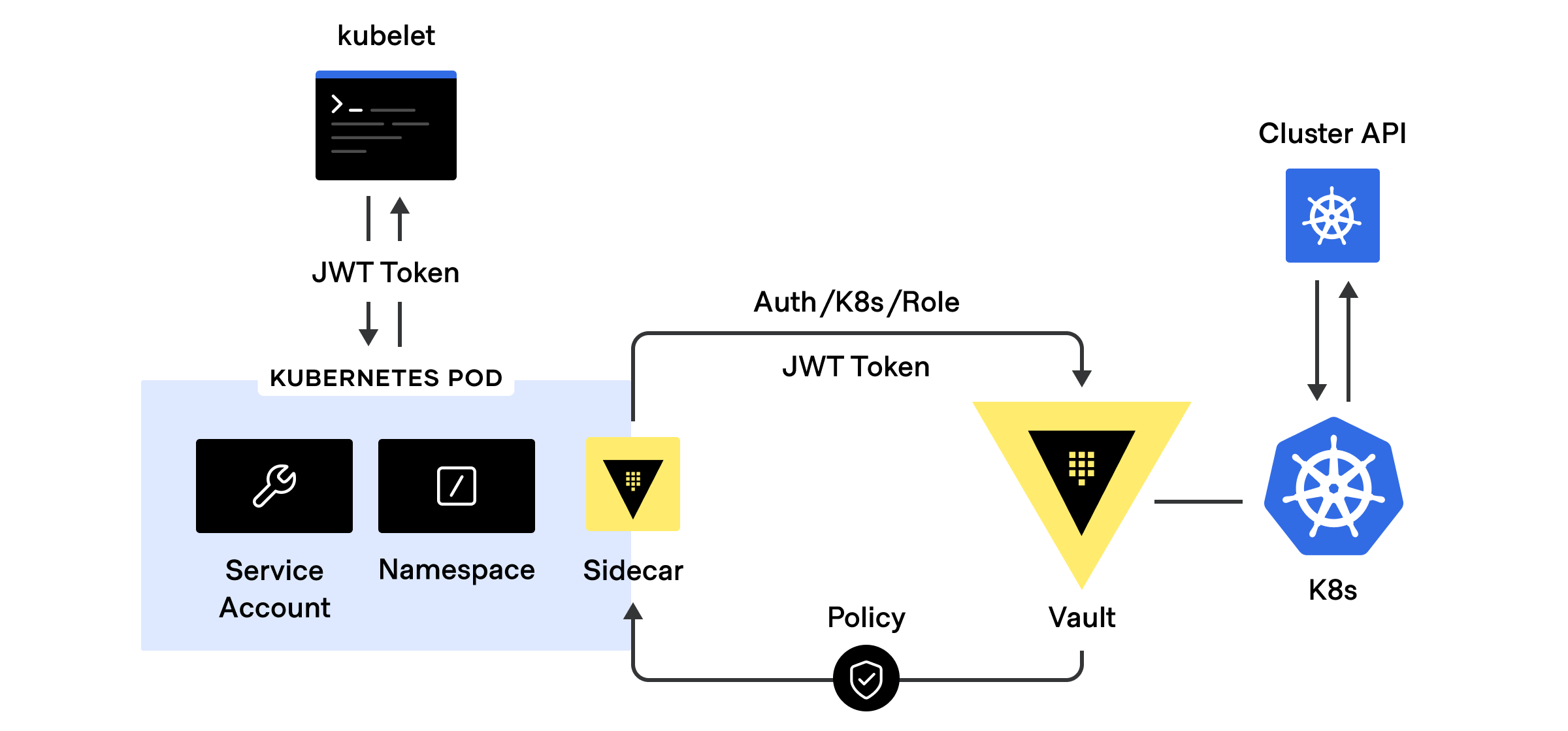
Vault’s Kubernetes auth workflow
Require the desired secrets to exist within Vault before deploying the application
Require the pod’s service account to be bound to a Vault role with a policy enabling access to desired secrets (that is, Kubernetes RBAC isn’t used to authorize access to secrets)
Deployable via Helm
Require successfully retrieving secrets from Vault before the pods are started
Rely on user-defined pod annotations to retrieve the required secrets from Vault
Both the Sidecar Injector Service and CSI Driver can automatically renew, rotate, and fetch secrets/tokens.
»Differences
Here’s how the three solutions are different:
The Sidecar Agent Injector solution is composed of two elements:
The Sidecar Service Injector, which is deployed as a cluster service and is responsible for intercepting Kubernetes apiserver pod events and mutating pod specs to add required sidecar containers
The Vault Sidecar Container, which is deployed alongside each application pod and is responsible for authenticating into Vault, retrieving secrets from Vault, and rendering secrets for the application to consume
In contrast, the Vault CSI Driver is deployed as a daemonset on every node in the Kubernetes cluster and uses the Secret Provider Class specified and the pod’s service account to retrieve the secrets from Vault, and mount them into the pod’s CSI volume.
The Vault Operator is also capable of managing secret rotation and performing post rotation actions including notifying an application directly via (or by triggering) a rolling update of a Deployment.
The Sidecar Agent Injector supports all Vault auto-auth methods. The Sidecar CSI driver supports only Vault’s Kubernetes auth method and Vault Operator only supports the Kubernetes auth method at this time.
The sidecar container that is launched with every application pod uses Vault Agent, which provides a powerful set of capabilities such as auto-auth, templating, and caching. The CSI driver does not use the Vault Agent and therefore lacks these functionalities.
The Vault Operator includes support for the Promethus Operator for governance reporting.
The Vault CSI driver supports rendering Vault secrets into both Kubernetes secrets and environment variables. Sidecar Injector Service does not support rendering secrets into Kubernetes secrets — however there are ways to use agent templating to render secrets into environment variables.
The CSI driver uses
hostPathto mount ephemeral volumes into the pods, which some container platforms (e.g. OpenShift) disable by default. On the other hand, Sidecar Agent Service uses in-memory tmpfs volumes.Sidecar Injector Service automatically renews, rotates, and fetches secrets/tokens. The CSI Driver does not support that.
»Comparison Chart
The table below provides a high-level comparison of the three solutions:
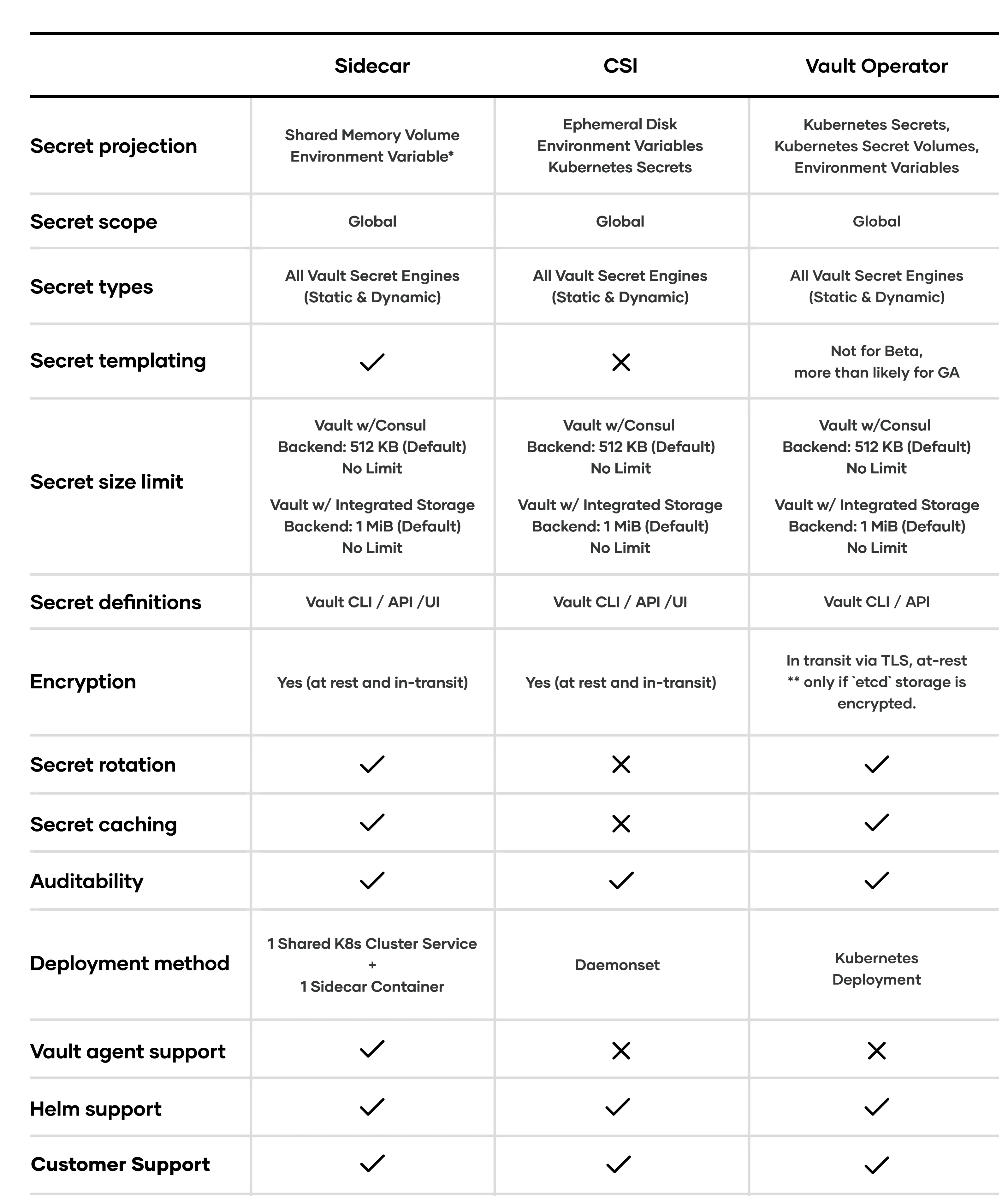
*achieved through Agent templating
»Going Beyond the Native Kubernetes Secrets
On the surface, Kubernetes native secrets might seem similar to the three approaches presented above, but there are major differences between them:
Kubernetes is not a secrets management solution. It does have native support for secrets, but that is quite different from an enterprise secrets management solution. Kubernetes secrets are scoped to the cluster only and many applications will have some services running outside Kubernetes or in different Kubernetes clusters. Therefore, considering the secret scope as part of the design process is critical. Having these applications use Kubernetes secrets from outside a Kubernetes environment will be cumbersome and introduce authentication and authorization challenges.
Kubernetes secrets are static in nature. You can define secrets by using kubectl or the Kubernetes API but once they are defined they are stored in etcd and presented to pods only during pod creation. This can create scenarios where secrets get stale, outdated, or expired, requiring additional workflows to update and rotate the secrets and then re-deploying the application to use the new version of the secrets. This can add complexity and waste time. So make sure you consider any requirement for secret freshness, updates, and rotation as part of your design process.
The security model of secret access management is tied to the Kubernetes RBAC model. This can be challenging to adopt for users who are not familiar with Kubernetes. Adopting a platform-agnostic security governance model can enable you to adopt workflows for applications regardless of how and where they are running.
»Summary
Designing for secrets management in Kubernetes is no easy task. There are multiple approaches each with its own set of pros and cons. I highly recommend exploring the options presented in this blog post to understand their internals and decide on the best option for your use case.






