

Over the past few years, edge computing has shifted from a marketing buzzword to an increasingly adopted topology and location-sensitive form of distributed computing. There isn’t just one architecture pattern or method for deployment, but the general idea of edge computing is to distribute compute (plus networking and storage) closer to the source of data generation or end users. While the list of use cases and industries continues to grow, there are common expected outcomes such as reduced latency, improved end-user experience, and cost savings.
»Orchestrating Applications at the Edge
Once applications and services are running at the edge, however, many are left struggling to maintain and operate the volume of endpoints. Edge environments often involve resource-constrained devices, intermittent connectivity, and a diverse pool of infrastructure and applications that need to be managed remotely. Whether they are running on bare metal, VMs, containers, or even Raspberry Pis, applications at the edge rely on comprehensive lifecycle management with robust security practices, high fault tolerance, and the ability to scale according to workload.
In the past two years, we have seen a rise in the number of customers deploying HashiCorp Nomad at the edge across gaming, biotech, farming technologies, and many more industries. Yet no matter the industry and deployment scale, organizations deployed Nomad to solve three top edge challenges:
Simplifying distributed deployments
Operational efficiency at the edge
Managing heterogeneous environments
This post will share common deployment patterns and use cases for how Nomad can be used to manage edge workloads.
»Simplifying Distributed Deployments
There are different edge deployment strategies to evaluate depending on the use case, application, and infrastructure requirements. If organizations are already using a scheduler or orchestration tool for centralized deployments in production, it isn’t uncommon for them to mirror this at the edge, forming distributed multi-cluster deployments. There are definitely benefits to this strategy, such as stronger workload isolation and fault tolerance, but it is equally important to consider the drawbacks as well, including a significant increase in management complexity and operational overhead.
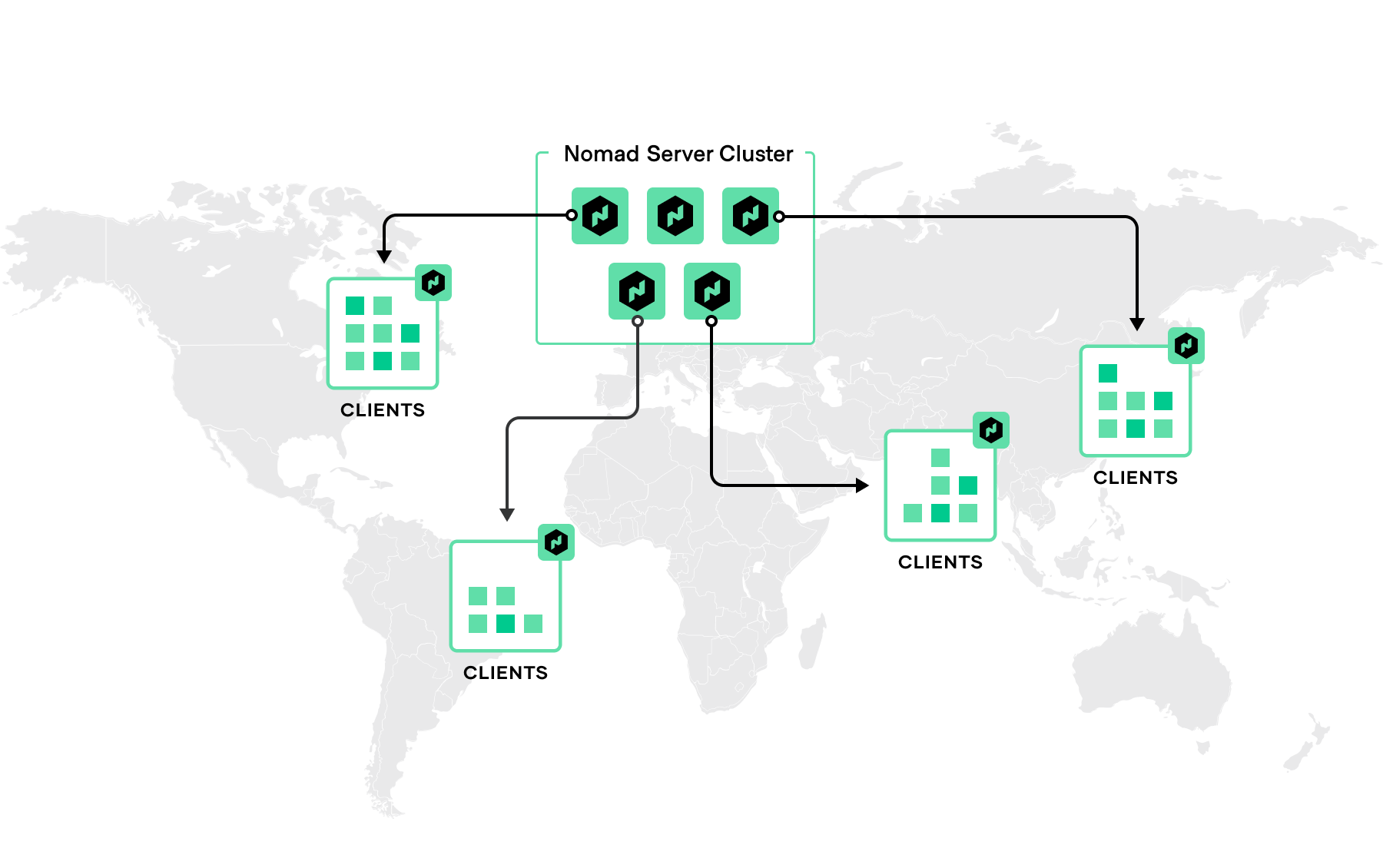
While Nomad can run in distributed multi-cluster deployments, it is flexible in that it also supports an alternative architecture — a distributed single cluster topology that lets you centralize your Nomad servers in one region, geographically distribute clients, and scale them as needed. Each region is expected to have either three or five servers that can span multiple availability zones to strike a balance between availability in the case of failure and performance. However, there is no limit to the number of clients per region. This simplifies operations and offers a unified control plane for all workloads.
There is a trade-off with managing an edge deployment from a central region of servers. There is less isolation between applications, and clients can be more susceptible to failing their heartbeat check due to latency or loss of network connectivity. Nomad recently introduced the max_client_disconnect configuration attribute that allows operators to reconnect allocations on nodes that have experienced network latency issues or temporary connectivity loss.
A variation of that strategy is to take advantage of Nomad Enterprise's read scalability feature and distribute non-voting servers that can act as a local proxy to clients in the network. Clients register with the non-voting server locally, and then those servers will forward their RPCs to the centralized leader.
»Case Study: Bowery Farming
Bowery Farming is an example of a customer that has implemented Nomad’s distributed single cluster topology in production. It is an indoor vertical farming company that grows produce in highly automated farms that run using proprietary hardware and software systems, called Bowery OS, or Bowery Operating System. The company can control temperature, lighting, airflow, irrigation, nutrient mix, humidity, CO2, photoperiod, and more with these automated systems. Bowery has services and infrastructure running both in the public cloud (AWS) and on-premises in its farms.
John Spencer, Senior Site Reliability Engineer at Bowery Farming, took on the challenge of developing a more canonical way for Bowery to deploy and run services across both its cloud and on-premises environments. IT runs its production Nomad servers in a single region in AWS. That server group manages all of the farms, which are individually and remotely operated. The team did that by deploying Nomad clients into each farm, which are operated as separate datacenters (bf-0, bf-1, bf-2 etc). Bowery started with just one Nomad client at each farm back when it was resource constrained and running on bare metal.
When it came time for Bowery to connect services, the team started to migrate to VMs so they could run a HashiCorp Consul server node together with three Nomad clients at each farm. They host their staging and sandbox environments in similar and separate clusters. “I was the only SRE when we started this project, so it was important that whatever we built was easy to operate and simple,” said Spencer. “Within a month and a half of being at Bowery I had production workloads running in AWS with Nomad, and then as time went on we started to roll them out to our farms as well.”
Watch this talk about Bowery’s use cases with Nomad.
»Operational Efficiency at the Edge
Complexity consistently ranks as one of the top challenges of container management. For Kubernetes users, moving to the edge often increases operational overhead because most edge use cases will require a multi-cluster architecture. You need to establish a secure connection to each cluster, implement separate access control policies, and configure a number of other cluster-specific resources. If applications need to communicate with each other, then connectivity has to be established between clusters by setting up a service mesh. Managing clusters individually is difficult to maintain as your environments scale, so many have users adopted community projects like Kubefed or created their own abstraction layer to centrally manage them. Both options require a significant investment of time and resources to implement.
If you decide that a multi-cluster deployment makes the most sense for your use case, you can reduce some of the operational overhead with Nomad by connecting multiple clusters via multi-region federation. This allows you to connect to one region (with Nomad, a region is the equivalent of a Kubernetes cluster), forward commands, and share ACLs with other regions. Federating with Nomad is simple — run the nomad server join command from a server in one cluster and supply it the IP address of the server in your other cluster. The Nomad UI is built into the Nomad binary to give users a web-based interface to inspect the cluster state and submit and manage jobs.
»Case Study: AccelByte
AccelByte is a backend tools platform for multiplayer online video games. Its platform gives developers a ready-made set of tools to manage the behind-the-scenes requirements of multiplayer online games. The services it provides include IAM, matchmaking, monetization, analytics, and storage. “Our end users are game developers,” says Raymond Arifianto, AccelByte’s vice president of Technology, “they don’t want to spend time managing infrastructure”.
For many multiplayer games, the players in a session need to exchange packets with each other and send instructions and information to an authoritative game server to play synchronously. These game servers are responsible for running the simulations, so when you hit an action button to move or jump, that needs to travel to the server, run some simulation, and return that state to everyone in the session. That all has to happen in subseconds, otherwise players might experience rubberbanding, lag, or even session disconnection, so having low latency — or ping time — is critical to performance.
Arifanto stressed the importance of maintaining this performance when geographic regions experience increased demand. “Say a popular European streamer goes live. We might see a spike in users out of that location. This is where autoscaling — being able to adapt very quickly to the number of servers you need to spin up on the southern regions — suddenly becomes very important.”
AccelByte needed to find a solution to manage its fleet of game servers that run on provider-agnostic cloud and bare-metal machines across multiple regions. The company started off using Kubernetes and Agones to handle the lifecycle of the game servers and faced several challenges, the biggest one being the limit on open ports for a given cluster.
”Depending on the game, one session could have 4 players, or upwards of 100 players, like Battle Royale,” Arifanto said. “If a game suddenly becomes popular, you could have a million players online at once and run out of ports.”
AccelByte was also running into issues with federating Kubernetes clusters at the scale it needed. The company has separate dev, staging, and prod environments. Each of those have different regions set up, and each region has a different number of clusters.
“Managing all of our clusters with Kubernetes took too much time and added unnecessary complexity to operations. We have the same federation architecture with Nomad, but now deployments are easier and management is simpler,” Arifanto said. With Nomad, AccelByte is currently managing 22 clusters across 13 regions.
AccelByte’s Nomad clients connect to its Dedicated Service Manager (DSM) using a VPN. The DSM stores deployment configurations that are defined from the Admin Portal and communicate with Nomad to deploy dedicated servers to be used in matchmaking. Each client has a different requirement on where the regions are deployed and what the characteristics of the servers are. “With Nomad, we can be really precise and have full control over what gets spun up and where,” Arifanto noted.
»Managing Heterogeneous Edge Environments
Edge environments are often heterogeneous and can consist of various processors, operating systems, network topologies, device types, and workflows. Nomad’s flexible workload support allows users to support a variety of applications to meet any existing configuration, which is critical for edge devices that might be ARM-based or running on Windows. Pluggable task drivers provide a degree of separation of Nomad client CPU, memory, and storage between tasks and allow air-gapped environments where devices can’t share or centralize their data. Even in those situations, you are able to manage various devices in a single cluster and operate with a unified workflow. By having extensible task drivers, Nomad can manage a broad set of workloads across all major operating systems. Nomad’s support for device plugins allows it to take advantage of hardware running on specialized devices which is especially useful for IoT, smart transport, or in-store technology.
»Case Study: Radix Labs
Radix Labs is a lab automation company that builds programming languages, operating systems, compilers, and clouds for the computer architecture of biology labs. Within a biology lab, there is a variety of analytic equipment — devices such as DNA sequencers and liquid handlers — that need to be manually operated to run an experiment or specific protocol. Radix’s software turns lab protocols into code and automates execution across various machines by turning all of the instrumentation at the edge into a cloud, scheduling drivers and compute jobs on the cloud, and building an OS kernel to manage and automate running processes written in its programming language.
Radix uses a number of Nomad task drivers to operate such a diverse set of instrumentation. The Nomad exec driver allows Radix to run as root and access equipment like mass spectrometers and centrifuges by fingerprinting them and creating instrument-specific drivers. The company deploys a majority of its software through JAR files with the Java task driver and customer devices are spun up in Firecracker to maintain a strong degree of isolation. To extend this isolation, Radix havs chosen to operate each customer site in separate Nomad clusters.
“We chose Nomad for Windows support and operational simplicity,” said Dhash Shrivathsa, the founder and CEO of Radix. “Our customer sites are very heterogeneous, and in some of our smaller installs, no two nodes are the same. There could be Windows XP, Windows 10, Linux, and Raspberry Pis all being managed in one cluster.” To more easily manage its fleet of short-lived Nomad clusters, Radix built Timberland, an installation and remote management configuration tool with its own module system based around Terraform files. Timberland can bootstrap a Consul/Nomad/Vault cluster with SSL and permissions. The Radix platform is also designed to accommodate large-scale customer deployments.
»Nomad Offers Flexibility and Control on the Edge
There are an increasing number of use cases across industries for distributing location-sensitive applications outside of centralized datacenters and running them closer to where they are needed. Managing these applications across a fleet of distributed, heterogeneous, and dynamic edge devices and infrastructure can be challenging. With Nomad, you can build a single, consolidated workflow that gives you the flexibility and control necessary to fit the unique requirements of each application at the edge. If you want to learn more about how you can use Nomad to deploy and manage edge workloads, check out this HashiCorp Learn guide, Schedule Edge Services with Native Service Discovery, which walks you through deploying a single Nomad server cluster with edge clients in two AWS regions.






