

How could you enable secure and auditable access from outside a Kubernetes platform without using a traditional Kubernetes Ingress Controller? Can this be achieved in a way that improves the security posture of both application content and components while leveraging a strong notion of identity to authenticate and authorize access?
Consider a scenario. You are part of a product team, delivering an application or service that’s hosted in a Kubernetes environment — perhaps a cloud-hosted xKS solution, maybe K3s, or a more opinionated offering such as Red Hat’s OpenShift Container Platform. The components of your application may exist in one namespace, or indeed be spread across multiple namespaces. You want to enable secure external access to the content and components of your application for debugging and maintenance purposes without compromising the security of either the platform or the application.
This post considers an alternative take on traditional Kubernetes Ingress Controllers, using HashiCorp Boundary to enable secure, controlled ingress to workloads hosted on Kubernetes. For this proof of concept, you will need to deploy and configure your own Kubernetes and HashiCorp Cloud Platform (HCP) Boundary clusters (documentation links provided). In addition, you’ll need administrative access with the appropriate tooling for both Boundary and Kubernetes. Later on in the blog, references will also be made to the Boundary desktop client.
HCP Boundary is HashiCorp’s fully managed, cloud-hosted Boundary offering (the first 50 sessions per month are free). The concepts in this blog are also applicable to Boundary Enterprise.
»What is an ingress controller?
Typically, when working with a Kubernetes platform there will come a point in time when you want to expose the workloads that you’re hosting on your Kubernetes platform to a wider audience. This may be to an audience within a department, an organization, or even to public consumers. Broadly speaking, this is achieved through the use of the ingress controller configured within your Kubernetes platform.
There are a vast number of ingress controllers available, both commercially and community-supported. Some Kubernetes distributions will even ship with an ingress solution pre-configured and ready to go.
For this proof of concept, a self-managed deployment of Red Hat’s OpenShift Container Platform was used as the Kubernetes platform, which ships with an ingress implementation based on HAProxy. However, it should be noted that the specifics of the Kubernetes platform and its ingress controller are largely irrelevant, as this workflow relies on core Kubernetes resources that will be available irrespective of the platform provider.
»What is HashiCorp Boundary?
Fundamentally, Boundary is not an ingress controller. It doesn’t even pretend to be one. Boundary is an identity-aware proxy aimed at simplifying and securing least-privileged access to cloud infrastructure.
From an administrator’s point of view, Boundary provides a simple way for authenticated users to have secure, authorized access to cloud and self-managed infrastructure without exposing the target networks to the end user, or (depending on the use case) requiring the use of managed credentials.
From an end user’s point of view, Boundary offers a standardized workflow for connecting to infrastructure resources, wherever they reside. Through the use of Boundary’s consistent access workflow, end users no longer need to be concerned about managing a list of target resources they require access to, nor do they need to manage the myriad of credentials such use cases usually require.
»Architecture
At a high level, the architecture for our proof of concept looks like the following diagram:
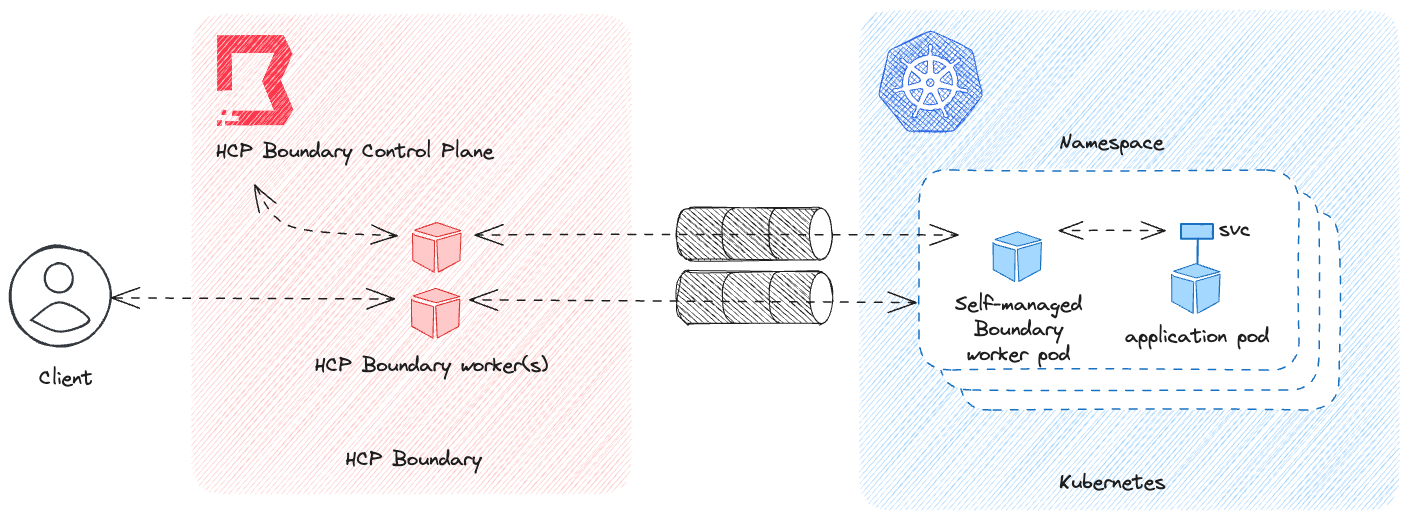
Figure 1 - High-level architecture for Boundary-Kubernetes ingress proof of concept
The approach above requires the configuration of a self-managed Boundary worker within a target Kubernetes namespace, authenticating itself and establishing trust with the HCP Boundary control plane.
This pattern works without the explicit use of an ingress method because the Boundary worker handles establishing connectivity back to the HCP Boundary control plane. The worker uses its HCP cluster ID to discover the implicit HCP Boundary workers associated with its Boundary cluster, and proxies its connection through these back to the control plane. There’s no inbound traffic that needs to reach into the Kubernetes namespace from outside the Kubernetes cluster in order to establish the connection.
Once Boundary is configured in the manner described in this post, a client can establish a connection with private resources adjacent to the self-managed Boundary worker using what Boundary refers to as a multi-hop session. A multi-hop session is when two or more workers — in this case, an implicitly configured HCP Boundary worker and the self-managed Boundary worker — are chained together creating multiple ‘hops’ from the client to the target. Once this multi-hop session is established, it can be used to access Kubernetes-hosted resources listening on a standard Kubernetes service IP/port — no ingress solution required!
»Building the Boundary worker container image
For this walkthrough, you will need an HCP Boundary cluster. You can follow our Deploy HCP Boundary and log in tutorial if you don’t have an existing cluster set up.
Once your initial environment is set up, you will start by building a Boundary worker image. In order to do this, use Red Hat’s Minimal Universal Base Image (UBI) for Red Hat Enterprise Linux 9 as the base image along with the HashiCorp-provided RPM packages installed and configured on top of that.
This small form-factor base image provides everything required to run the Boundary worker.
FROM registry.access.redhat.com/ubi9-minimal:latest
USER root
RUN microdnf -y install yum-utils && \
yum-config-manager --add-repo https://rpm.releases.hashicorp.com/RHEL/hashicorp.repo && \
microdnf -y install boundary-enterprise && \
mkdir -p /opt/boundary/{data,config} && \
cp /etc/boundary.d/worker.hcl /opt/boundary/config/
RUN chgrp -R 0 /usr/bin/boundary && \
chmod -R g=u /usr/bin/boundary && \
chgrp -R 0 /opt/boundary && \
chmod -R g=u /opt/boundary
USER boundary
ENTRYPOINT ["boundary"]
CMD ["server", "-config=/opt/boundary/config/worker.hcl"]
Let’s break down this Containerfile a little bit.
FROM registry.access.redhat.com/ubi9-minimal:latest
...
RUN microdnf -y install yum-utils ...
This UBI image is a freely distributable, minimal footprint container image that ships with a lightweight version of the DNF package manager called microdnf. This is used to install the package needed to add the HashiCorp RPM repository, and then install the Boundary Enterprise package.
cp /etc/boundary.d/worker.hcl /opt/boundary/config/
Once this is done, the default template Boundary configuration (provided by the installer) can be moved to where it needs to be on the filesystem. This represents the bare minimum configuration required to run a Boundary worker to completion — nothing more.
RUN chgrp -R 0 /usr/bin/boundary ...
Given that this image will need to conform to the security requirements of the platform on which it runs — in this case, Red Hat OpenShift Container Platform — the container image needs to support execution as an arbitrary UID. These updates simply ensure that when the Boundary process is run, it has access to the filesystem resources that it requires.
ENTRYPOINT ["boundary"]
CMD ["server", "-config=/opt/boundary/config/worker.hcl"
Once the basic image is defined, the ENTRYPOINT and command (CMD) to run the Container image can be configured. This also establishes a fixed path for the Boundary worker configuration that can be overridden at runtime.
»Boundary worker configuration
Once the image has been built and pushed to a container registry location that’s resolvable from the Kubernetes cluster, the Boundary worker itself can be configured. This is done via a file written in the HashiCorp Configuration Language (HCL: a common DSL used across HashiCorp’s products) which will then be presented to the running container in its Pod as a Kubernetes ConfigMap.
disable_mlock = true
hcp_boundary_cluster_id = "env://HCP_BOUNDARY_CLUSTER_ID"
listener "tcp" {
address = "0.0.0.0:9202"
purpose = "proxy"
}
listener "tcp" {
address = "0.0.0.0:9203"
purpose = "ops"
tls_disable = true
}
worker {
controller_generated_activation_token = "env://CONTROLLER_GENERATED_ACTIVATION_TOKEN"
auth_storage_path = "/opt/boundary/data"
tags {
type = ["openshift", "kubernetes"]
namespace = "application"
}
}
As with the Containerfile, it helps to examine the configuration file in a bit more detail. In this example there are six particular elements that will be of interest.
hcp_boundary_cluster_id = "env://HCP_BOUNDARY_CLUSTER_ID"
The HCP Boundary cluster ID is a unique identifier that allows the Boundary worker you’ve built to discover the HCP Boundary cluster it is aligned with. As this is passed in as an environment variable, it allows the Boundary worker configuration to be configured completely agnostic of the HCP Boundary cluster it is supposed to be registering with.
listener "tcp" {
address = "0.0.0.0:9202"
purpose = "proxy"
}
The listener block defines the address and port combination on which the Boundary worker serves traffic. Each Boundary worker will have this single mandatory listener labeled proxy. The default port for the listener is 9202, but this is configurable.
listener "tcp" {
address = "0.0.0.0:9203"
purpose = "ops"
tls_disable = true
}
A second, optional listener block called ops allows access to the operational endpoints of the Boundary worker. In this case, these are used to expose Prometheus-format metrics to observability components within the Kubernetes cluster. The default port for this is 9203, but again, this is configurable.
controller_generated_activation_token = "env://CONTROLLER_GENERATED_ACTIVATION_TOKEN"
The CONTROLLER_GENERATED_ACTIVATION_TOKEN is a single-use credential initially provided by the system administrator to the Boundary worker as a means of authenticating and authorizing the worker with the HCP Boundary control plane. This is Boundary’s controller-led authorization workflow in action, one of two methods that can be used to register a worker with a cluster. In this example, the token is configured as an environment variable.
The second method that could be used to register the Boundary worker is the worker-led authorization workflow. This just isn’t practical in the containerization use case as it requires user intervention at runtime, which is not ideal in a Kubernetes cluster. See the following link for more information on authorization methods in Boundary.
auth_storage_path = "/opt/boundary/data"
It should be noted that the auth_storage_path aligns with one of the file paths created and managed as part of the initial container image creation. This is more important when it comes to configuring how the Boundary worker is deployed within the Kubernetes platform. A persistent volume resource will be mounted at this location.
tags {
type = ["openshift", "kubernetes"]
namespace = "application"
}
Tags are a very useful, arbitrary, metadata construct within Boundary. At the time of writing, they allow traffic for a given set of Boundary targets to be proxied through through a specific worker or group of workers. In this instance, there are a pair of tags that define the type of platform the Boundary worker is deployed on (OpenShift/Kubernetes), as well as a namespace tag that matches the Kubernetes namespace into which the Boundary worker is deployed. In this setup, Boundary sessions destined for Boundary targets within this Kubernetes namespace can be routed explicitly through this Boundary worker.
A broad overview of the configuration file and its syntax can be found in the HashiCorp Boundary documentation.
»Registering the Boundary worker
Because the method being used to register the Boundary worker in Kubernetes with the HCP Boundary cluster is the controller-led authorization workflow, this initial configuration to retrieve the one-time activation token must be carried out by an human operator. This token can subsequently be used by the Boundary worker to authenticate and authorize itself with the HCP Boundary control plane.
It sounds complex, but the process is very simple and can be undertaken from the Boundary CLI once authenticated with the HCP Boundary cluster:
% boundary workers create controller-led -name=kubernetes-applications-worker
Worker information:
Active Connection Count: 0
Controller-Generated Activation Token: neslat_...
Created Time: Tue, 19 Sep 2023 13:46:55 BST
ID: w_HmpjVGqXyj
Name: kubernetes-applications-worker
Type: pki
Updated Time: Tue, 19 Sep 2023 13:46:55 BST
Version: 1
Scope:
ID: global
Name: global
Type: global
Authorized Actions:
no-op
read
update
delete
add-worker-tags
set-worker-tags
remove-worker-tags
See? Done.
Contained within the registration response is the field containing the controller generated activation token. It is this value that should be presented as the CONTROLLER_GENERATED_ACTIVATION_TOKEN environment variable in the Boundary worker configuration so that it can complete the registration process with the HCP Boundary control plane.
It is worth noting that once the Boundary worker starts, it is safe to keep this token in the environment variable even after the worker has successfully authorized and authenticated because it will be unusable after that point.
»Deploying the Boundary worker
Now that the Boundary worker container image is built and the activation token has been acquired from HCP Boundary, the Boundary worker can be deployed.
In this instance, the Boundary worker will be deployed on Kubernetes as a StatefulSet. While the Boundary worker is not an inherently stateful application, the use of the controller-led authorization workflow means that it does need persistent storage in order to hold onto the registration data it receives from the HCP Boundary control plane. This could be achieved with a standard Kubernetes deployment but it is conceptually beneficial to enforce a one-to-one mapping between the Boundary worker Pod and its persistent volume.
This mapping is helpful because scaling up a Kubernetes deployment to provision multiple replicas of the Boundary worker will cause a registration race condition; each replica continuously attempts to register, will be successful, and then will lose contact when the next replica successfully registers using the same registration data sourced from the same Persistent Volume. The end result is that none of the replicas stay available long enough to be usable.
By using a StatefulSet, the architecture is still bound to a single Boundary worker per StatefulSet — there’s no getting away from that — but there’s no shared storage and therefore no shared registration data to handle. Any instance other than the original will simply fail to authenticate to the HCP Boundary control plane without interrupting the operations of the original instance, all while retaining the self-healing attributes naturally present in Kubernetes Pods.
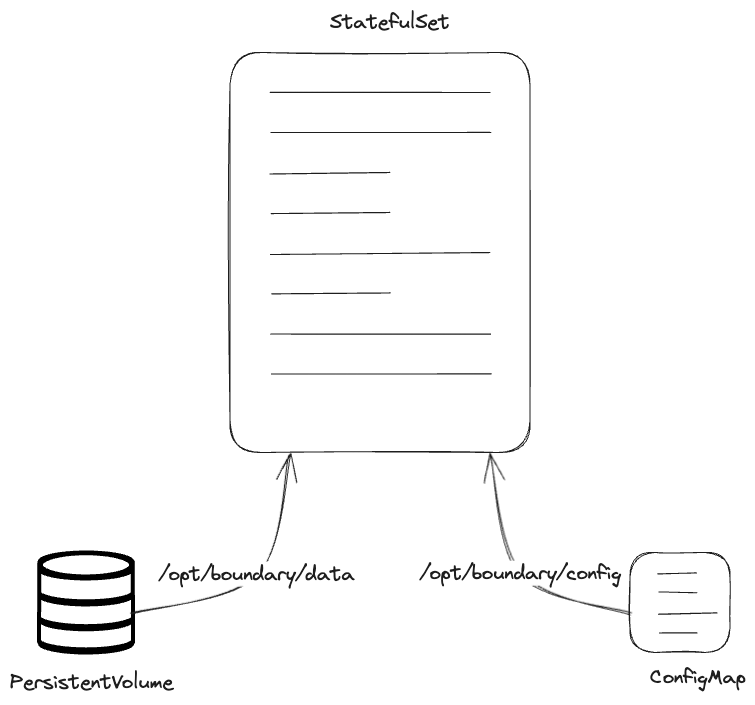
Figure 2 - Kubernetes resources
Figure 2 describes the Kubernetes resources that will be created and utilized. Both the PersistentVolume and ConfigMap will be mounted into the resulting Pod at the paths explicitly stated in the Containerfile: /opt/boundary/data and /opt/boundary/config respectively.
Once the resources have been applied, the Boundary worker should use its configuration, consumed from the ConfigMap, to register itself with its HCP Boundary cluster. Looking at the Pod logs should yield a ‘server started’ message similar to the one below:
==> Boundary server configuration:
Cgo: disabled
Listener 1: tcp (addr: "0.0.0.0:9202", max_request_duration: "1m30s", purpose: "proxy")
Listener 2: tcp (addr: "0.0.0.0:9203", max_request_duration: "1m30s", purpose: "ops")
Log Level: info
Mlock: supported: true, enabled: false
Version: Boundary v0.13.2+ent
Version Sha: b1f75f5c731c843f5c987feae310d86e635806c7
Worker Auth Storage Path: /opt/boundary/data
Worker Public Proxy Addr: 0.0.0.0:9202
==> Boundary server started! Log data will stream in below:
A successful registration can subsequently be confirmed by examining the Workers tab in the HCP Boundary admin UI.
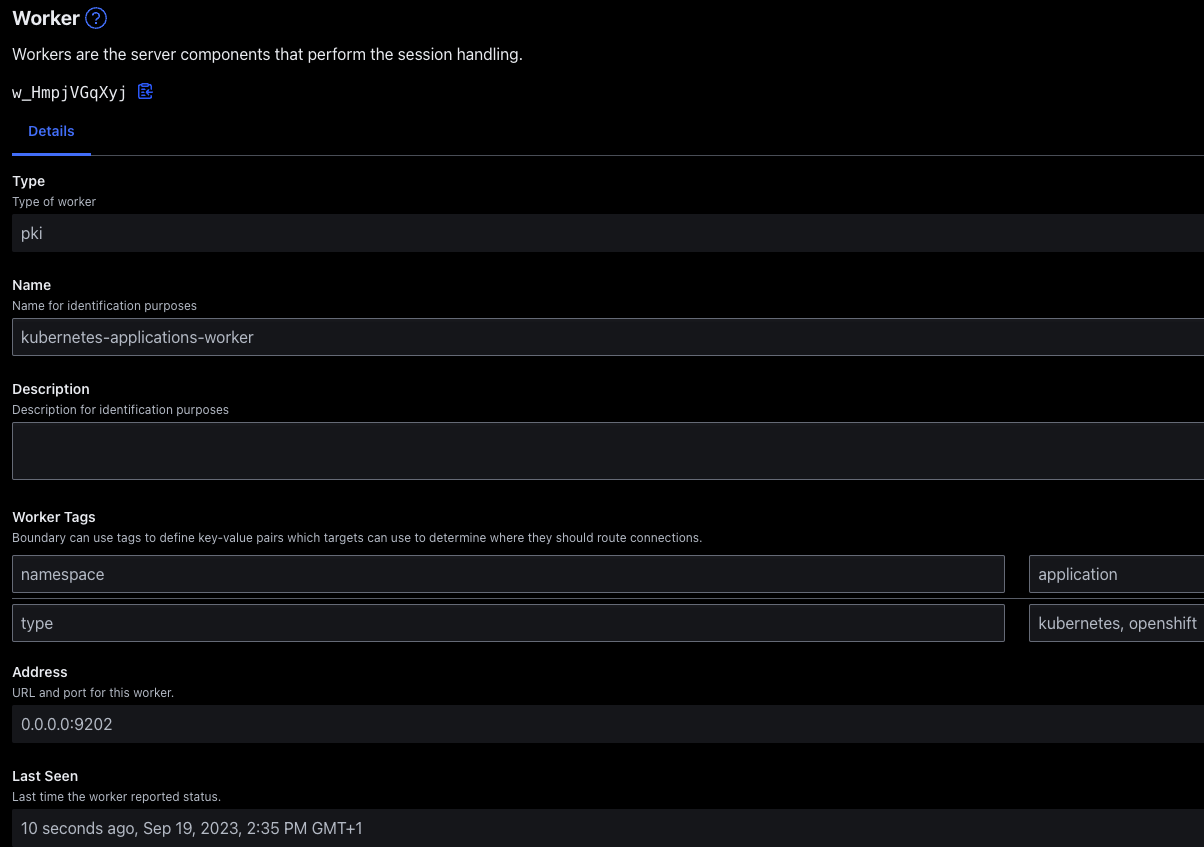
Figure 3 - Worker registration UI
The name of the Boundary worker should align with the name provided when initiating the controller-led authorization workflow. The tags configured for the Boundary worker should also be visible if they have been successfully read from the Boundary worker configuration. In this example, the namespace tag has been propagated to the HCP Boundary control plane, which will enable filtering of Boundary targets by Boundary worker.
»Setting a Boundary target
One of the reasons that Red Hat OpenShift Container Platform was chosen as the target operating environment for this proof of concept, is that it is supplied with a plethora of example applications and services ready to be deployed out of the box. Given that any Boundary target demonstration doesn’t need to be particularly sophisticated, two examples have been selected from OpenShift’s catalog to demonstrate Boundary’s capabilities: a basic Node.js application, and a PostgreSQL database.
Figure 4 - Example Node.js application
This example application is clearly being resolved via its Fully Qualified Domain Name (FQDN) and is therefore an ingress solution. For this walkthrough, you will remove the FQDN when the time comes to use Boundary as the method of communicating with these workloads.
What actually matters here, from a networking perspective, is the actual Kubernetes services that will be used as the Boundary targets. We can examine those with a simple kubectl command.
% kubectl get services -n application
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) ...
boundary-worker ClusterIP None 9202/TCP,9203/TCP
nodejs-basic ClusterIP 172.30.38.208 3001/TCP
postgresql ClusterIP 172.30.199.135 5432/TCP
Some of this output has been omitted for brevity, but it clearly shows the IP address and the port(s) provisioned for the Node.js application and the PostgreSQL database respectively.
This information can be used to configure a Boundary target within the HCP Boundary cluster. This is accomplished using the Targets tab within the Boundary admin UI.
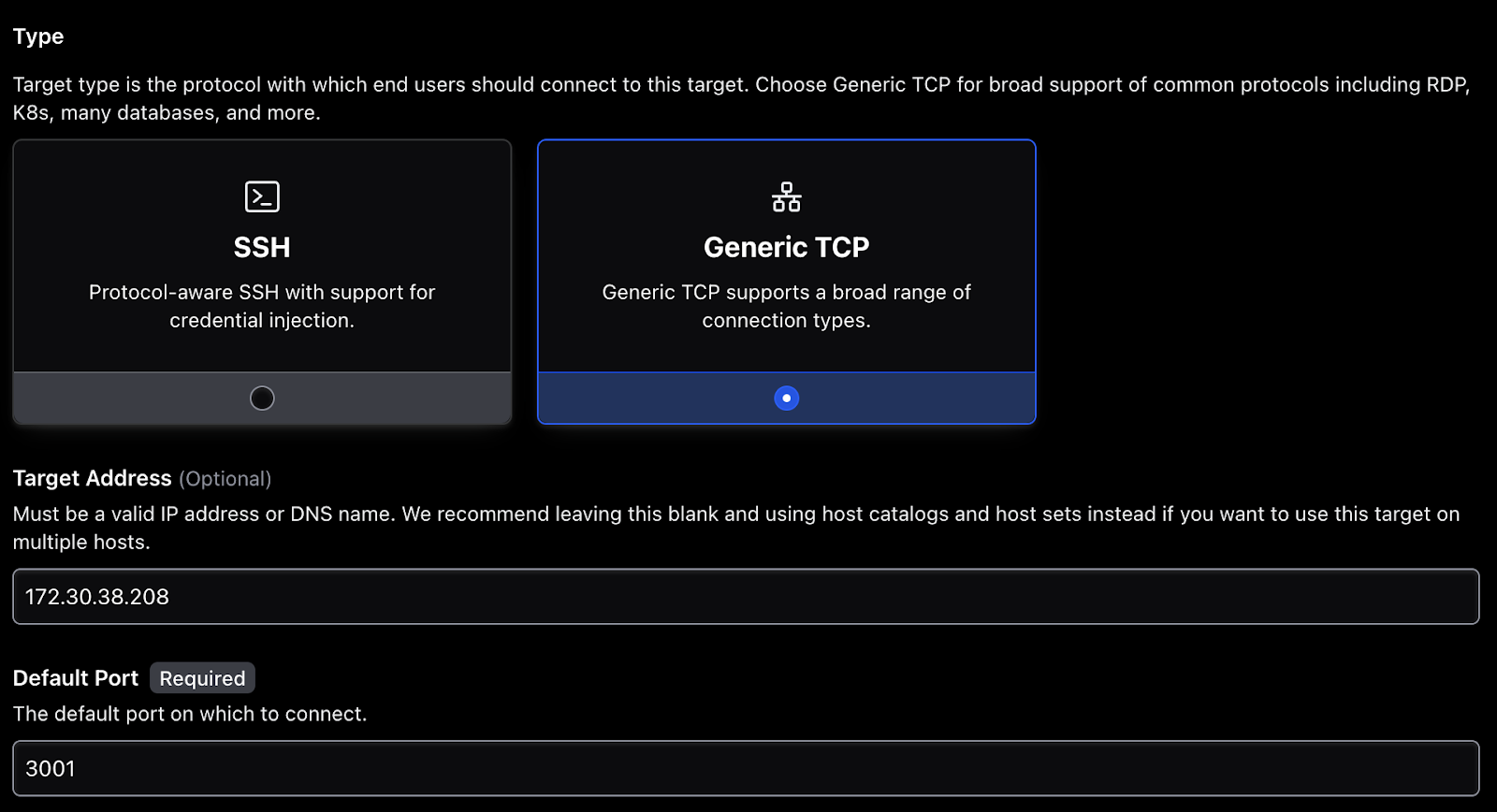
Figure 5 - Configuring a generic TCP target
In Figure 5, the IP address and port combination of the Kubernetes service will be used to complete the Target Address and Default Port fields within the HCP Boundary admin UI.
The next element of the Boundary target configuration is presented further down the same page — the section titled Workers. In this section, the egress worker can be defined using the same set of tags in the Boundary worker configuration shown previously. This enables the multi-hop behavior alluded to earlier.

Figure 6 - Configuring the egress worker filter
The steps above are required to configure the Node.js application as a Boundary target. The process is repeated for the PostgreSQL database, with the result being that there are now two Boundary targets configured within the HCP Boundary admin UI that can be used to access resources embedded within the Kubernetes cluster.
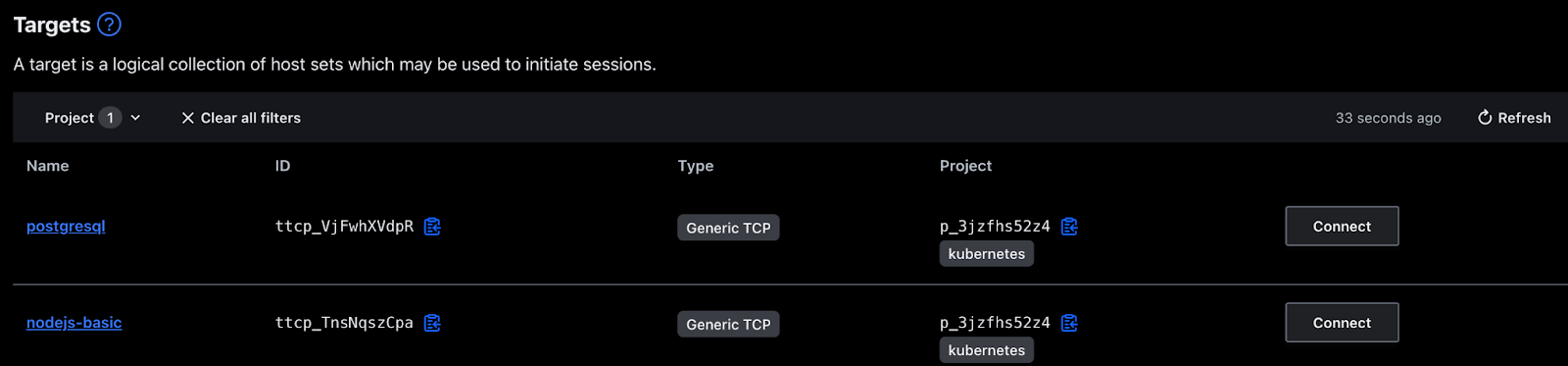
Figure 7 - Boundary targets
»Connecting to the Boundary targets
Now that the Boundary targets are configured, they are usable from within Boundary itself. Using either the Boundary Desktop client or the Boundary command line interface (CLI), an end user — once authenticated and authorized with Boundary using one of the provided authentication methods — can simply connect to the Boundary target and start working with it. The end user doesn’t need to know anything about the target addresses or ports required to access the target.
From the UI, this is as simple as clicking on the Connect button, which displays a pop-up confirming the status of that action and, if successful, the proxy information required to access the Boundary target.
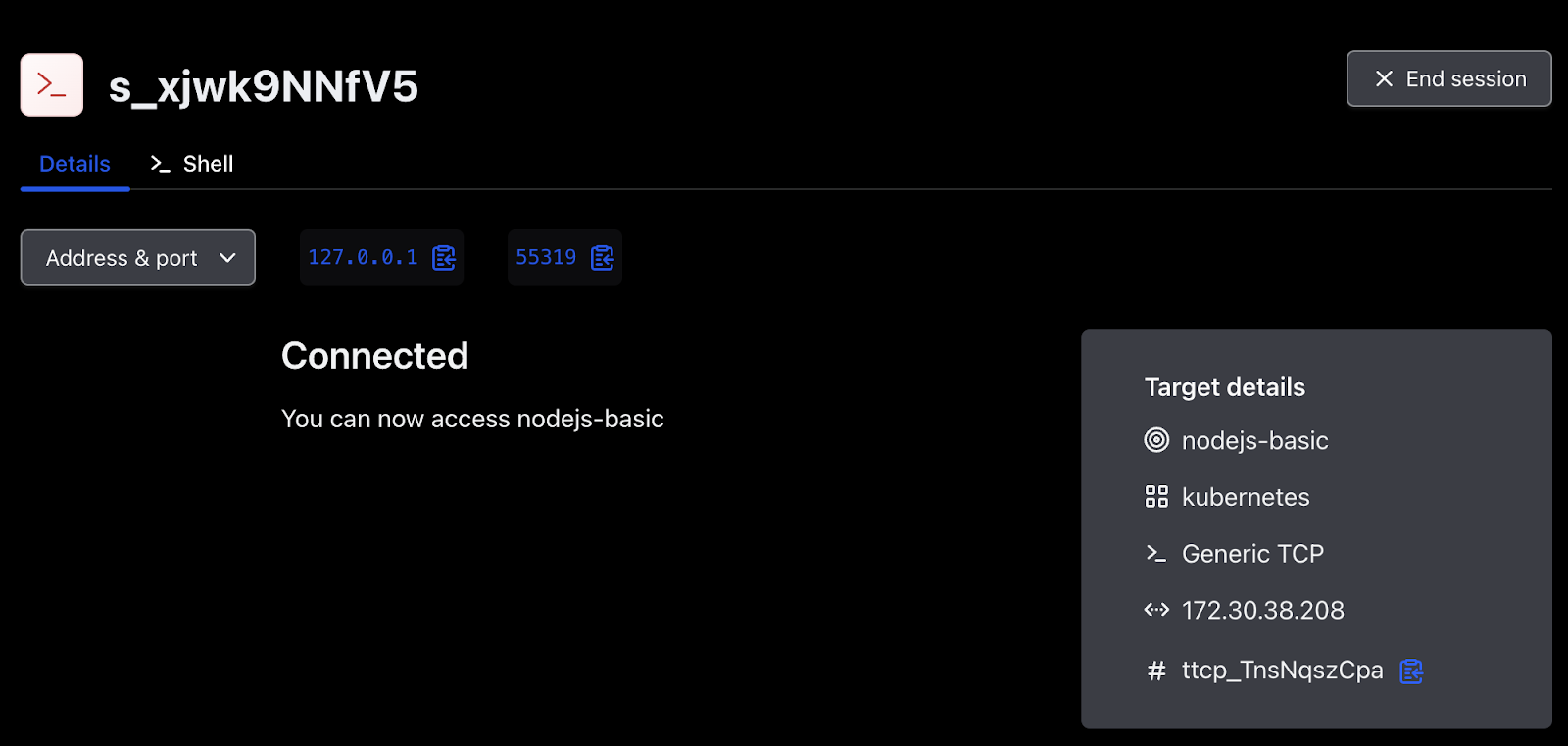
Figure 8 - A successful connection to the nodejs-basic Boundary target
Opening a web browser to this proxy address yields the same content displayed in Figure 4.
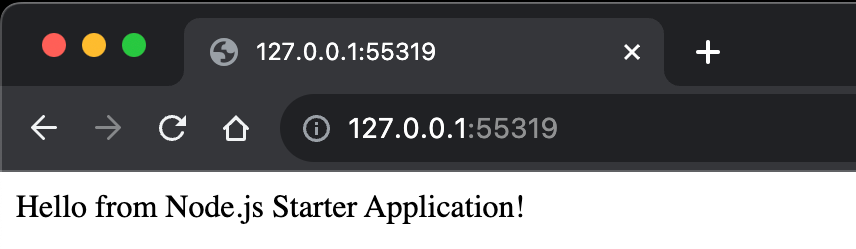
Figure 9 - Example Node.js application accessed via a Boundary session
The same Boundary Desktop client workflow can be used to initiate a further connection to the PostgreSQL database running in the Kubernetes cluster. The end user may then connect using the presented proxy information from the psql CLI tooling.
% psql -h 127.0.0.1 -p 55376 -U myapp -d boundary-example
Password for user myapp:
psql (16.0, server 10.23)
Type "help" for help.
boundary-example=>
In the CLI extract presented above, the presence of a credential is clearly requested — and provided — as part of the authentication exchange. However, allowing end user visibility on specific credentials is not always desirable, as it can lead to credential management issues further on. Generally, you don’t want credentials written on a note, captured in a file on the user’s machine, or accidentally committed to source control.
To prevent these kinds of credential mishandling issues, Boundary can make use of its credential management capabilities — in this case brokered credentials — to implicitly supply the credentials for that PostgreSQL database into the Boundary session when the session is established. This removes the need for the end user to ever know what those credentials actually are. In this workflow, Boundary is simply providing access to a system that the authenticated end user is permitted to access based on Boundary’s access rules.
% boundary connect postgres -target-name=postgresql -target-scope-name=kubernetes -dbname=boundary-example
psql (16.0, server 10.23)
Type "help" for help.
boundary-example=>
Although brokered and injected credentials will not be covered in detail here, credential management is an incredibly powerful aspect of Boundary that can help to enforce a zero trust posture around human-to-machine access, irrespective of where the machine — or the human — is located.
»Boundary Worker Operator
In an effort to make the configuration and deployment of a Boundary worker on Kubernetes as easy to undertake as possible, a companion Kubernetes Operator is available. This project includes the Kubernetes setup elements described in this blog post, and can be found in the boundary-worker-operator GitHub project.
The Boundary Worker Operator requires the creation of a small custom resource that provides — at a very basic level — the ability to inform the Boundary worker of its HCP cluster ID and its controller-generated activation token.
apiVersion: workers.boundaryproject.io/v1alpha1
kind: BoundaryPKIWorker
metadata:
name: my-boundary-worker
Namespace: my-application
spec:
registration:
controllerGeneratedActivationToken: neslat_...
hcpBoundaryClusterID: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
Options exist for modifying the storage configuration for the worker, as well as its resource requests and limits. Furthermore, the custom resource also provides a way to preconfigure tags on the Boundary worker. Changes to any of these elements forces a reconciliation of the deployed worker’s state and the configuration will update as necessary.
This community-centric operator is the sole work of the author, and is not affiliated, supported or endorsed by HashiCorp in any capacity.
»Summary
In an effort to answer the original question, you can now hopefully see how the use of Boundary in this manner can help improve the security of application content and components hosted within Kubernetes. In this post, this was demonstrated in four key ways:
By removing an explicit ingress path to the Kubernetes workload(s) in question, we remove a potentially long-lived attack vector — the FQDN of that workload.
Despite being able to access Kubernetes-hosted resources, the end-user is not on the Kubernetes network. There’s no VPN or similar solution at play here that would allow direct traversal to other targets within the Kubernetes namespace or the wider cluster.
Boundary operates under the principle that every action is authenticated and authorized. A user must have established their identity with Boundary in order to access their configured Boundary targets. If no access rules exist for an authenticated user, then no Boundary targets are presented; a deny-by-default stance. This is in contrast to an application or component accessible over an FQDN which would have to solely rely on its own — or platform provided — security measures to secure itself.
The Boundary workflow presented here for accessing the PostgreSQL database was secured through the use of Boundary’s brokered credential capability. To expand on this concept: When Boundary is integrated with HashiCorp Vault, credentials for the Boundary targets can be vended on a just-in-time basis, with the credential lifecycle tightly bound to that of the Boundary session.
Finally, the artifacts used to build, deploy, and configure the Boundary worker used in this post have been published to this companion GitHub repository for the article.
The use of Boundary in this manner starts to open up some really exciting possibilities for human-to-machine access to resources hosted in a Kubernetes cluster. What kind of use cases would you be able to address using Boundary workers on Kubernetes?
Register on the HashiCorp Cloud Platform if you’d like to test drive HCP Boundary with 50 free sessions per month.









