

A commonly asked question on HashiCorp forums, posts, blogs, and even at conferences or webinars is: Should my organization use a monolithic source repository (mono epo) or multiple source repositories (multi-repo)? The short answer is this: It will depend on your organization and has everything to do with organizational patterns. This post will discuss the nuances of using each approach and when you should eventually break your monorepo into a multi-repo.
For the purposes of this blog post, a monorepo keeps many Terraform configurations as separate directories in a single repository. By comparison, a multi-repo approach organizes each Terraform configuration in a separate repository. What happens when you run terraform init? It uses go-getter to download all needed modules and, in essence, behaves like a monorepo. While Terraform supports the local referencing of modules, it handles the sourcing of remote modules, which lends well to a multi-repo structure.
»Monolithic source repositories (Monorepos)
When we refer to monorepos, do we include application code and its infrastructure? In this blog, we focus on a monorepo for infrastructure components, such as networking, compute, or software as a service (SaaS) resources.
Monorepos work if you have a personal project or a smaller team, and you need visibility into all of the infrastructure you're creating and uniform access to your configurations. What kind of monorepo structure will help you get the most out of your collaboration efforts and infrastructure as code? In a monorepo, divide your modules into a separate folder with the smallest grouping of resources and their dependencies. For example, you create individual module folders for AWS lambda (function), queue, and virtual network (vpc).
> tree my-company-functions
└── modules
├── function
│ ├── main.tf // contains aws_iam_role, aws_lambda_function
│ ├── outputs.tf
│ └── variables.tf
├── queue
│ ├── main.tf // contains aws_sqs_queue
│ ├── outputs.tf
│ └── variables.tf
└── vpc
├── main.tf // contains aws_vpc, aws_subnet
├── outputs.tf
└── variables.tf
To version modules, you can copy the module folder and append a version number to it. Otherwise, you might need to use some complex repository tagging to achieve versioning.
Then, separate environment configurations into individual folders per business domain, product, or team. The following example represents two business domains, one related to collecting document metadata and the other translating them, and two environments, production and staging.
> tree my-company-functions
├── modules
├── production
│ ├── document-metadata
│ │ └── main.tf
│ └── document-translate
│ └── main.tf
└── staging
├── document-metadata
│ └── main.tf
└── document-translate
└── main.tf
The configurations for production and staging reference the modules directory to create the function, queue, and network. This can be per business domain, product, or team. Some examples of dividing by business domain or team could be:
Infrastructure team
Shared services team (CI team)
Application / product team
Security team
To apply changes to configuration, you must develop a continuous integration pipeline to reference differences in each subdirectory, change directories, and apply changes in each directory individually.
»Advantages
A monorepo becomes a single source of truth to get all infrastructure configuration.
It consolidates infrastructure configuration for testing and debugging, which can be important for database testing, queues, event streaming, or data pipelines.
»Disadvantages
When you update modules over time, module maintenance overhead increases. Module and provider versioning and dependencies can be fairly confusing to debug in this paradigm. As a best practice, you should pin provider versions in each module. However, separating and versioning modules by subdirectory can make it difficult to debug which provider versions are used in each module.
In addition, your build system cannot scale as you create more subdirectories and environments. When you apply changes through a pipeline, you need to go into every folder and check for changes. Many CI frameworks use changesets to evaluate differences, which can increase your pipeline runtime.
Access control is applied to the entire monorepo by default. In some circumstances, you might only want a user or group to access specific subdirectories. For example, you may not want all team members to have access to change users and groups. This might be something that has to be approved first by an operations team in a
CODEOWNERSfile.
If you find yourself spending more time maintaining your build system logic to accommodate your infrastructure monorepo, you may want to break down your monorepo into multiple repositories.
»Multiple source repositories (multi-repos)
A multi-repo can better support granular access control and configuration changes. If you have a large team that collaborates on a complex infrastructure system, multiple source repositories allow you to localize changes and lessen the blast radius of failed infrastructure updates across the system. You can scope changes to the teams responsible for the infrastructure.
There are many approaches to organization your multi-repo. For example, you can divide each module into its own repository. In the case of the serverless function, queue, and network, you would create individual repositories for AWS lambda (function), queue, and virtual network (network). Individual business units or products would reference these remote modules. Environments would be captured by subdirectories in each product or business repository.
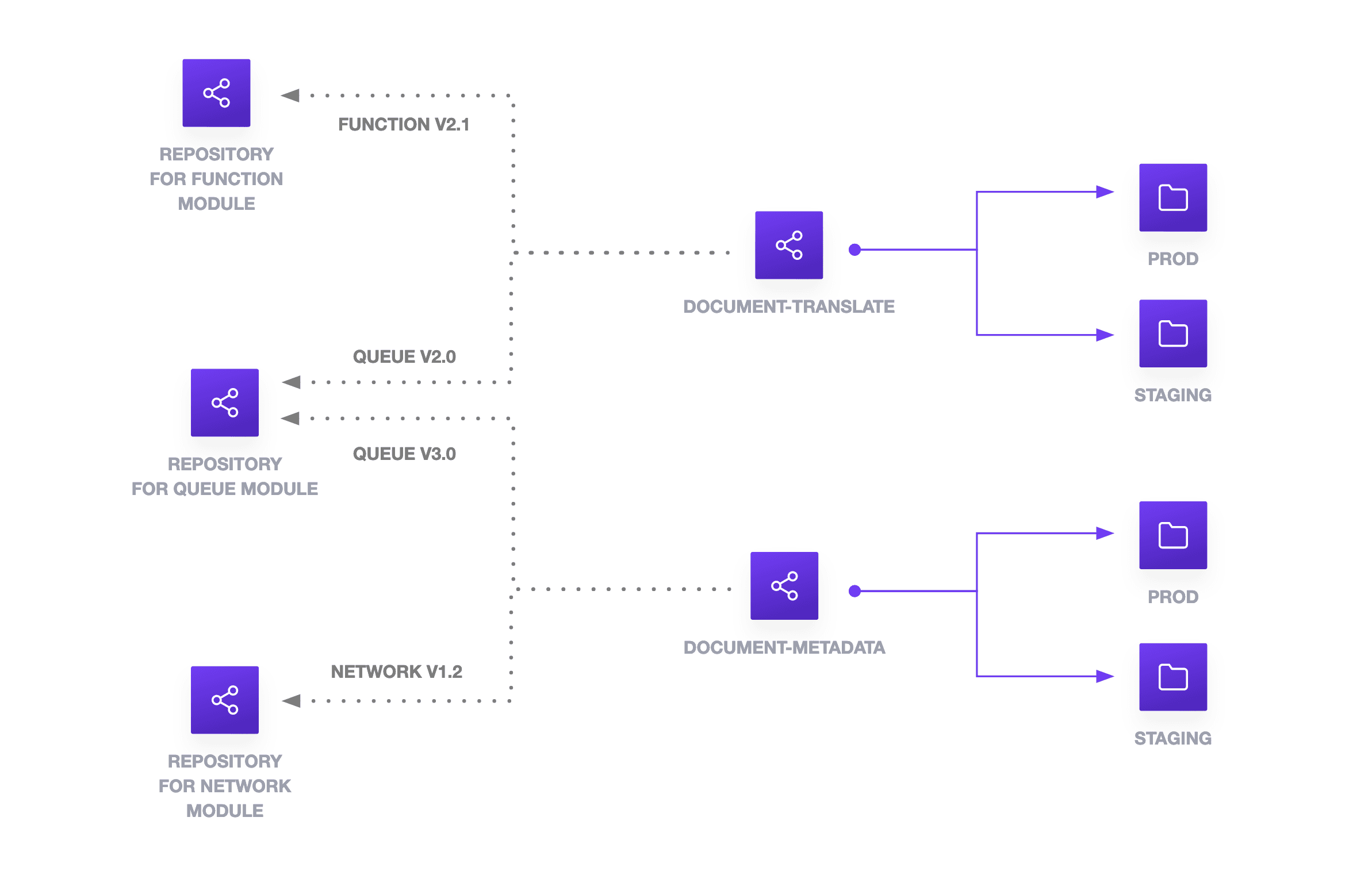
Use release tagging to handle the versioning of modules. By separating the modules into their own source repositories, you can test them independently, allow dependent configurations to reference the module version, and update the provider version with the module version.
You can further structure your multi-repo with separate repositories for each business domain, product, or team. Use subdirectories within these repositories to separate environments, which offers visibility into configuration differences between environments. Since you use a repository for each business domain or product, continuous integration pipelines have fewer subdirectories to recursively check for changes. You can optimize your pipelines for each configuration or module.
»Advantages
Multi-repos enable teams to self-service and compose based on shared building blocks.
Independent repositories allow isolated testing for module security & functionality.
You can apply module versioning using release tagging and existing tag constructs.
Individual repositories allow for access control of modules and configurations.
Scoping changes to a specific repository can minimize the blast radius of changes.
»Disadvantage
If you have a configuration that references many remote modules, Terraform will take time to download them. Try using git submodules to clone the remote repository and store it locally based on commit.
»Conclusion
There is no right or wrong answer when discussing the use of monorepos and multi-repos. By taking a step back and observing different organizational patterns, we can determine which environment structure works best for us.
For more information on separating configurations for environments, take a look at the Terraform Recommended Practices documentation. best practices for code for Terraform Cloud workspaces, review our documentation on code organization and workspace structure. To restructure your Terraform for production, review our blog on refactoring configuration. For best practices and pitfalls in a large Terraform monorepo, check out lessons learned from Terraform at Google. To try a hands-on example of breaking up a monorepo into separate dev and prod envoronments with a module shared between them, follow the Learn tutorial, Separate Development and Production Environments.
A summary image in bullets:







