


At HashiCorp, we hear every day from our customers and users about the security challenges they encounter on their journey to adopt dynamic cloud-based infrastructures. These challenges are primarily around ensuring a zero trust approach that prevents secrets sprawl, secures against data breaches, ensures compliance, and scales in an ephemeral, distributed multi-cloud environment. HashiCorp Vault allows them to do all of these things by providing a central, secure place to store and manage the secrets (API keys, passwords, certificates, etc.) that applications need in order to work with other applications and services, using an API-first approach to authenticate all requests, and provide secure access only to authorized resources.
Whether it’s a single team or an entire organization that’s planning to adopt Vault, you need to answer some questions first. One of the most important, our customers tell us, is how to make your applications Vault-aware.
»Making Your Applications Vault-Aware
In order to get secrets from Vault, your applications must integrate with Vault's API. If you take a manual approach to this integration, your application developers need to write and consistently maintain application code to:
Authenticate into Vault
Fetch and manage secrets from Vault
For some Vault deployments, this isn’t a problem, and may actually be preferred. For example, if you have only a handful of applications or you want to keep strict, customized control over the way each application interacts with Vault, you might be fine with the added overhead of maintaining that code and making sure a member of each application’s team is trained to understand Vault and that code.
In other situations — typically in large enterprises — updating each application’s code base could be a monumental task or simply a non-starter for several reasons:
If your organization has hundreds or thousands of applications you may not have the time, resources, or expertise to update and maintain Vault integration code in every application.
Your organization may not permit the teams deploying some applications to add the Vault integration code, or any code. For example, certain legacy applications may be too brittle to allow the addition of Vault integration code.
The applications (secrets consumers) and the systems (secrets originators) are, in many cases, managed by different teams. This makes coordinating the maintenance of Vault integration code into a clean workflow very difficult.
Some teams are deploying third-party applications that are not owned by the organization, and therefore it’s not possible to add Vault integration code.
For those situations, we recommend a much more scalable and simpler experience — using the Vault Agent.
»The Vault Agent
The Vault Agent is a service provided by the Vault binary that runs in the environment of the application. It was initially built to allow Vault's login and token refresh logic to exist outside of each application's code base, thus removing the requirement to add Vault integration code into individual applications. Today, it does a lot more than that. Here are some of the main features of the current Vault Agent:
»Automatic Authentication of Applications (Auto-Auth)
Vault is built on zero trust principles, so applications that need to fetch secrets from Vault are required to make authenticated requests against Vault by providing a Vault token. Vault Agent can make the authentication process for obtaining a Vault token easy and transparent to applications.
When Vault Agent starts up, it automatically authenticates into Vault and receives a Vault token, a process known as auto-auth. The Vault Agent supports multiple authentication methods depending upon the customer’s use case and environment. The token can then be written to disk to any number of file sinks. In addition to file permissions, the token can be protected through Vault's response-wrapping mechanism and encryption. Applications can then consume this token to make requests against Vault.
The Vault Agent also manages the lifecycle of the Vault token that is received from auto-auth. This includes timely renewal of the tokens and re-authentication if a token can no longer be renewed. The sink is updated with the new token value whenever re-authentication occurs.
The diagram below illustrates how the auto-auth process works without embedding any integration code into an application:
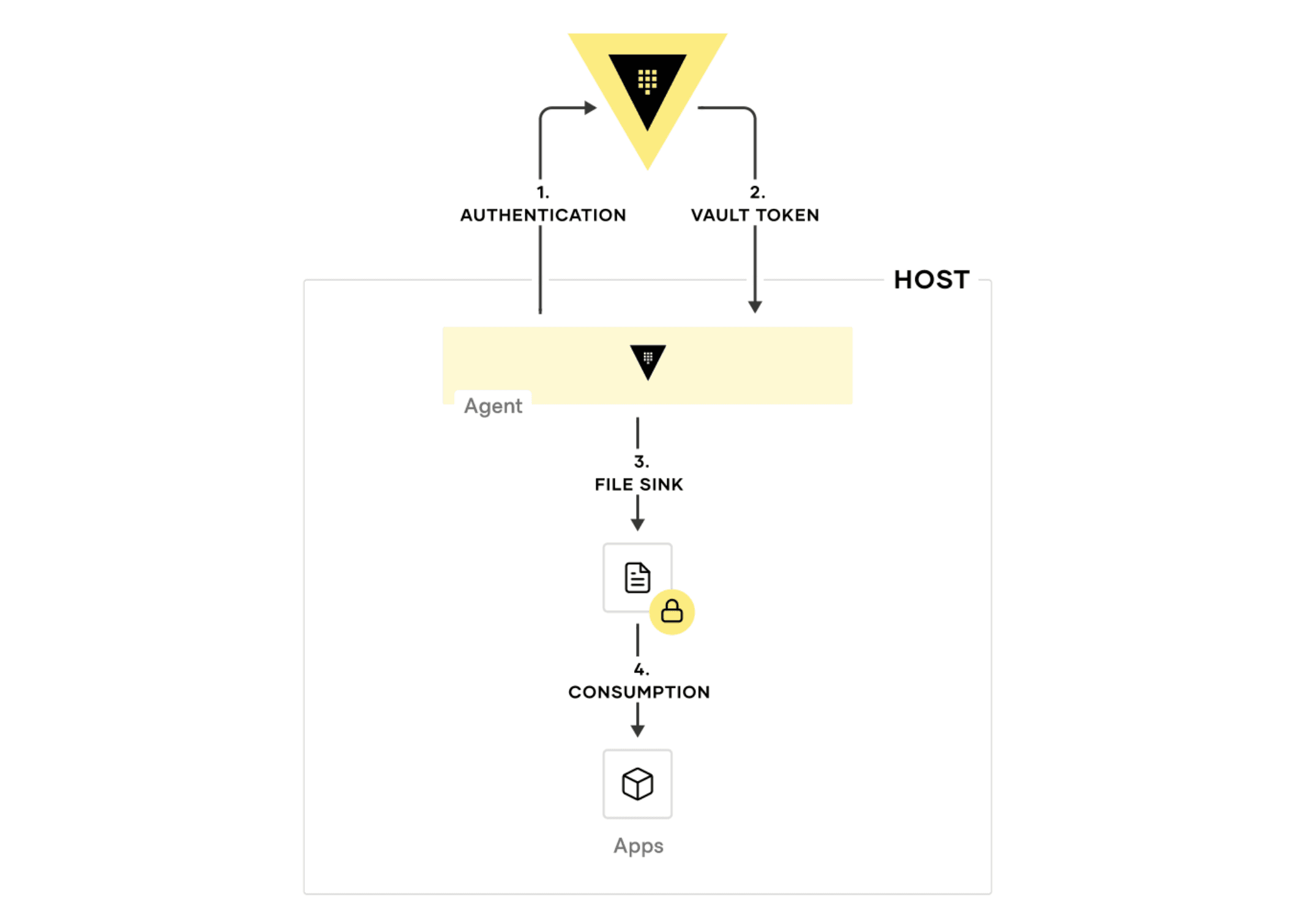
This example configuration shows how to set up auto-auth via AppRole along with multiple file sinks.
»Simplifying Secrets Consumption for Applications
The Vault Agent supports the ability to render static and dynamic secrets from Vault by using templates that describe how to render those secrets. Applications or service owners define these templates and then the secrets are consumed easily by the applications, eliminating the need for additional formatting and parsing. A common use case for templating is formatting credentials from Vault's database secrets engine to be rendered as database connection strings for applications to consume directly.
After the Vault Agent starts up and authenticates into Vault, it can be set up to retrieve secrets needed for an application. It renders these secrets to disk through the templates defined in the agent configuration, which the application can then use as needed.
The diagram below illustrates how the template consumption process works:
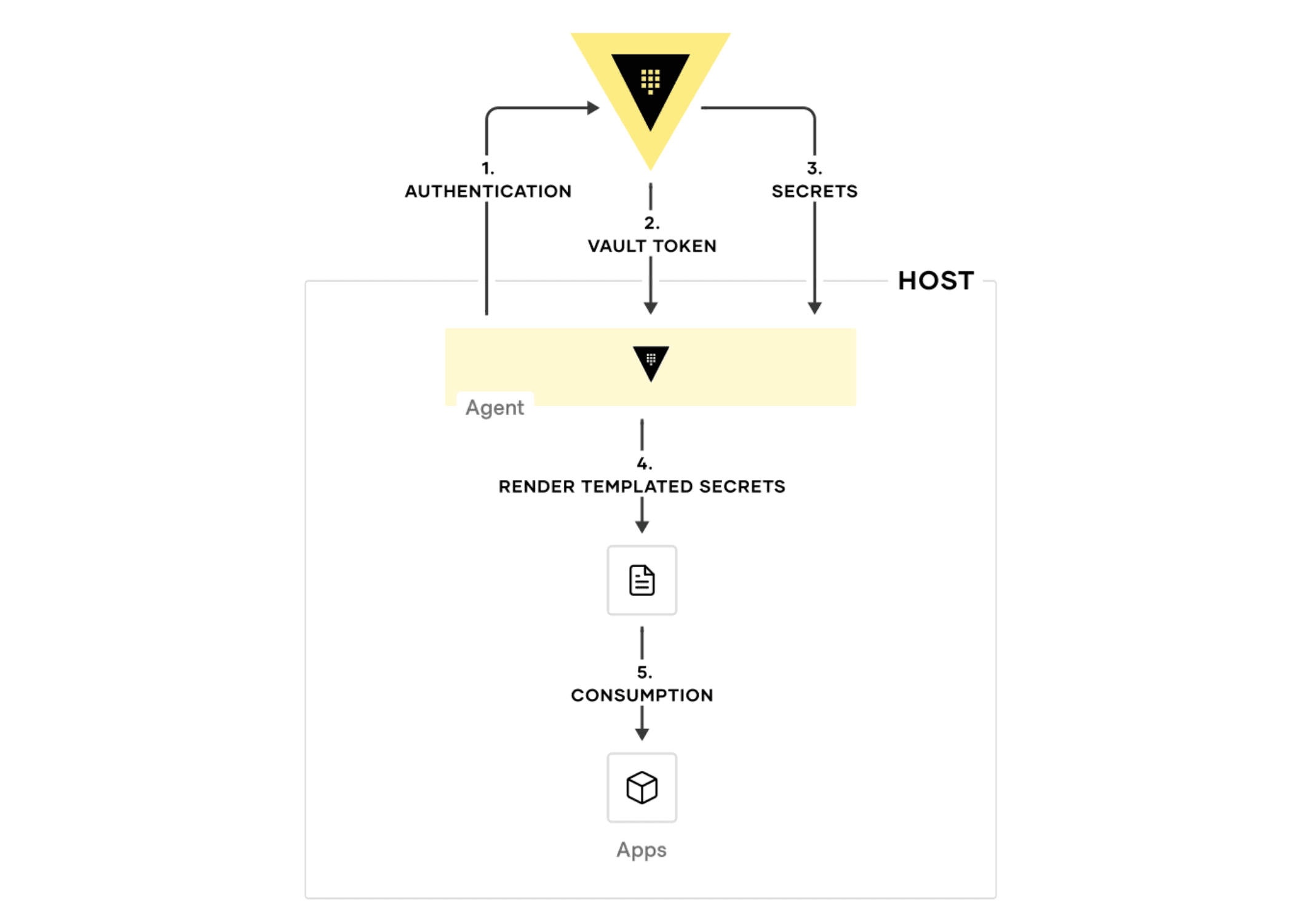
You can try creating your own Agent templating setup using this example configuration.
»Proxying and Caching
When Vault is controlling access to all of your secrets, it is very important to ensure that Vault’s performance scales as its deployment grows, so it can handle the corresponding load. The Vault Agent supports the ability to proxy and cache requests to Vault as well as responses from Vault. This helps reduce the number of requests sent to Vault servers at one time, reducing the peak load on Vault servers.
The diagram below shows how the Vault Agent manages proxying and caching in a token-request process:
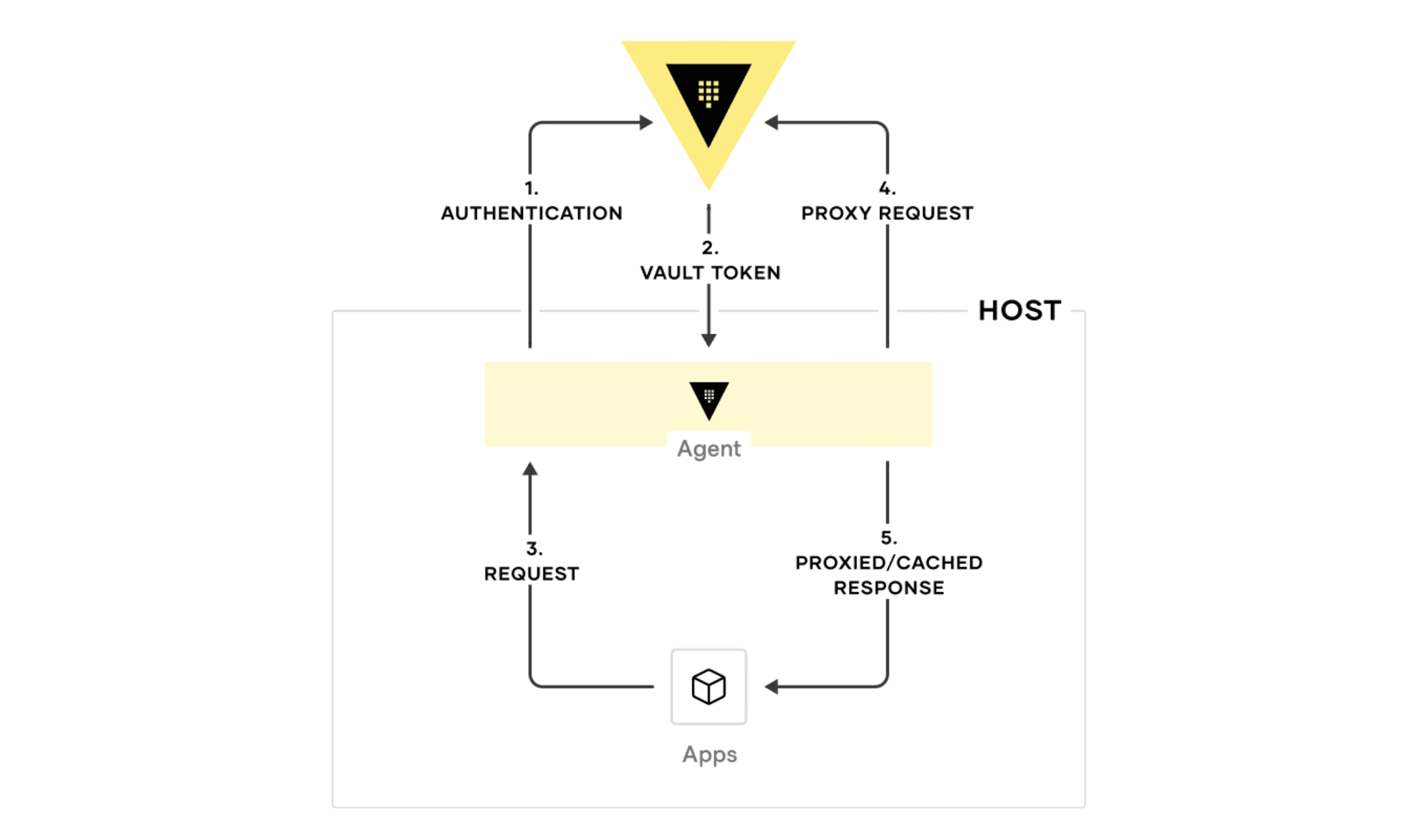
This feature can be enabled by specifying the cache and listener stanzas as shown in this example configuration.
»Persistent Caching for Kubernetes
A popular use case for Vault Agent deployment is using the agent sidecar injector in Kubernetes environments to manage authentication and secrets for application pods. After seeing the popularity of this use case, we added the ability for the caching layer to be temporarily persisted across init and sidecar containers in Kubernetes workflows.
When a pod is deployed, an agent init container can start up and perform tasks such as authentication and templating. Until the init container completes its tasks, these tokens and leases are temporarily persisted on a memory volume. When a long-running agent sidecar container starts up, the persistent caching feature restores these tokens and secrets, keeping their leases renewed so that applications can continue to consume them without service interruption.
This feature also eliminates duplicate fetches of tokens across the init and sidecar containers, further reducing the number of requests that hit the Vault server. You can see the persistent caching pattern illustrated below:
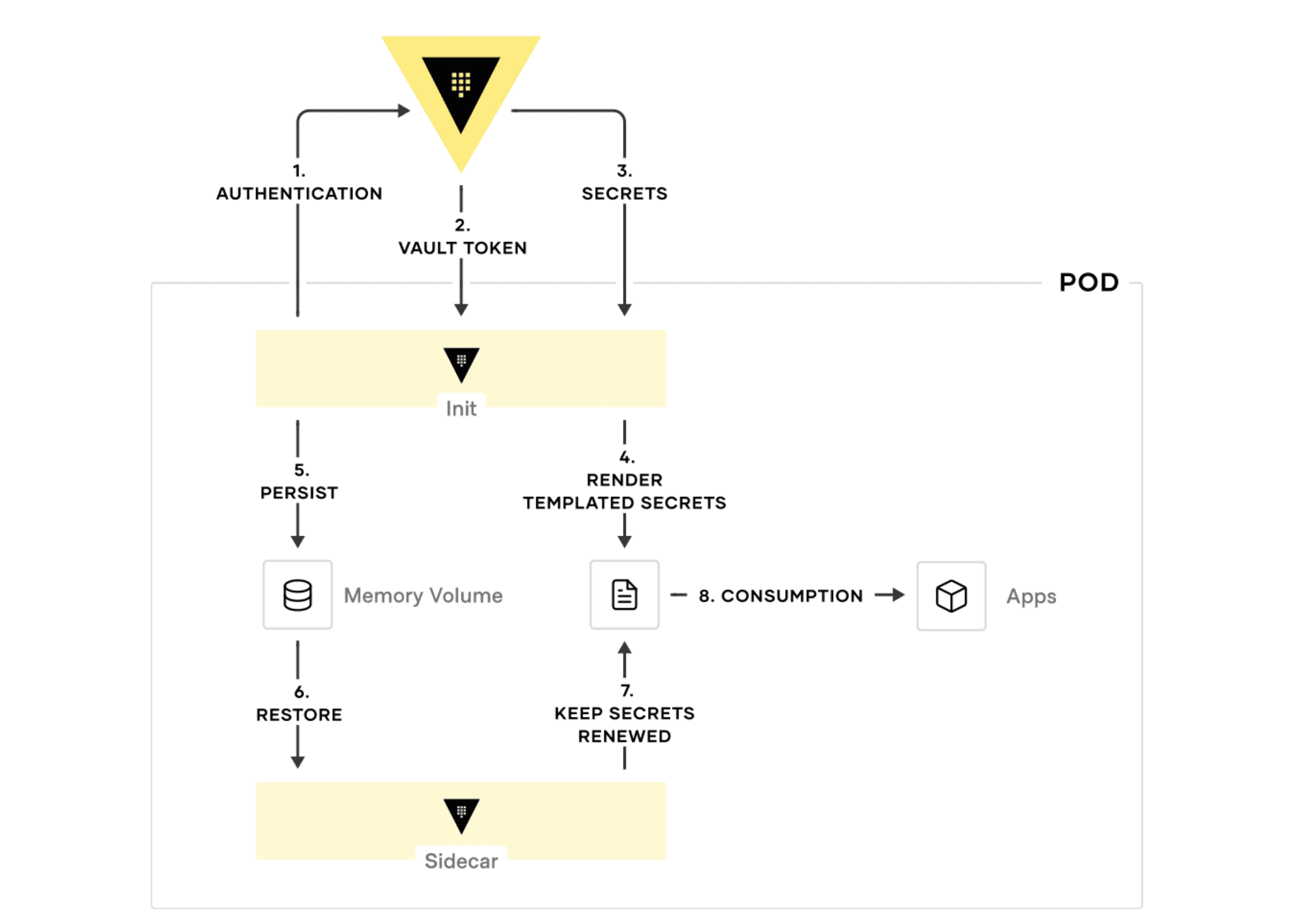
Persistent caching can be enabled by adding a persist stanza within the cache stanza as shown in this example configuration.
»The Vault Agent Advantage
The Vault Agent simplifies the zero trust adoption journey by reducing the effort and time needed by your application teams to integrate with Vault. Applications can easily integrate with the agent, which handles authentication into Vault along with the fetching, rendering, and lifecycle management of application secrets and the caching of these secrets to reduce the load on Vault.
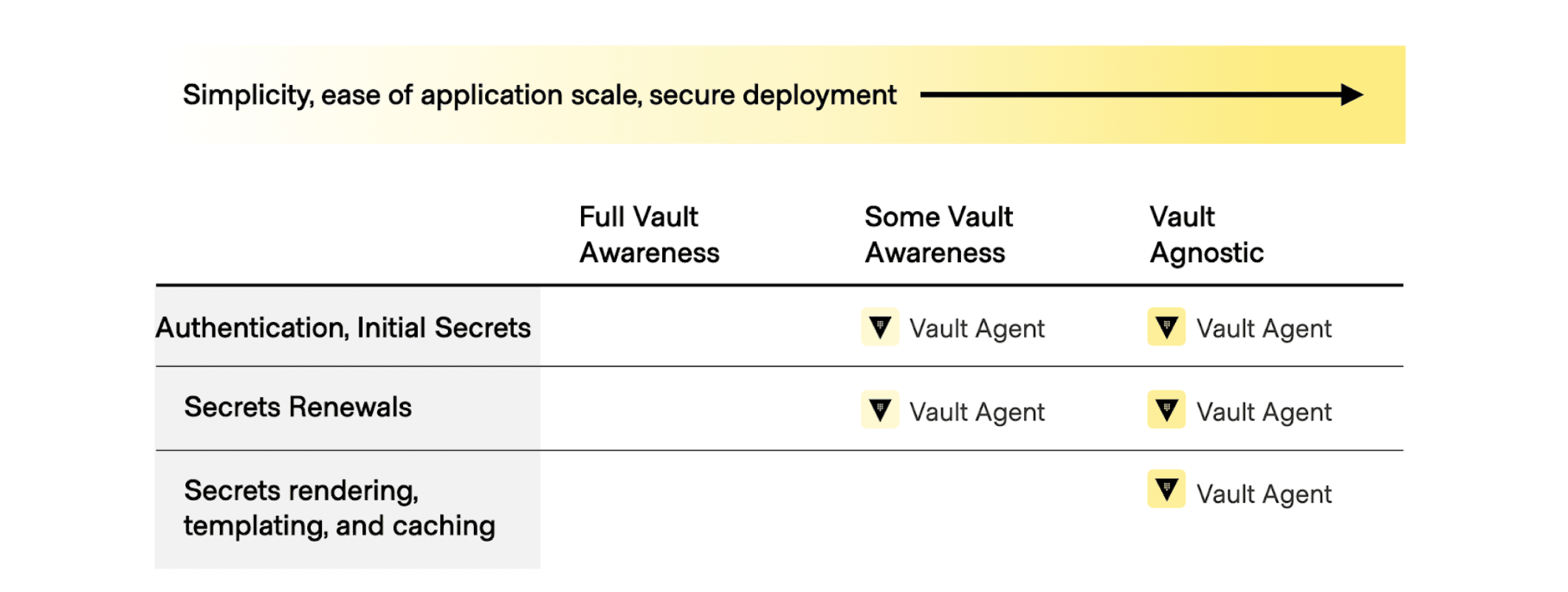
The diagram below shows that as tasks such as fetching the initial secrets, secrets renewal, and secrets rendering, templating, and caching become more Vault agnostic from the perspective of your application, they become easier to manage at scale:
»Vault Agent Learning Resources
The best way to learn more about the Vault Agent is to start using it. To get started with your exploration of the Vault Agent, check out our documentation and HashiCorp Learn guides, or request a demo.
You can also watch this video presentation on the benefits of leveraging the Vault Agent:
As always, we are interested in hearing about your experiences with Vault, so please share your feedback on GitHub so that we can continue to improve the Vault Agent to serve your needs better.






