Nomad, Consul & Vault at the Edge in eFishery
See the edge architecture of eFishery, an aquaculture IoT management startup that uses HashiCorp Nomad, Consul, and Vault.
First, here are some stats:


Learn the story of eFishery, an aquaculture startup that uses IoT devices to manage fisheries in Indonesia.
»Transcript
Hello, everyone. My name is Yahya. I'm an infrastructure and security lead at eFishery. A startup running aquaculture in Bengal, Indonesia. And I'm here to share how the HashiCorp stack especially with Nomad, Consul, and Vault is helping to deploy at the edge server in rural areas and to deliver data from edge devices via the cloud so fish farmers will have no problem at all controlling the cultivation.
»About eFishery
Beforehand, I will introduce you to eFishery. We are an aquaculture startup in Indonesia with the Feeder machine as our main product. It helps farmers by evenly spreading food around a pond like a raindrop to growing an aquaculture ecosystem. Our other business are here to help the farmer economy by finding the best price for them while we give cheap prices for our ecosystem customers. We build our solution for the aquaculture sector, meaning the fish farmer, stream farmer, and their supply chain. Also, while connecting with aquaculture, we can bring aquaculture as the primary source of animal protein in the world. Hence, feed the fish and feed the world.
Before we touch the technology part, I will share a story on how eFishery decided to make this machine. The problem and motivation comes from the pond fish farmer who has a problem with the fish cultivation. One of the main components of fish cultivation is feeding the fish. This is the longest space, and it's hard to maintain. Usually, the farmer constantly spreads the food around pond, control the temperature, checks up on the fish, etc. Now the problem from this cultivation test is usually the feeder fish don't spread evenly around the pond. This is causing some of the fish to under or over feed. The uneaten fish will become waste and contaminate the pond. This will cause fish to have a poor health, increase the dead fish, and the farmer will need to clean up the pond constantly.
For every pond, usually the farmer will waste around 25% of a bag full of feeder. It means the farmer will waste around bag full of feeder for every four pounds. This will make a farmer to buy more feeder fish, but if they buy it too early it will be waste. As for the conclusion, the farmer have a struggle with feeding the fish.
So I introduce you to this great machine we call "feeder". This machine has a three main components. The tank that will be filled with all the fish food, the green box with an antenna called "control box" or we call this the cobox, and also the thrower that will mix the feed evenly spread like rain drops. Now maybe you will ask why it has to be like a rain drop. We follow the farmer behavior to spread the food and their best way is by imitating the raindrop. With Feeder, the farmer can easily control the feeding automatically to control the quantity of feeding and scheduling. The best part is the farmer can monitor the cultivation control bay using an app. Now if you imagine the pond location, it is usually in a rural area far from a stable internet connection. And the very first version of our edge computing was the offline-first approach to get the device log and farmer cultivation, and here is how it worked.
»The Offline-First Approach
Every morning a farmer had a schedule to spread feed around the pond, and they need to make sure the water quality and health condition of fish is not under-fed or sick. Farmers will put food into Feeder, connect the phone to machine we call cobox through the wireless connection and set up the machine configuration for faster spreading, slower spreading, or by scheduling.
The data will be stored locally at cobox. The cobox will send the data log into farmer's cell phone every time the farmer has a connection with the cobox. The data will be stored locally with the farmer's cell phone. And everyday the farmer will connect to the internet within their house or come near the city where they have a connection to the internet. The data will be synced or distribute to our database. This offline-first approach was a big help for us and made a great impact in the past year. Now the problem is the data will be synced to our database within one to three days by the farmer. This means we need to improve our architecture by connecting the IoT (Internet of Things) to our cloud to get faster results.
First, I will show you this control box we call cobox. This machine is set to configure the set machine rotation and send the data log to the farmer's phone. This machine is actually built with an ESP32 controller supported with the Wi-Fi as our wireless access point to connect with the farmer. So this cobox has a big role in order to send the data within our cloud. You could see that it is easy to turn on the cobox. So most of our farmers come from the rural area where an internet connection might be impossible. So this is where we come to the topic of edge computing in our product.
»Edge Computing at eFishery
With edge computing, it is possible to get our data from a device that expected to be disconnected from our cloud. In this picture, you can see the edge device is where our IoT device is deployed. In order to solve the internet connectivity issue with the edge device, we need them to store the old edge device data and they will communicate with cloud to forward the data. Now if you imagine the big scale of our architecture solution, here is how it looks.

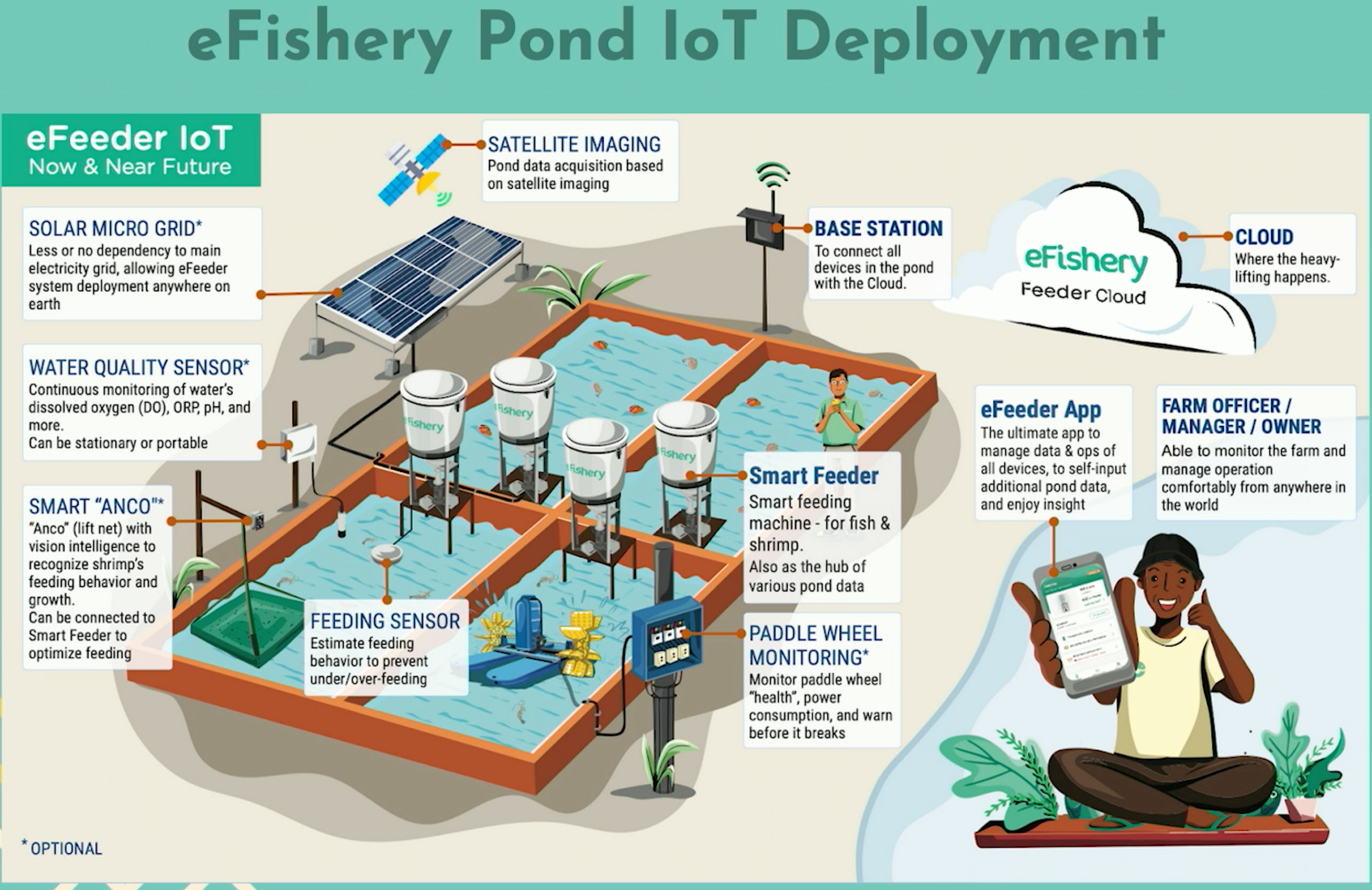
You can see this is how the farmer controls the pond and how it looks with our feeder deployed on the pond. We have a quality sensor to directly measure constituents of interest, such as chemicals like dissolved oxygen, ORP, pH concentration, solids in the water, and more. There is another device we call the smart lift net which has the intelligence to recognize stream feeding behavior and drought. We also have a feeding sensor attached to the Feeder machine. It is simply to prevent under or over feeding. All of this will be sent to the base station and connect to the cloud.
Now let's deep dive into more detail about the architecture. Here is how it works.

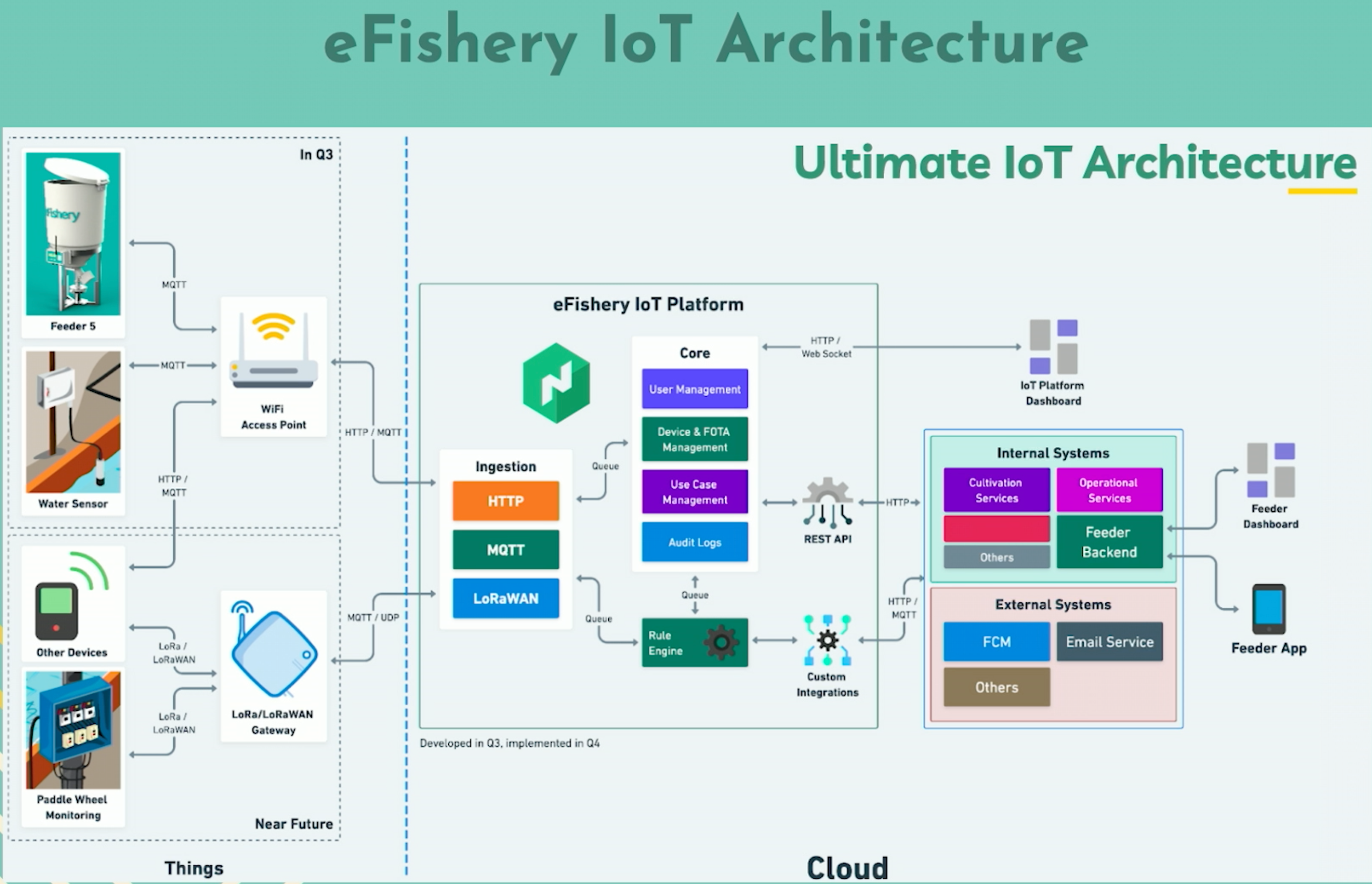
The edge computing has an unreliable internet connection and is always expected to be disconnected from the cloud. We have many devices that will gather the data logs from the sensors, then send it over the Wi-Fi and forward it to the server. In the future, we hope we can send our data with LoRa Mesh and LoRaWAN. The edge server will receive the data log from device and store into the MQTT broker or using the API server.
After that the device will check the connection to the internet and distribute the data. The edge server is using the Raspberry Pi 2 with the 900-megahertz quad core, ARM Cortex-A7 CPU with 1GB memory. The edge server will receive the data from the device and forward the data. This edge server will be installed on a HashiCorp Nomad agent and Consul agent and connect to the cloud and communicate with other private servers.
»The Role of Nomad
Now the role of the Nomad in the server is to deploy the needs of a device and easily control them without any need to visit the pond. Now if you imagine how this could happen. Whenever a farmer needs to deploy the Feeder machine, we also install the best station included with our edge device and edge server. The operational people will deploy the edge server and install the basic needs of the edge server like the Nomad engine and Consul agent.
After that, operational people will connect at the server with our private network. And they will tell us if the edge server is already installed. If the edge server is connected to our Nomad cluster, we will install the rest. So this means the role of Nomad and Consul in our IoT deployment is to deploy the edge device dependencies, control which device is still active sending data, and update the edge server services.
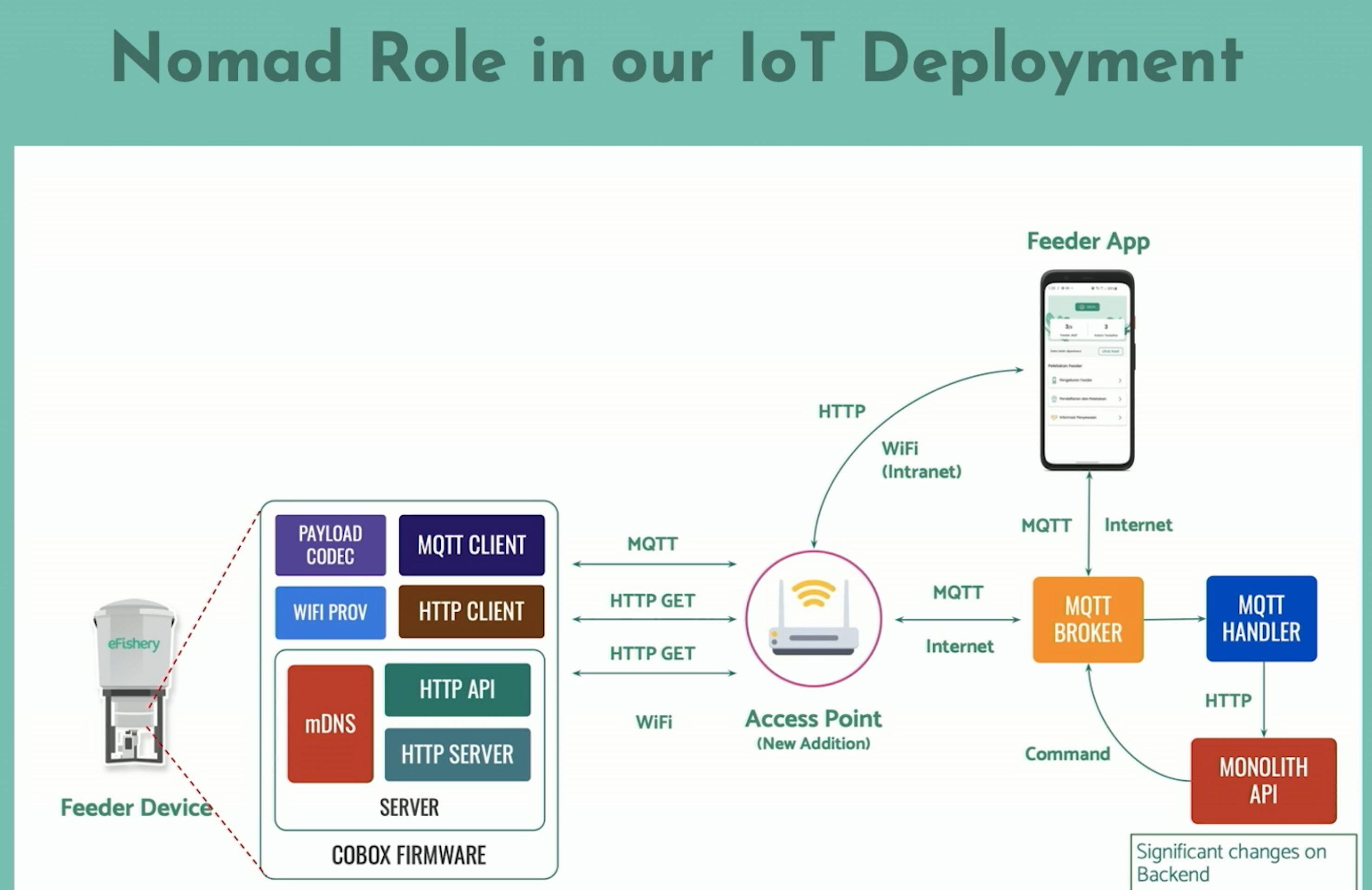
The point of Nomad is to control the deployment of our MQTT server in our consumer. We have a consumer we call PufferC. This service is meant to deploy the edge server and check the connectivity to our cloud. Every edge device log has a hundred-record rotation. And it will be much better if we can preserve the data. So we made this PufferC working offline first. So all data will be stored first locally in PufferC, and if they connect to the internet, it will send the data. So with this PufferC, we stored the edge device log locally whenever offline. After that it will sync and distribute the data when online.
And this is how it looks when one of our Raspberry Pi connects into our Nomad cluster. We are using the Raspberry Pi 2 connected to our cloud. You can see with the CPU usage, they always have a rigid connectivity. This is how our ATL script will deploy to our edge server. You can see we deploy this with the datacenter edge server and continue with constraints only to a server with no type of edge server. After that, we use distinct hosts to make sure the job doesn't run on the server that is already running the same job. And for task driver, we are only using the exec or executable. It's not a container because we need to optimize the memory usage. So we just need to install the broker and our offline first service.
Now let's think back to all that I explained. Memory usage is a finite in our research. The lower usage of memory, means lower costs. It will be much better if we can run our Nomad under ESP32, but that will be impossible right now. So let's talk about this memory usage. So far, Consul agent and Nomad engine only need 300MB of memory for the basic requirements. And after that we installed the basic needs for edge devices. We only reach 70% CPU usage and 800MB memory usage. So that's everything about how we managed to use Nomad and Consul as our IoT deployment.
»Why We Chose Nomad and Consul
Now let's talk about a more interesting topic regarding Nomad and Consul. Why did we use these in the first place? For a year, we had so many question from people about, "How did you choose Nomad?" If you guessed it was the edge computing, no, we didn't notice that edge computing would work with Nomad.
It was regarding the heated debate we had about container orchestration in building our SDLC. Everyone told us to use Kubernetes. Every engineer here had two-year's experience with Kubernetes.
Let's see the main problem with Kubernetes - memory. Kubernetes reserves 700MB or 9% memory for kubelet. Even for K3s or KubeEdge, the usage of the agent itself is more than 300MB. Also Kubernetes has a lot of components we need to understand while the Nomad agent is only 180MB and focuses only on container/workload orchestration.
Now let's talk about how we chose the HashiCorp stack. In order to choose the best tech stack, we needed to think about choosing the better investment for the company. We have a culture of maintainability. We believe we need to have a universal and sustainable technology. We call this the agnostic tech-stack approach where we didn't depend on some vendor in order to run the technology.
»eFishery and the HashiCorp Stack
In 2019, I just remember about watching the video where Armon Dadgar talks about the Tao of HashiCorp as the foundation that guides vision, roadmap, and product design of the HashiCorp products. We believe our technology approach has the same vision as the Tao of HashiCorp. In order to make sustainable tech, we need to use a simple modular and composable technology — like Nomad — it's actually pretty simple. It is only a container orchestration engine with architecture that focuses on that. And it's pretty sustainable that Nomad has a better failover feature and better memory usage.
Another piece of the Tao is to focus on the end goal and workflow rather than underlying technologies. And this actually defines the HashiCorp stack and leads to a fundamentally technology-agnostic view where technology is used as problem solving, not as another tool.
While we are using Nomad and Consul as edge computing. We also use HashiCorp Vault in the edge deployment configuration. We are focused on development experience and secret management so we're a little bit different when using Vault. Our focus is to store the deployment configuration and restrict the use of plain text. All an engineer needs to do is configure the secret variable and deployment configuration within Vault. You can see the first key: we have the CI/CD key as the deployment configuration, which includes the domain of the service data center location, container image, resource configuration, and so on. Second, we have an ENV key or application configuration file where developers store the needs of the application. You can see some values of the key but it hides the real value, and only the application can understand the original value, unless we have the metadata key to explain the function of the application.
We didn't use Vault because it is the only secret management platform, but because it has better experience and support for our universal needs in secrets. The best thing is that everyone can use Vault without a deep understanding of the tool. Statistically, right now we are running with the HashiCorp stack in more than 200 deployments a day, 80TB data transfer a month, more than 500 Nomad jobs, and 900 running containers. Lastly, with 100 servers and edge servers, the total specs of which are 1.2TB and 700GHz. The spec is kind of small because sometimes we are running with the edge server. Maybe a lot of people will explain the advantage and disadvantage with the HashiCorp Stack.
Next, we will explain the benefit of investment with HashiCorp stack. First, we have easy deployment because HashiCorp stack is modular. Second, it is a faster mean time to repair or MTTR. Nomad has a lot of failover features like a blue/green deployment, canary deployment, versioning, and also rollback. This is the most helpful feature with the Nomad.
Last, we could just simply install the Nomad agent and Consul agent everywhere. This is why we are actually working with the edge computing. One time we used a personal computer to solve a resource problem and it only took 10 minutes to spawn. Everyone knows that in Kubernetes has Helm and it's pretty helpful. In Nomad, has Nomad pack. And in Kubernetes, sometimes CSI plugins have issues and sometimes the documentation is kind hard to understand.
All right. Everything I shared is only the tip of the iceberg for our edge computing, and we would love to share this more within the next year. That's it for me. Thank you very much.


