

Today we are proud to announce our first publication by HashiCorp Research, titled "Lifeguard: SWIM-ing with Situational Awareness". The paper details a number of novel improvements we have introduced to Serf, Consul, and Nomad to make their underlying gossip protocol more robust. Collectively called Lifeguard, these extensions reduce by 50x the false positives produced by the failure detector and allow us to detect true failures faster.
Distributed systems such as BitTorrent, Apache Cassandra, Microsoft Orleans, and HashiCorp Consul commonly use Gossip protocols. They are typically embedded to provide features such as cluster membership (who is in the cluster), failure detection (which members are alive), and event broadcast. Their peer to peer nature often makes them much more scalable and reliable than centralized approaches to solving the same problem. However, the reduced amount of communication makes them sensitive to slow processing of their messages.
Many of our tools leverage work from the academic community, and with HashiCorp Research we hope to contribute back. Our focus is on novel work and whitepapers about the algorithms and system designs we are using in practice. Lifeguard is our first published work, and our users operating the tools in production environments drive the focus of these improvements.
Read on to learn more about Lifeguard.
»Lifeguard
HashiCorp tools embed our memberlist library, which implements the SWIM (Scalable Weakly-Consistent Infection-style Membership) Protocol. The original protocol provides cluster membership and failure detection, which is extended by Serf to provide an event broadcast system. Serf is embedded as a library in both Consul and Nomad and also a standalone tool. Collectively, these systems run on millions of machines, with individual data centers running over 10K+ participants in the gossip protocol.
Our experience in supporting these systems led us to discover a number of shortcomings in the original protocol. Particularly, slow message processing caused by CPU exhaustion, network delay, or loss, could lead to incorrectly declaring members as faulty. This can have costly effects such as unnecessarily diverting networking traffic from healthy members and triggering unnecessary rebalancing of data replicas.
The inception of Lifeguard was in an attempt to reduce false positives and avoid sensitivity to conditions which are relatively common in data centers. We build on the work of the original SWIM authors and add three new extensions which collectively make up Lifeguard. We call these extensions Self-Awareness, Dogpile, and Buddy System. The details below discuss each of these extensions.
»Self-Awareness
The first extension is called Self-Awareness because we attempt to combine multiple sources of information into an aggregate estimate of the local member's health, in effect giving the member "self awareness" about its own state. The gossip protocol depends on the cooperation of all members to efficiently determine which members are healthy or unhealthy. The original SWIM paper assumes a crash-stop model, meaning a member is either running or failed, with no gray in between. In reality, the gray area between running and failed is significant, and members can be running but degraded (CPU exhausted for example). These degraded nodes may inadvertently affect the stability of other healthy members because of the cooperative nature of gossip.
Self-Awareness allows a member to determine if it is currently degraded and to minimize the impact on the rest of the cluster. Each member maintains a "Node Self Awareness" counter which is updated by various interactions with other members. As the counter increases, the member becomes more conservative about declaring other nodes unhealthy. This feedback loop allows unhealthy members to quickly minimize their impact to the rest of the cluster until conditions improve, and then return to normal behavior once their interactions with other members indicate that they have recovered.
»Dogpile
Dogpile is the second extension because multiple members will "dogpile" on declaring another member as failed. In the original SWIM paper, a single member can suspect another member as failed, and the suspected member can refute within a fixed time frame. This mechanism is robust when all members are healthy, but if a node is experiencing CPU exhaustion it may not process messages in a timely manner and can mark other, healthy members as failed.
Dogpile replaces the fixed time frame to refute a failure with a dynamic one and logarithmically reduces as independent members confirm a member is failed. When a degraded member harbors a suspicion, it will receive no confirmations and has much more time to process a refutation because its timer will not have been reduced. If a member truly has failed, it will be quickly confirmed by other members and will not increase the time it takes for healthy members to mark that member as failed.
»Buddy System
Buddy System is the final extension because members will notify suspected peers so they can refute their failure more quickly. There are several types of communication between members, including health checking and status broadcast. Typically when a member joins the cluster, or is suspected as failed, or leaves the cluster, it will broadcast a message which is eventually received by all other members. The broadcasting sequence includes sending a message to a few peers, who then forward on to a few other peers, etcetera until all members have received the message.
The broadcast mechanism is efficient but can take a few "rounds" of gossiping to notify all members. The health checking mechanism is more direct, as two members will communicate directly to check for liveness. The Buddy System overloads this mechanism to notify a member that it is suspected of failure directly, instead of waiting for the broadcast mechanism to reach that member. This allows a member to refute a failure right away because it will learn about its status in the cluster when another member probes it.
»Results
The paper gives a detailed explanation of each of the Lifeguard extensions, and analyzes their individual and combined impact. The graph below provides a high-level snapshot of the effects of Lifeguard:
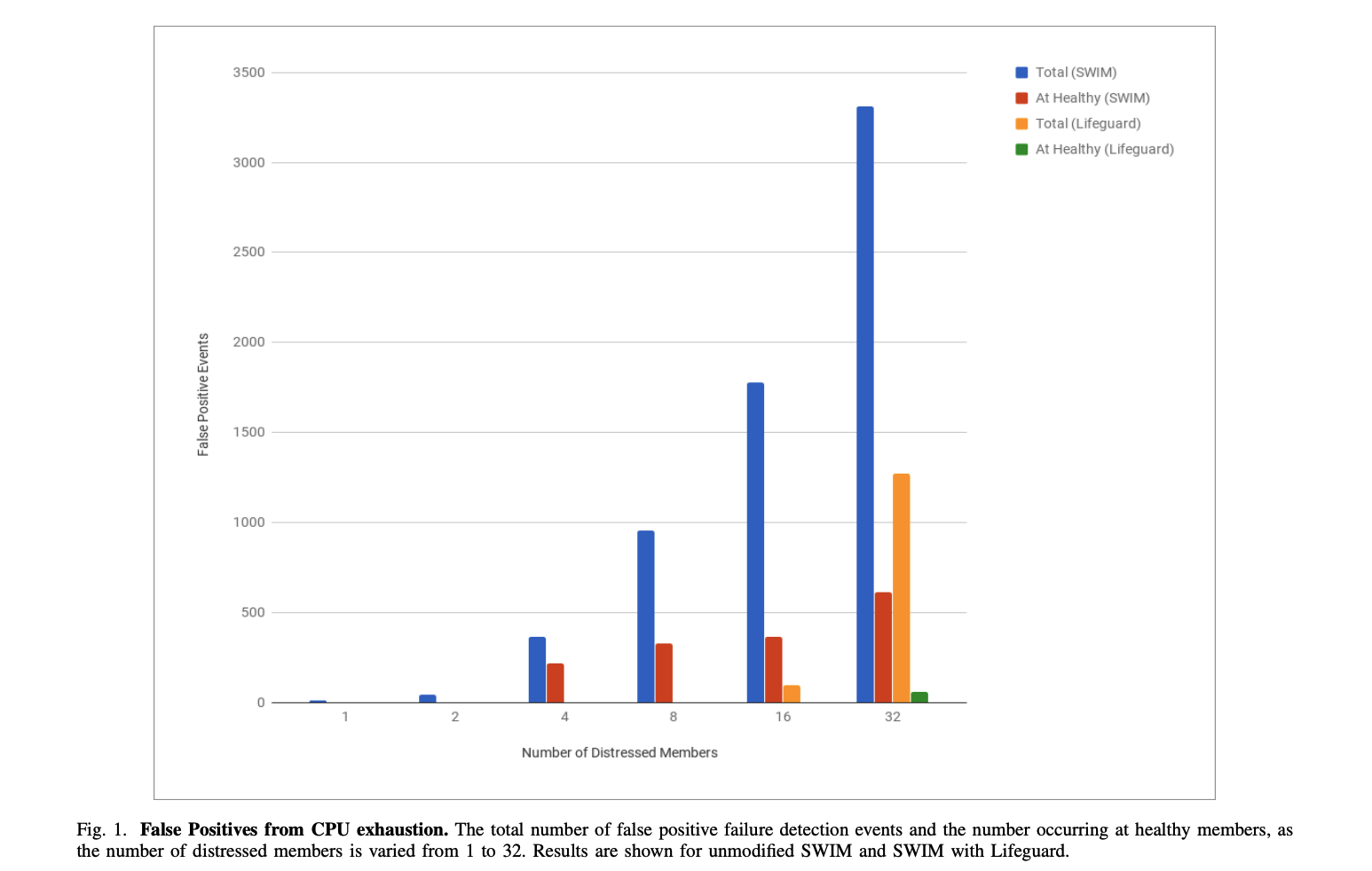
Relative to the baseline, which is the implementation prior to Lifeguard, we reduce the rate of false positives by more than 50x. This also does not impact how long it takes to detect a member as having failed. One of the parameters or "knobs" in Lifeguard is alpha, which lets us control how much time a member has to refute failure. By tuning this knob down, we can detect failure more quickly but at the cost of increasing false positives. Prior to Lifeguard, this would have caused an unacceptable number of false positives, but with Lifeguard and alpha=2 we can detect failures in almost half the time with 7x fewer false positives.
We've changed the defaults in memberlist to alpha=4 so that failures are now detected 20% faster with a 20x reduction in false positives. End users will perceive a faster and more robust system as a result of Lifeguard. Many of these improvements were incorporated in September 2016, and have been running in production at scale for several months. For those interested in the details, the full paper is available now on Arxiv. A major thank you to our users who helped test and provide feedback, to Armon Dadgar for advising, and James Phillips on Consul.
At HashiCorp, we believe strongly in the value of research. Many of our tools leverage academic works to improve their performance, scalability, or security. Using research in this way makes the state of the art accessible to end users. Lifeguard is our way of advancing the state of the art and giving back to the community. As we continue to work with users and customers to understand their challenges it helps inform our research and helps us focus on solving the frontier of problems. We look forward to sharing what we are working on next in the future.





