

Choosing the right data protection solution can be complicated. The stakes of maintaining proper data security can be high, and the process of doing so is technical and complex by nature. This problem is only exacerbated by the lack of standardized and transparent definitions for all the terminology used in the data protection space. Terms like “masking”, “transformation”, and “encryption” are employed frequently and inconsistently across vendors. This leaves consumers in the dark about what they’re purchasing, if it meets their needs, and how it measures up to competitors. We on the HashiCorp Vault team do not believe it needs to be this way.
The reason that this confusion exists is simple: there is no single perfect data protection method. Cryptographic rigor and convenience are inherently at odds in any solution, so what matters most is that the consumer can identify the tradeoffs that best align with their context. Vault’s various data protection capabilities are designed to satisfy a full range of security and usability needs. Here we will help you identify which components of our offerings best align with your business security needs.
»A Word on Encryption
All but one of the Vault data protection methods we are discussing today are different applications of encryption. At its core, encryption is the process of converting some typically sensitive information, referred to as the plaintext, into a second value, known as the ciphertext, in a way that obscures the relationship between the two. The particular mathematical conversion process chosen is known as the encryption algorithm or cipher. The cipher requires one other variable value, known as the key, as an input to transform the plaintext into the ciphertext and vice versa. Each of these encryption algorithms possesses different properties of convenience and security that make them better suited for particular circumstances.
»Data Masking
The easiest method of data protection to implement that Vault offers is Data Masking. It is part of the Transform secrets engine, and it is the only method that does not utilize a form of encryption. Data Masking works by replacing all of the characters in a provided plaintext with a user-specified character:
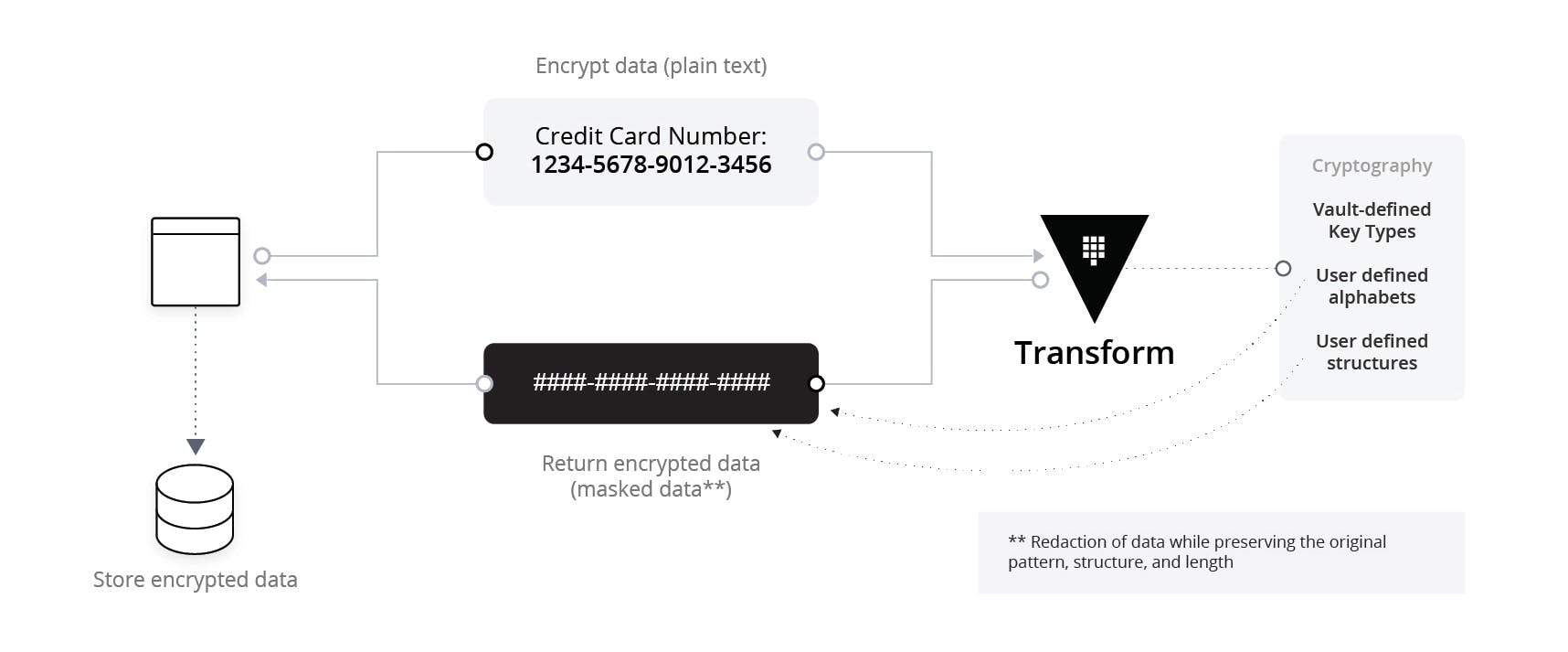
Data Masking represents an extreme favoring of security in the security vs. convenience dichotomy. Data masking is irreversible; once an input has been masked, not even Vault can use the output to retrieve the plaintext. The format and length have been preserved, but the identity of the original value is deleted. While this is maximally secure, it fails to satisfy any situation where reversibility is essential.
Data Masking is ideal for two families of use cases that are defined by when data masking is invoked.
»Static Data Masking
Static data masking describes the situation where data is masked at rest, and is often utilized in application development to create realistic data copies for testing. An entire production database can first be copied and then masked, redacting all sensitive data with identically lengthed substitutes. Individual developers can then clone this masked database to use in their testing infrastructure to mimic the testing behavior of their production database.
»Dynamic Data Masking
Dynamic data masking describes the situation where data is masked in transit. Rather than masking the entire database of sensitive information, masking occurs on a transaction basis. As data consumers perform individual read operations, Vault functions as an intermediary, masking the data as it leaves the data store and before it reaches the end consumer. Dynamic data masking tends to be slightly more complex to configure, because there are considerations with regard to what data and which users need to be masked. However, it does save on storage and front-loaded processing time to mask information per-request.
Overall, data masking is the correct solution if you are looking for irreversible but easy-to-use redaction. For more information, see the documentation, API spec, and interactive tutorial.
»Traditional Encryption
While data masking is useful for situations that require a one-way conversion, many data protection use cases require the ability to restore ciphertext to its original plaintext. The remainder of the data protection methods discussed in this post will all be forms of encryption and all satisfy the need for reversibility. This also means that in addition to a plaintext and ciphertext, these methods will have to be mindful of managing an encryption key of some kind.
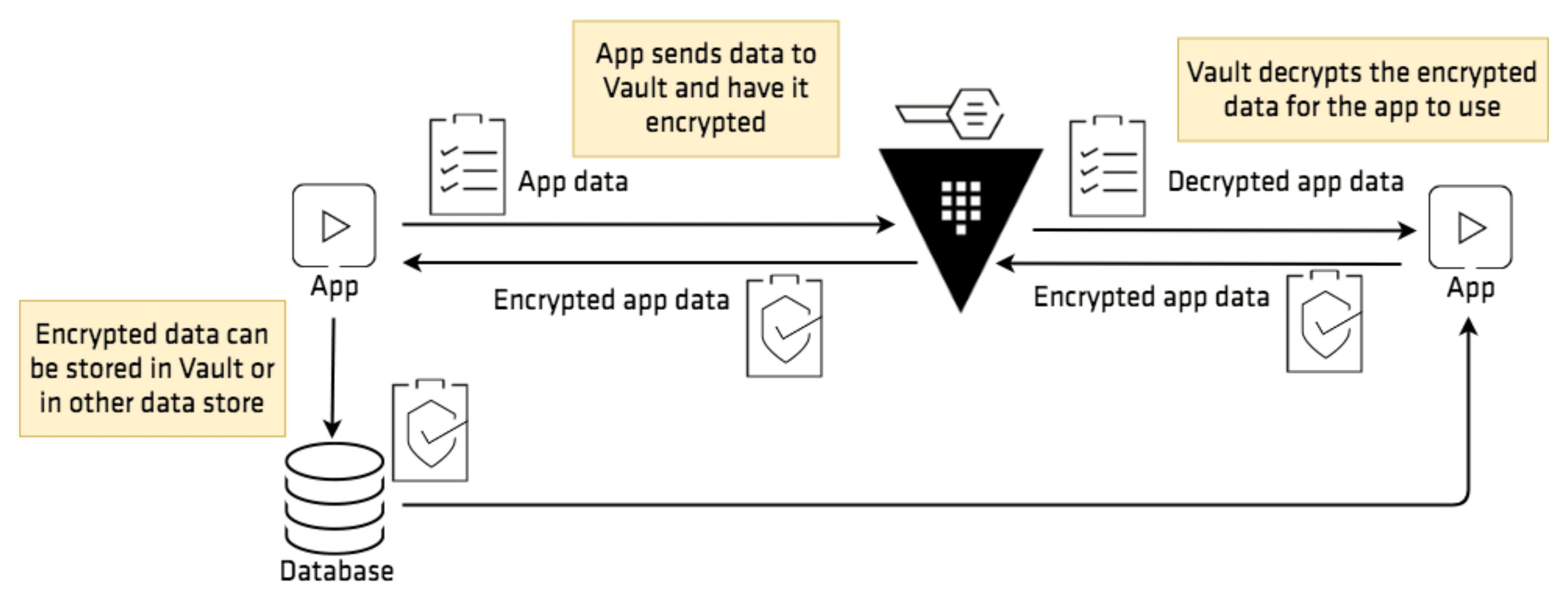
Vault’s open source Transit secrets engine provides traditional encryption. It takes in a stream of bits, applies one of the Transit engine’s encryption algorithms to it, and either encrypts or decrypts it using an encryption key. Vault keeps the encryption key safe within its cryptographic barrier and provides a number of capabilities for versioning and rotating the encryption key. It also supports a number of customizations, including convergent encryption, which is the property of having a given plaintext and key always produce the same ciphertext.
Transit does not store the data that it decrypts by default. While it may be configured to store the ciphertexts in an operator-specified data store, it may also be invoked on data in transit. This characteristic is what leads Transit to be referred to as Encryption as a Service.
The Transit secrets engine is useful for situations where the security of the data and the irrelevance of the input type are both the focus. As long as the plaintext can be represented as a base64 encoded bit stream, whether it be as simple as a string or as complex as an entire file, it can be securely encrypted by transit. The encrypted ciphertext will also be a variable-length base64 encoded bit stream, so the consumer of the ciphertext needs to be accommodating of this payload format.
Transit ultimately allows applications developers to leverage secure encryption while the configuration overhead is managed by the Vault operators. It has found use in industries ranging from consumer goods to financial services, and has been used to satisfy compliance regulations like the California Consumer Privacy Act (CCPA). For more information, see the documentation, full API and interactive tutorial.
»Format-Preserving Encryption
While the Transit engine satisfies a large number of encryption use cases, there are situations where the end user is unsatisfied with the ciphertext being formatted as a variable length bitstring. Often Vault’s encryption is used to protect data that exists within structured data stores, and therefore must adhere to conventions like the column lengths and types of a database table. This is particularly useful for legacy applications that possess a large amount of data, and for whom changing their schema to meet the bitstring encryption output is not possible. They require that Vault’s encryption instead adapts to accommodate their data structure.
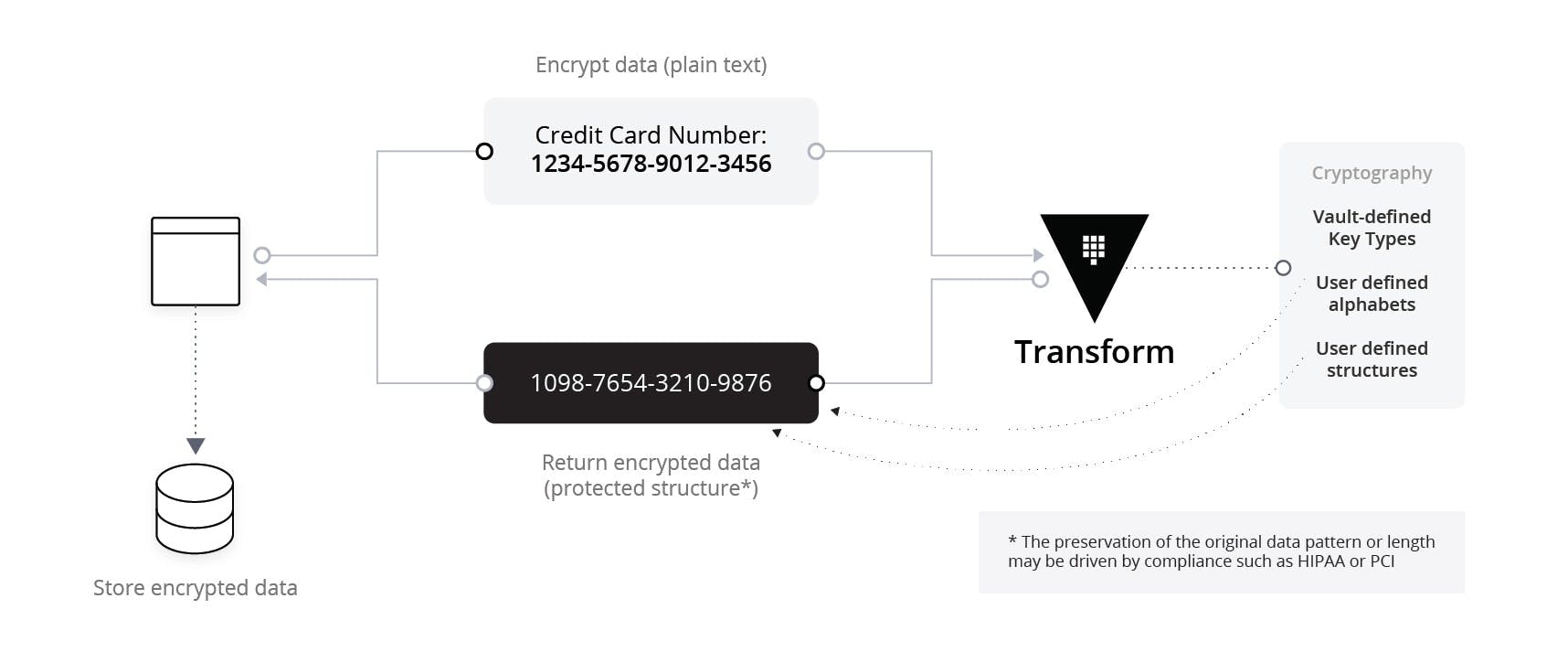
The solution to this problem is the format preserving encryption (FPE) functionality of the Vault Enterprise Transform secrets engine. Using the NIST-approved FF3-1 encryption algorithm, FPE allows the user to exert control over the length and content of their ciphertexts. This is accomplished by having the user provide a regular expression and character set for the ciphertext to adhere to.
The security and flexibility of FPE comes at the cost of relatively particular configuration needs. There are requirements that must be followed with regards to the alphabet size and plaintext input length in order to guarantee the cryptographic integrity of the FF3-1 algorithm. More information on that can be found here.
Furthermore, FPE requires an additional piece of information alongside the plaintext and the key. It utilizes another value, called a tweak, to supplement the security of the plaintext. There are a number of best practices we recommend for dealing with tweak values that can be referenced here.
FPE is commonly employed in situations where the need for specifically formatted data intersects the need for security compliance. Personal Identifiable Information (PII), such as social security numbers or phone numbers, is securable with FPE to meet standards such as the Health Insurance Portability Act (HIPAA) or the General Data Protection Regulation (GDPR).
It is especially useful for helping legacy applications with large amounts of data that needs to be updated, because it satisfies these regulatory requirements while still meeting their persistent data schema. A hospitality vendor that handles customer phone numbers, for example, may use FPE to replace the numbers with encrypted versions that still satisfy a #-###-###-#### data format.
For more information on FPE, see the Transform engine docs, API spec and interactive tutorial.
»Tokenization
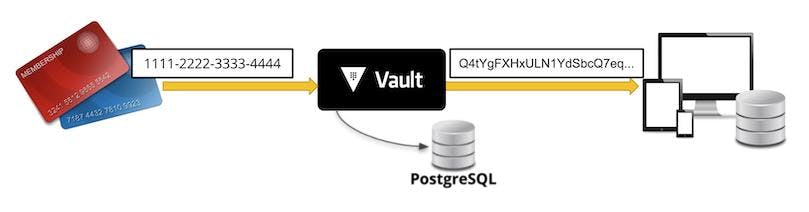
While Vault’s encryption methods are reliant on externally validated secure algorithms, there is still regulatory skepticism when it comes to any encrypted data. Standards such as the PCI-DSS, which is responsible for managing how businesses handle payment card data, require that a number of criteria are satisfied when handling payment information, even if it is encrypted.
The last of Vault’s data protection methods, tokenization, allows the user to avoid a number of these requirements by providing the user with a token that replaces their data instead of encrypting it. That token is generated randomly, and the plaintext and metadata that the token represents are encrypted and stored along with an expiration time. These are mapped to the plaintext in a secure database that the Vault operator may specify. While Vault is utilizing encryption internally to safeguard the tokenization value and metadata, the token itself is not a piece of encrypted data.
»Vaulted Tokenization
There are two schools of tokenization solutions that are often discussed. Implementations that possess external token mapping tables are characterized as (no pun intended) vaulted tokenization. This external table is central to having the tokens be considered “replacements” of the original data, rather than encrypted versions of the data.
»Vaultless Tokenization
The alternative to this is vaultless tokenization, which substitutes an external mapping table with a series of internal tables that are utilized to create the token value. Vaultless tokenization is often difficult to analyze because its implementations are inconsistent and proprietary.
However, the important conclusion to draw is that the token it produces is still capable of being used to retrieve plaintext if the tokenization service’s state is compromised. Vault’s external tokenization database, meanwhile, still protects the token in this scenario. Therefore, we recommend using either Vault’s formatless Transit or format-preserving encryption Transform options to satisfy the same business case as vaultless tokenization.
Tokens being considered replacements exonerates them from a number of compliance regulations, because they do not possess any inherent relationship to the original plaintext. They may only be used to retrieve the plaintext if the ciphertext holder also possesses proper access permissions to Vault, the encryption key, and the token mapping database. This makes tokenization ideal for use in applications where compliance-sensitive information is being conveyed and consumed broadly, particularly in the healthcare and financial sectors. For more information, refer to the tokenization documentation, API documentation or interactive tutorial.
»Making a Choice
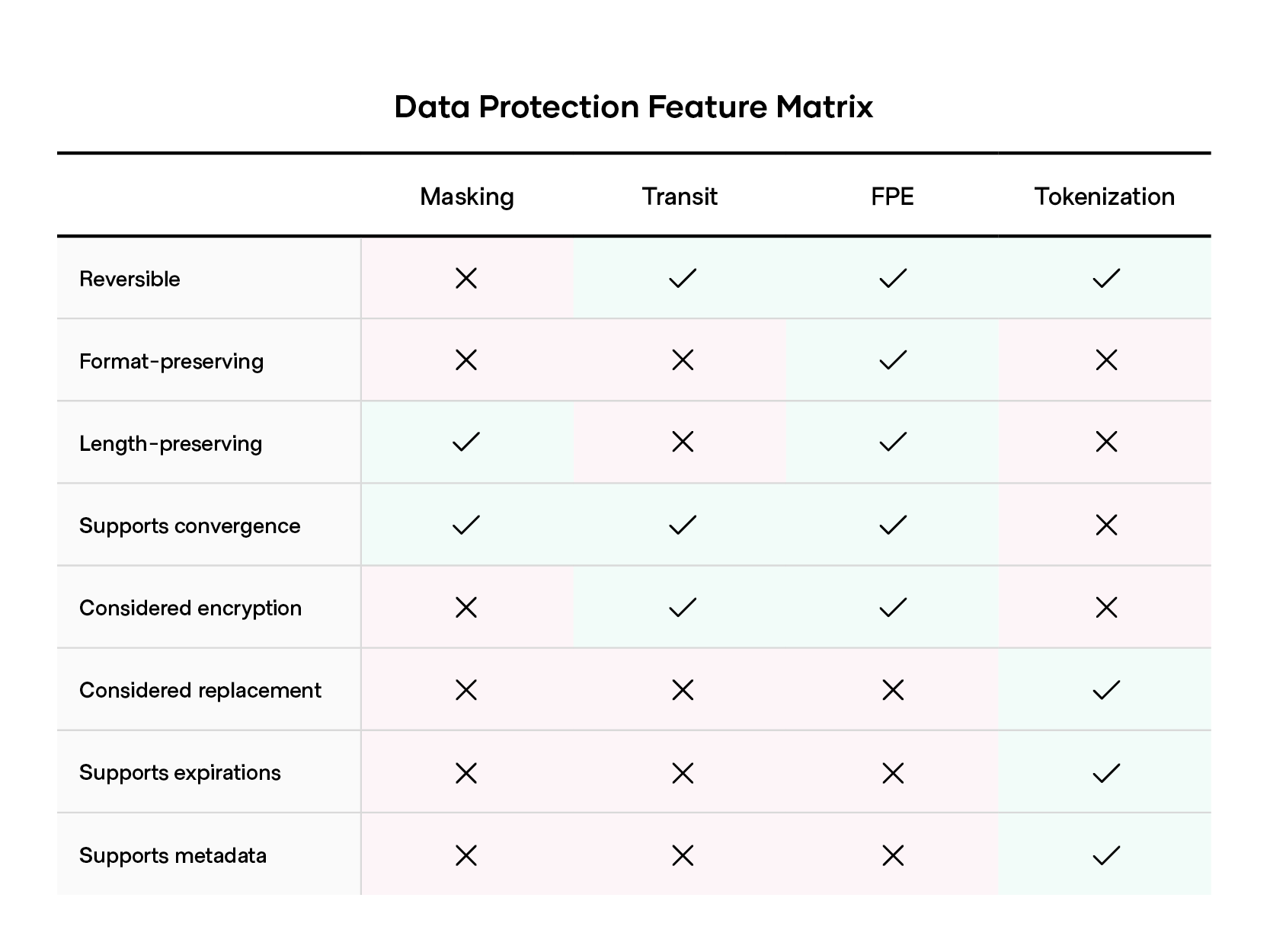
With a working understanding of these data protection methods now under your belt, picking the right tool for your use case involves asking questions about which attributes of data security you need:
Does my secured data need to be reversible?
Does my secured data need its format preserved?
Does my secured data need to be encrypted, or replaced?
The answers to these inquiries should narrow down the right data protection method for your needs. We have compiled a feature matrix to help you in this pursuit:
Once you’ve chosen your method, you may then utilize the full suite of platform capabilities in Vault Enterprise to further increase its usability. Your data protection workflow can be replicated and made highly available across different geolocations. It can also be made highly performant by taking advantage of standby nodes. It can even be divided into different namespaces for controlled multi-tenancy, and tightly access controlled with both ACL and Sentinel policies (policy as code).
If you have further questions on either data protection or the wider capabilities of Vault, check out our learn guides or request a demo.









