

At first glance, it seems clear that the cloud era has fundamentally changed the way we think about networking. We’re now operating outside defined perimeters, and networks can span multiple datacenters or clouds. But has networking really changed all that much from the days when everything lived in on-premises datacenters? After all, it’s still all about establishing consistent connectivity and enforcing security policies. So why does everything seem so different and complicated when it comes to the cloud?
To better understand the evolution to modern networking, it’s important to step back and identify the core workflows that have defined those changes, including:
Discovering services
Securing networks
Automating networking tasks
Controlling access
This blog post will walk through each of these workflows and discuss how they are combined to achieve a modern service-based networking solution.
»Service Discovery
It’s fair to say that application or service identity isn’t really a new concept. Networking professionals have always wanted to be aware of the apps and services running on a given network, where they’re located and whether they’re reachable.
What’s new is the dramatic increase in the frequency of changes made to those environments. The push toward continuous delivery models and microservices created a bottleneck in the form of manual tracking. Using spreadsheets or configuration management database (CMDB) tools to track IP addresses doesn’t really scale to cloud environments, so what were network operators supposed to do?
Enter the concept of service discovery. Service discovery is just automating the process of identifying what is running on a network, knowing where it’s located, and if it’s reachable in real time.
The need for this type of automation led to the creation of service discovery tools like HashiCorp Consul. When Consul was first introduced in 2014, its core function was to be a dynamic service registry — essentially a catalog for tracking applications. With this kind of registry, users could package automation scripts along with application deployments to automatically register applications in these catalogs, creating a single source of truth for application information.
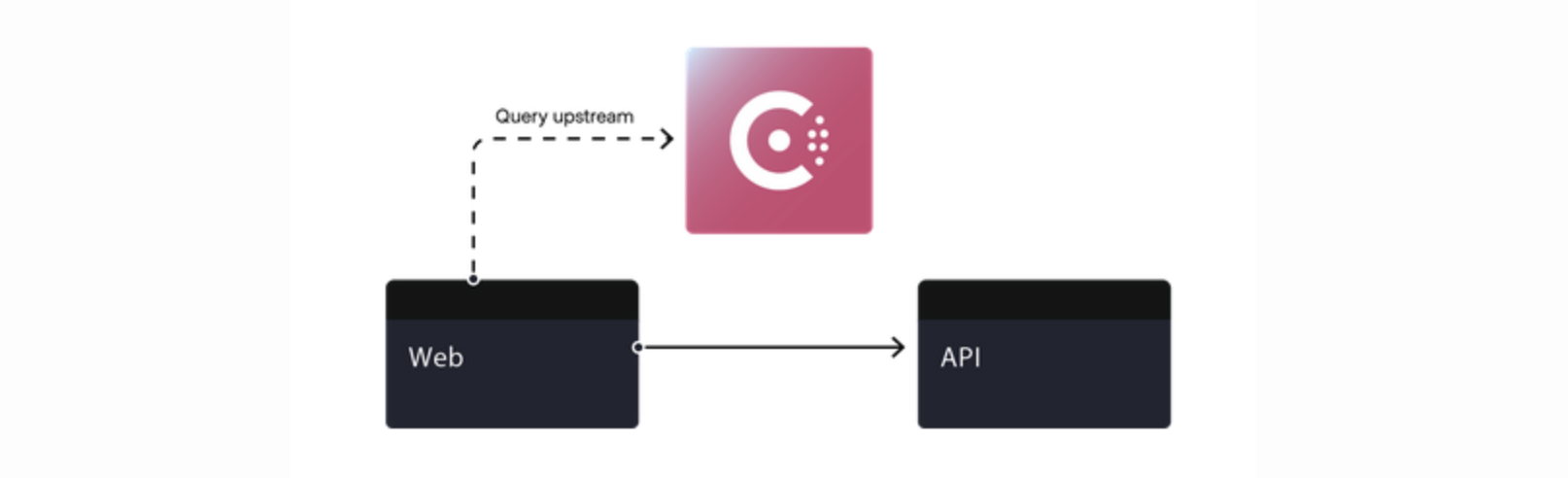
As application delivery evolved, orchestrators such as Kubernetes, Mesos and Docker Swarm integrated discovery functionality to reduce the need for those manual scripts. And while that’s great, what does it mean for the evolution of networking? A lot, actually.
Networking still needs to be based on service identity because that's how orchestrators track things, but the shift away from static, IP-based networking toward a service-based networking solution that these service discovery features provided was perhaps the most impactful change to networking, making application identity the basis for networking policies.
»The Impact on Security
Networking’s transition to a service-identity-based networking requirement also has cascading effects on other workflows. The first, and arguably the most important, is on security. While service discovery may solve for tracking changes more dynamically, it doesn’t help you apply consistent security policies to those applications.
As mentioned earlier, enforcing security and access to sensitive data is a core networking requirement. The reason we employ firewalls and load balancers is to help ensure that only the correct services are granted access to the network. And that approach works fine if you’re relying on IP addresses to track what’s running on the network. But what do we do now that we’re using service identity instead?
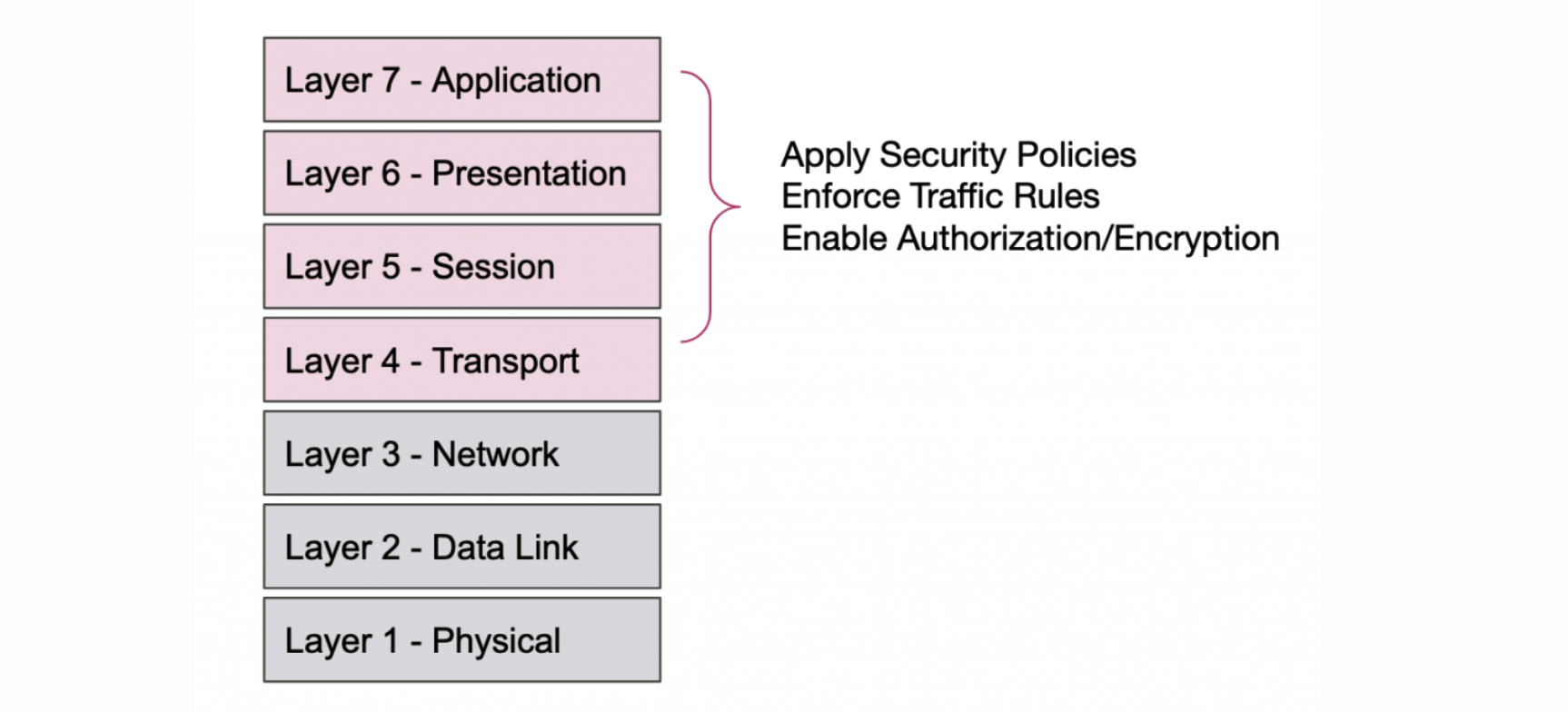
The short answer? Create security policies based on service identity instead of IP addresses. If you know the identity of the applications, shouldn’t you be able to create enforcement mechanisms around those identities? Unfortunately, traditional network security policies don’t really support that pattern. That approach forces development teams to rely on ticket-based systems and creates bottlenecks and frustration for both operators and developers. Fortunately, there are two ways to address this challenge: eliminating manual tasks for operators and moving security policies from Layer 3 to Layer 7.
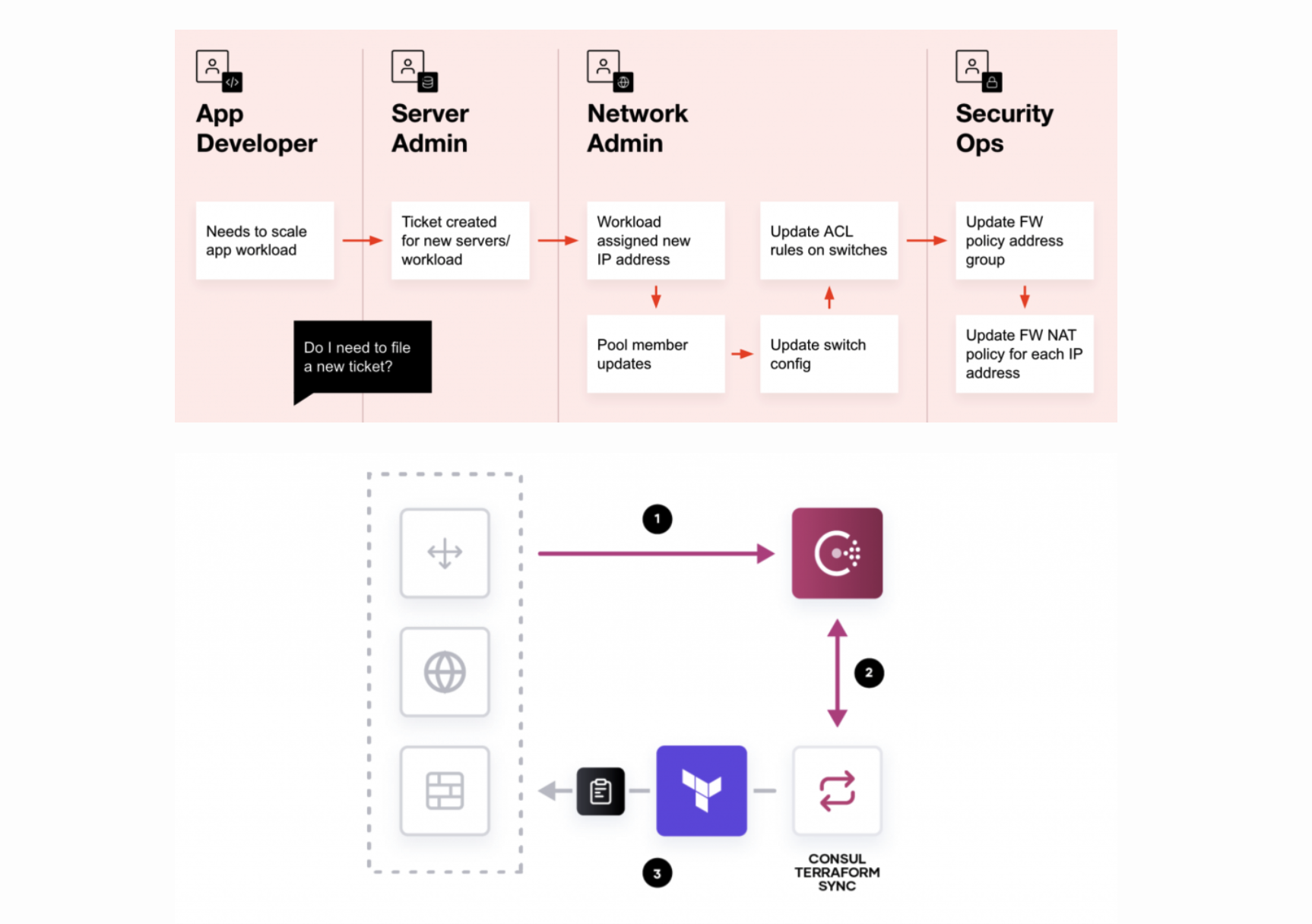
»Eliminating Ticket-Based Bottlenecks
Let’s start with eliminating manual tasks. To understand how this works, it’s helpful to look at another modernized workflow: infrastructure provisioning. Tools like HashiCorp Terraform were built to eliminate the process of manually configuring infrastructure. When we talk about security automation, it can be tempting to focus on the future state of a solution, but that implies companies are ready to completely give up on their existing environments and investments.
That may not always be such a good idea.
In a service-based networking environment, it’s all about building security in depth. Firewall solutions still play an important role in modern datacenters, but that doesn’t mean updates and policy enforcement can’t be automated. It’s just that firewall policy changes should be triggered based on events, not tickets. Since we are keeping a dynamic record of service changes, it makes sense to treat those changes as events that have subsequent tasks that need to be performed. You may have heard of this concept being referred to as configuration management or Day 2 management, and it’s what tools like Consul-Terraform-Sync are designed to achieve.
»Moving Security Policies from Layer 3 to Layer 7
However, as users push services into newer, cloud-based environments, they may look to move away from some of their existing infrastructure and explore other security approaches, namely moving security policies from Layer 3 to Layer 7. Essentially, this means:
Enforcing traffic management policies based on service identity
Requiring mutual authentication
Encrypting communications in transit
If these approaches sound familiar, it’s because that’s exactly what a service mesh does. Which may explain why we’ve seen an explosion of new service mesh offerings. Service mesh is also becoming a common pattern for building zero trust security at the networking layer, meaning traffic inside your network is untrusted by default and must verify each connection to a service.
For more on service mesh, see For My Next Trick, I’ll Make a Service Mesh… Disappear! on The New Stack.
»Enabling Automation
The next core workflow for a service-based networking environment is enabling automation. One of the prevailing themes in modern infrastructure is the idea of being able to create templates for building repeatable environments in the cloud, also known as infrastructure as code. However, this concept has extended beyond the scope of just cloud compute resources. You can do just about anything with a Terraform provider these days, from ordering a pizza to creating a Spotify playlist.
But is this really automation? Templatizing environments and making them repeatable is great, but someone is ultimately on the other end, still triggering the changes. What about ongoing management? What about that Day 2 story mentioned earlier? Because applications are continually added or removed depending on the needs of the organization, modern networking is all about the ongoing management of a given environment. How do we apply that ongoing automation in our service-based networking story?
We have a couple of options, which align to the solutions outlined in the security section above. First, you can apply automation principles to key networking hardware used to regulate connections between services. In a more traditional environment, you might rely on something like an application delivery controller (ADC) to manage the rules for how services interact. However, these systems rely on IP addresses and are often manually configured. You could use a provisioning tool, but that solution just changes how you apply changes; it doesn’t remove the actual interaction piece.
Instead, the goal should be trying to use a system that dynamically changes as the services change. After all, you’re tracking the addition or removal of applications, why can’t those events trigger a provisioning change using the new service information that’s already been registered? At HashiCorp, we describe this concept as network infrastructure automation (NIA) and it’s something that Consul and Terraform, which also is open source, can achieve working together.
Additionally, as organizations shift towards newer environments, they often look to apply traffic management policies or automate connectivity between services based on their identity. Ideally, you’d set up rules that say which services are allowed to communicate with one another. Regardless of how many instances of each service are deployed, they would follow the same rules defined by the service identity. Sound familiar? It should, because once again it’s something that a service mesh can assist with.
At this point, you might be wondering why I haven’t just claimed that a service mesh solves everything. That’s because a service mesh is just a part of a broader solution. The shift to service-based networking is at the heart of how a service mesh operates, but a service mesh is not applicable to every environment. To outline a true solution to the workflow, we have to explore all the environments and application types a service-based network applies to, not just microservices and containers.
»Controlling Network Access
Now that we’ve covered the need to discover services in a dynamic fashion, applying security policies based on identity and events, and incorporating automation into our networking solutions, what’s left? None of these things really matter if end users and clients can’t actually access the network or the services running on it.
Thinking back to the way access used to be regulated with ADCs and firewalls, we quickly run into the same scaling and bottleneck issues identified earlier. Additionally, once you transition networking policies to a service-based networking solution, maintaining traditional networking technologies can actually hinder the ability to achieve consistency. Ideally, you want to apply the same service-based traffic management solution for managing north-south (ingress/egress) traffic as you do for east-west (service-to-service) traffic.
Kubernetes users reading this might think that there is already a solution to this challenge: ingress controllers. The general value proposition is that ingress controllers allow access to a Kubernetes cluster with the ability to apply certain traffic-management capabilities and security protocols. The benefit is that these controllers are treated like part of the Kubernetes environment and therefore are aware of other services in the cluster. However, these ingress controllers aren’t always as dynamic as users might desire. Oftentimes, they require longer rollout cycles to increase the number of replicas in a given cluster.
To address this dynamism challenge, the Kubernetes community introduced the Gateway API specification to enhance what was currently supported by ingress solutions. The Gateway API spec allows for more dynamic management of gateway services, routes, and is more closely aligned to a service mesh. That’s why we built the Consul API Gateway as an implementation of the Kubernetes Gateway API spec. This enables users to create a consistent control plane for all traffic management and access to the service mesh.
If you’re unfamiliar with the Kubernete Gateway API specification, it lets users deploy a dedicated gateway pod into a cluster, then dynamically apply routes via a custom resource definition. Using this model, Kubernetes users can deploy multiple versions of a gateway as needed within the cluster, and apply specific routing policies or listener protocols to each gateway instance. When combined with a service mesh, users can control traffic policies for both north-south and east-west traffic using a single solution and all based on service identities.
And, of course, the typical enterprise environment encompasses quite a bit more than just Kubernetes. Beyond Kubernetes, we need to apply these same policies and practices to all environments. Containers can be run by multiple orchestrators and some applications will never be containerized. We still need to have that central control plane for managing access to the network based on service identities. Doing this creates consistency across both cloud and non-cloud environments.
»Conclusion
As we’ve discussed, when addressing the modern networking challenge, users need to solve for four key workflows: discovering services, securing networks, automating networking tasks and controlling access. These four workflows comprise the core tenets of service-based networking.
It’s important to remember that the industry shift to service-based networking evolved over a number of years. That’s why service networking solutions continue to implement new functionality. Even as networking continues to evolve, however, the core goal remains: moving away from IP-based networking to service-based networking. Embracing this change allows networks to match the velocity of modern application delivery practices without compromising consistency in the way the networks are deployed and managed, or on security policies.
A version of this blog post was originally published on The New Stack.







