

This is a guest post from Jeff Silberman, a Solutions Architect at Portworx.
No one wants to manage storage, but high-value applications aren’t going to run without it. In an ideal world, storage would “just be there” without having to think about it --- or provision and manage it, right?
Portworx, a software-defined persistent storage solution for container workloads, provides a highly-available elastic data fabric. Portworx cloud native storage allows jobs to seamlessly run hyper-converged with the storage layer for best performance --- and also provides a rich spectrum of options for data availability.
Best of all, Portworx is incredibly DevOps friendly --- it’s simple to deploy and easy to consume.
»Storage on Demand
How easy? Well, what if your HashiCorp Nomad jobs could have storage on-demand, provisioned at runtime? Like this:
[...]
task "mysql-server" {
driver = "docker"
config {
image = "mysql/mysql-server:8.0"
port_map {
db = 3306
}
volumes = [
"name=mysqlvol,size=10,repl=3/:/var/lib/mysql",
]
volume_driver = "pxd"
}
[...]
Let’s look at what this means. As the mysql task is launched, the mysqlvol is dynamically created with a size of 10GB and a replication factor of 3, ensuring that data will be replicated on 3 different nodes.
No separate storage provisioning cycle needed, as container-granular virtual volumes are created on demand.
»What is Portworx and How Does It Work?
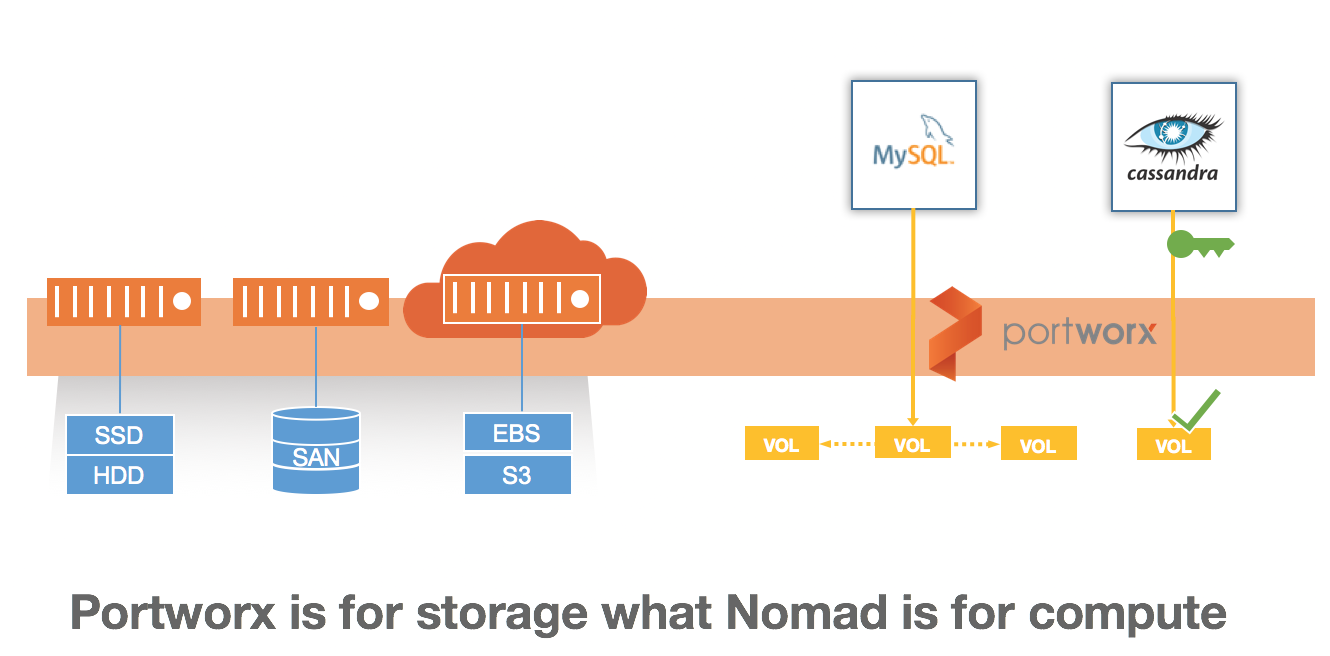
Portworx, under the hood, is a distributed block-device driver, delivered as a container and installed on Nomad clients that run stateful applications. And rather than just act as a connector to existing storage, Portworx runs hyper-converged with your existing nodes, offering thinly provisioned, container-granular virtual volumes (and snapshots) to applications running in containers. High-availability is guaranteed by replicating block-data to multiple nodes.
Portworx uses a kvdb, like Consul, for cluster/node topology discovery and control-path operations --- but not for any data-path operations, thereby addressing major concerns around both scalability and I/O performance.
As for Nomad, Portworx runs under the “system” scheduler, meaning that if new Nomad clients are added to the cluster, then Portworx will automatically run on those as well. The “system” scheduler aligns well with the notion of elastic Auto Scaling Groups (ASGs), allowing Portworx to automatically spin up on new client nodes, without manual installation.
Portworx runs on the Nomad clients (not the servers). Here are the relevant options needed on the Nomad clients:
client {
enabled = true
options {
"driver.raw_exec.enable" = "1"
"docker.privileged.enabled" = "true"
}
}
If you want to dig in yourself, it’s pretty easy. The Portworx doc site has been updated to include detailed (and easy) instructions for how to Install Portworx under Nomad.
»Infrastructure as Code
The “storage on demand” capabilities fall right inline with the HashiCorp Tao of codifying infrastructure. Storage requirements are an essential element of compute workloads, and even more so for persistent workloads. Provisioning storage until now has been an out-of-band process of submitting “tickets” --- an idea that is anathema to automation. Now with Portworx inline volume specification --- or “storage on demand”, the “storage provisioning cycle” is obsolete. Jobs provision storage on demand, as needed.
»Promote Efficient Workflows
Container-granular volume snapshots is a valuable enterprise feature that comes for free with Portworx. Snapshots are thin copy-on-write metadata markers that are created instantly and consume no space at creation time. Even better, snapshots are read/writeable. So for example, imagine wanting to create a carbon-copy for the output of your CICD master build cycle to pass on to multiple Jenkins slaves for processing in parallel. With Portworx, you could achieve exactly that by creating multiple volume snapshots, and having each Jenkins slave operate in parallel on its own carbon-copy. The increase in compute and storage efficiency is remarkable.
»Try it Yourself
DevOps simplicity has been a product foundation --- exemplified by the inline-volume creation capability. Nobody wants a steep/complex learning curve, which is why Portworx has made trial experimentation as easy and frictionless as possible: The product comes with a free 30-day trial license with all features enabled.
There are only two small requirements for trying this out yourself : Access to an external “kvdb”, like Consul. One or more unmounted/unformatted raw devices (partition or disk) on your host.
If you already have a working Nomad cluster that meets these requirements, then you can try this out immediately. Here’s a reference Nomad job file for launching Portworx.
If you don’t have a spare Nomad cluster to try, you can easily spin one up.
The Hashi-Porx AWS repository brings up a full cluster with Portworx/Nomad/Consul in AWS. And the Hashi-Porx Vagrant repository brings up a small Portworx cluster on Nomad and Consul both running in -dev mode.
»Less is More
Nothing could be more true, especially in the world of DevOps. The less you have to manage, the better off you’ll be. Portworx was specifically designed to enable DevOps automation, and to allow persistent storage for containers so that high-value stateful applications --- like databases --- can run containerized.
We are very excited to be contributing to the HashiCorp Nomad ecosystem, to better enable meaningful automated workflows --- with less actual work.






